JDK1.7 版本
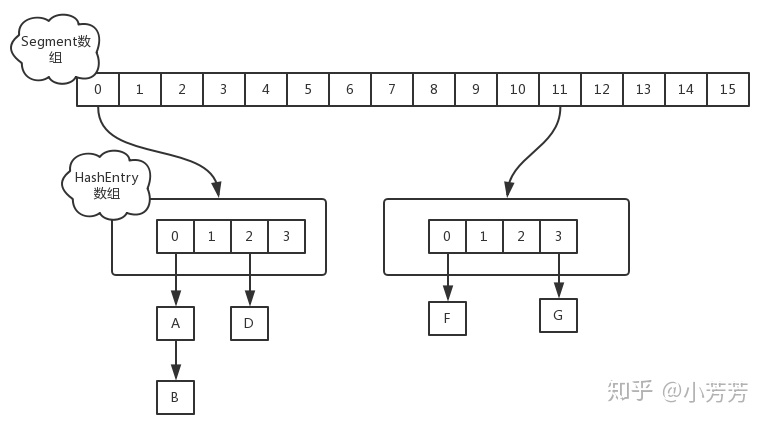
ConcurrentHashMap 的数据结构是由一个 Segment 数组和多个 HashEntry 组成。简单理解就是ConcurrentHashMap 是一个 Segment 数组,Segment 通过继承 ReentrantLock 来进行加锁,所以每次需要加锁的操作锁住的是一个 Segment,这样只要保证每个 Segment 是线程安全的,也就实现了全局的线程安全。
如何计算 ConcurrentHashMap Size
由上面分析可知,ConcurrentHashMap 更适合作为线程安全的 Map。在实际的项目过程中,我们通常需要获取集合类的长度, 那么计算 ConcurrentHashMap 的元素大小就是一个有趣的问题,因为他是并发操作的,就是在你计算 size 的时候,它还在并发的插入数据,可能会导致你计算出来的 size 和你实际的 size 有差距
public int size() { final Segment<K,V>[] segments = this.segments; int size; boolean overflow; // true if size overflows 32 bits long sum; // sum of modCounts long last = 0L; // previous sum int retries = -1; // first iteration isn't retry try { for (;;) { if (retries++ == RETRIES_BEFORE_LOCK) { for (int j = 0; j < segments.length; ++j) ensureSegment(j).lock(); // force creation } sum = 0L; size = 0; overflow = false; for (int j = 0; j < segments.length; ++j) { Segment<K,V> seg = segmentAt(segments, j); if (seg != null) { sum += seg.modCount; int c = seg.count; if (c < 0 || (size += c) < 0) overflow = true; } } if (sum == last) break; last = sum; } } finally { if (retries > RETRIES_BEFORE_LOCK) { for (int j = 0; j < segments.length; ++j) segmentAt(segments, j).unlock(); } } return overflow ? Integer.MAX_VALUE : size; }
如何计算 ConcurrentHashMap Size
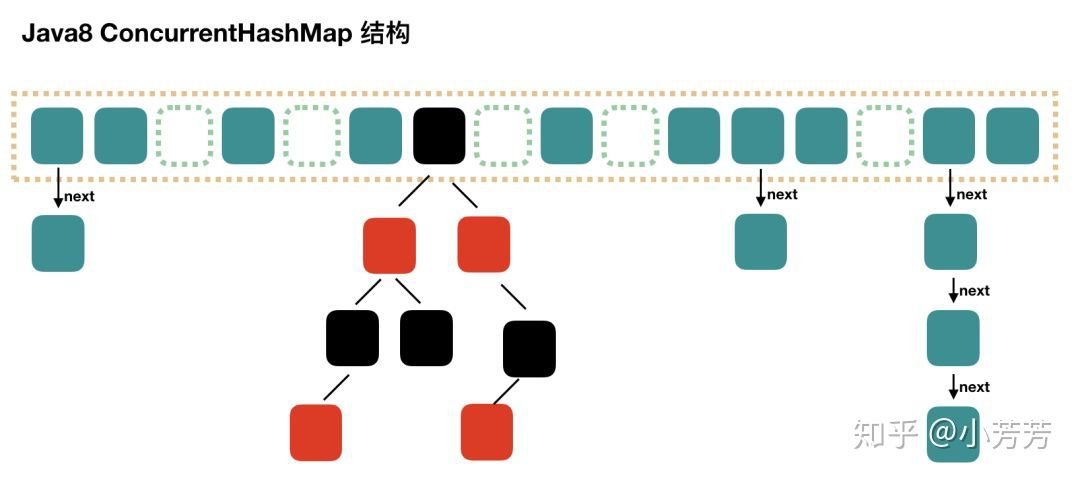
JDK1.8 实现相比 JDK 1.7 简单很多,只有一种方案,我们直接看 size() 代码:
public int size() { long n = sumCount(); return ((n < 0L) ? 0 : (n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE : (int)n); }
最大值是 Integer 类型的最大值,但是 Map 的 size 可能超过 MAX_VALUE, 所以还有一个方法 mappingCount(),JDK 的建议使用 mappingCount() 而不是size()。mappingCount() 的代码如下:
public long mappingCount() { long n = sumCount(); return (n < 0L) ? 0L : n; // ignore transient negative values }
以上可以看出,无论是 size() 还是 mappingCount(), 计算大小的核心方法都是 sumCount()。sumCount() 的代码如下:
final long sumCount() { CounterCell[] as = counterCells; CounterCell a; long sum = baseCount; if (as != null) { for (int i = 0; i < as.length; ++i) { if ((a = as[i]) != null) sum += a.value; } } return sum; }
分析一下 sumCount() 代码。ConcurrentHashMap 提供了 baseCount、counterCells 两个辅助变量和一个 CounterCell 辅助内部类。sumCount() 就是迭代 counterCells 来统计 sum 的过程。
put 操作时,肯定会影响 size(),在 put() 方法最后会调用 addCount() 方法。
addCount() 代码如下:
如果 counterCells == null, 则对 baseCount 做 CAS 自增操作。
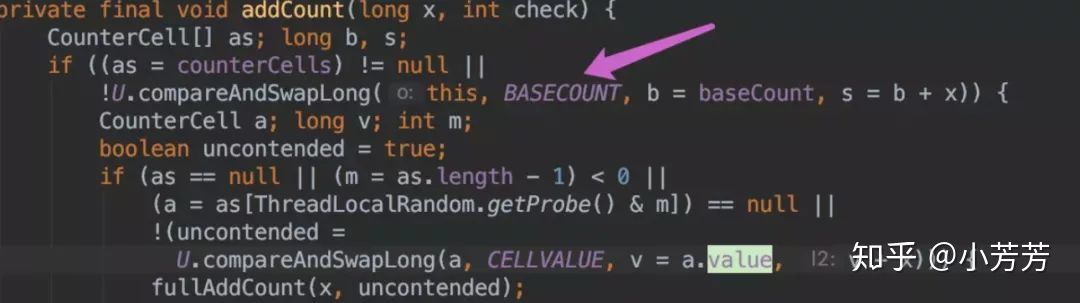
如果并发导致 baseCount CAS 失败了使用 counterCells。
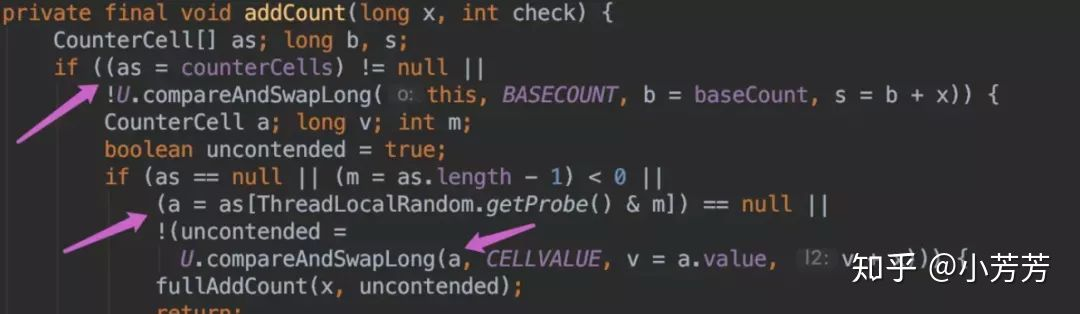
如果counterCells CAS 失败了,在 fullAddCount 方法中,会继续死循环操作,直到成功。
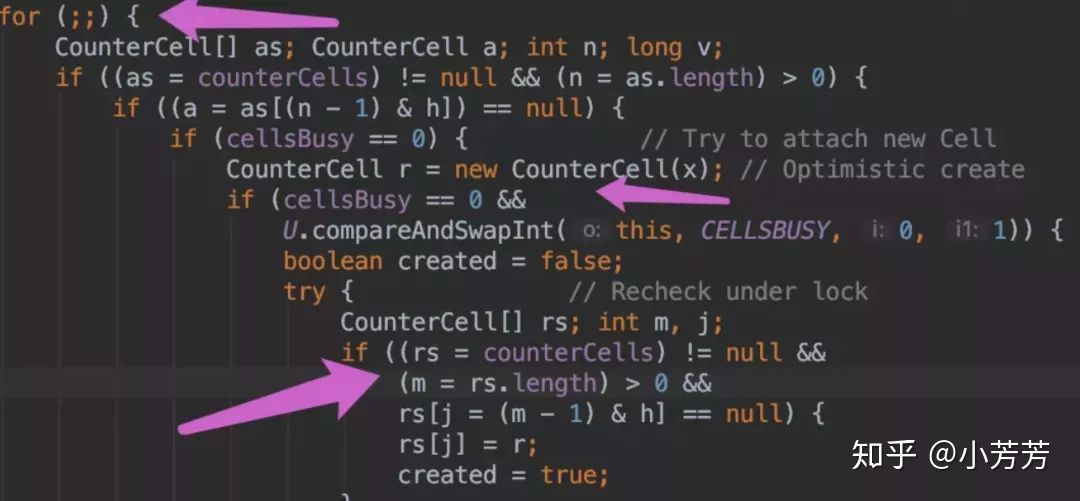
JDK1.8 size 是通过对 baseCount 和 counterCell(专门处理CAS失败的操作,最终都是成功的因为循环CAS操作),最终通过 baseCount 和 遍历 CounterCell 数组得出 size。