这里我们对springbatch做一个比较深入的学习例子,解压文件,读取文件内容过滤写入到数据库中。如果你掉进了黑暗里,你能做的,不过是静心等待,直到你的双眼适应黑暗。
springbatch的使用案例
首先,我们来列举一下spring batch里面所涉及到的概念。
1、Job repository An infrastructure component that persists job execution metadata 2、Job launcher An infrastructure component that starts job executions 3、Job An application component that represents a batch process 4、Step A phase in a job; a job is a sequence of steps 5、Tasklet A transactional, potentially repeatable process occurring in a step 6、Item A record read from or written to a data source 7、Chunk A list of items of a given size 8、Item reader A component responsible for reading items from a data source 9、Item processor A component responsible for processing (transforming, validating, or filtering) a read item before it’s written 10、Item writer A component responsible for writing a chunk to a data source
我们的项目是基于上篇博客的,具体的可以参考博客:springbatch---->springbatch的使用(一)。流程:将得到的zip文件解压成txt文件,根据里面的信息。我们过滤到年龄大于30的数据,并把过滤后的数据按格式存放到数据库中。以下我们只列出新增或者修改的文件内容。
一、关于xml文件的修改,增加一个job.xml文件和修改batch.xml文件
- batch.xml文件增加内容:
<!-- 读取文件写入到数据库的job --> <job id="readFlatFileJob"> <step id="decompress" next="readWriter"> <tasklet ref="decompressTasklet"/> </step> <step id="readWriter" next="clean"> <tasklet> <chunk reader="reader" writer="writer" commit-interval="100" processor="processor"/> </tasklet> </step> <step id="clean"> <tasklet ref="cleanTasklet"/> </step> </job>
关于commit-interval:Number of items to process before issuing a commit. When the number of items read reaches the commit interval number, the entire corresponding chunk is written out through the item writer and the transaction is committed.
- 新增的job.xml文件内容如下:
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd"> <!-- 对压缩文件进行解压 --> <bean id="decompressTasklet" class="spring.batch.readFile.DecompressTasklet"> <property name="inputResource" value="file:file/file.zip"/> <property name="targetDirectory" value="file"/> <property name="targetFile" value="file.txt"/> </bean> <!-- 读取文本文件 --> <bean id="reader" class="org.springframework.batch.item.file.FlatFileItemReader"> <property name="lineMapper" ref="lineMapper"/> <property name="linesToSkip" value="1"/> <!-- 跳过第一行,也就是从第二行开始读 --> <property name="resource" value="file:file/file.txt"/> </bean> <!-- 对读取的内容做过滤处理 --> <bean id="processor" class="spring.batch.readFile.FileProcessor"/> <!-- 将读取的内容写到数据库中 --> <bean id="writer" class="spring.batch.readFile.FileWriter"> <constructor-arg ref="dataSource"/> </bean> <!-- 清除压缩文件--> <bean id="cleanTasklet" class="spring.batch.readFile.FileCleanTasklet"> <property name="resource" value="file:file/file.zip"/> </bean> <!-- 对文件里面的数据进行|分割,映射成一个类 --> <bean id="lineMapper" class="org.springframework.batch.item.file.mapping.DefaultLineMapper"> <property name="lineTokenizer" ref="delimitedLineTokenizer"/> <property name="fieldSetMapper"> <bean class="spring.batch.readFile.ReadFileMapper"/> </property> </bean> <bean id="delimitedLineTokenizer" class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"> <constructor-arg name="delimiter" value="|"/> </bean> <!-- 简单的数据源配置 --> <bean id="dataSource" class="org.springframework.jdbc.datasource.DriverManagerDataSource"> <property name="driverClassName" value="com.mysql.jdbc.Driver"/> <property name="url" value="jdbc:mysql://127.0.0.1:3306/csiilearn"/> <property name="username" value="root"/> <property name="password" value="*****"/> </bean> </beans>
其实关于有格式的文件的读写,springbatch为我们提供了FlatFileItemWriter和FlatFileItemReader类。我们可以直接使用,只需要配置它的属性就行。
二、新增加的java类,如下所示
- DecompressTasklet:对zip文件进行解压
package spring.batch.readFile; import org.apache.commons.io.FileUtils; import org.apache.commons.io.IOUtils; import org.springframework.batch.core.StepContribution; import org.springframework.batch.core.scope.context.ChunkContext; import org.springframework.batch.core.step.tasklet.Tasklet; import org.springframework.batch.repeat.RepeatStatus; import org.springframework.core.io.Resource; import java.io.BufferedInputStream; import java.io.BufferedOutputStream; import java.io.File; import java.io.FileOutputStream; import java.util.zip.ZipInputStream; /** * @Author: huhx * @Date: 2017-11-01 上午 9:39 */ public class DecompressTasklet implements Tasklet { private Resource inputResource; private String targetDirectory; private String targetFile; @Override public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception { System.out.println("file path: " + inputResource.getFile().getAbsolutePath()); ZipInputStream zis = new ZipInputStream( new BufferedInputStream( inputResource.getInputStream())); File targetDirectoryAsFile = new File(targetDirectory); if (!targetDirectoryAsFile.exists()) { FileUtils.forceMkdir(targetDirectoryAsFile); } File target = new File(targetDirectory, targetFile); BufferedOutputStream dest = null; while (zis.getNextEntry() != null) { if (!target.exists()) { target.createNewFile(); } FileOutputStream fos = new FileOutputStream(target); dest = new BufferedOutputStream(fos); IOUtils.copy(zis, dest); dest.flush(); dest.close(); } zis.close(); if (!target.exists()) { throw new IllegalStateException("Could not decompress anything from the archive!"); } return RepeatStatus.FINISHED; } public void setInputResource(Resource inputResource) { this.inputResource = inputResource; } public void setTargetDirectory(String targetDirectory) { this.targetDirectory = targetDirectory; } public void setTargetFile(String targetFile) { this.targetFile = targetFile; } }
- People:数据库映射的javaBean类
public class People implements Serializable { private String username; private int age; private String address; private Date birthday; ..get...set... }
- ReadFileMapper:读取文件字段的映射
package spring.batch.readFile; import org.springframework.batch.item.file.mapping.FieldSetMapper; import org.springframework.batch.item.file.transform.FieldSet; import org.springframework.validation.BindException; /** * @Author: huhx * @Date: 2017-11-01 上午 10:11 */ public class ReadFileMapper implements FieldSetMapper<People> { @Override public People mapFieldSet(FieldSet fieldSet) throws BindException { People people = new People(); people.setUsername(fieldSet.readString(0)); people.setAge(fieldSet.readInt(1)); people.setAddress(fieldSet.readString(2)); people.setBirthday(fieldSet.readDate(3)); return people; } }
- FileProcessor:对读取的数据做进一步的处理,这里我们是过滤操作
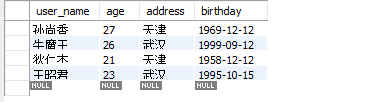
package spring.batch.readFile; import org.springframework.batch.item.ItemProcessor; /** * @Author: huhx * @Date: 2017-11-01 上午 9:43 */ public class FileProcessor implements ItemProcessor<People, People> { @Override public People process(People item) throws Exception { return needsToBeFiltered(item) ? null : item; } private boolean needsToBeFiltered(People item) { int age = item.getAge(); return age > 30 ? true : false; } }
- FileWriter:对最终过滤后的数据写入数据库中
package spring.batch.readFile; import org.springframework.batch.item.ItemWriter; import org.springframework.jdbc.core.JdbcTemplate; import javax.sql.DataSource; import java.util.List; /** * @Author: huhx * @Date: 2017-11-01 上午 9:42 */ public class FileWriter implements ItemWriter<People> { private static final String INSERT_PRODUCT = "INSERT INTO batch_user (user_name, age, address, birthday) VALUES(?, ?, ?, ?)"; private JdbcTemplate jdbcTemplate; public FileWriter(DataSource dataSource) { this.jdbcTemplate = new JdbcTemplate(dataSource); } @Override public void write(List<? extends People> items) throws Exception { for (People people : items) { jdbcTemplate.update(INSERT_PRODUCT, people.getUsername(), people.getAge(), people.getAddress(), people.getBirthday()); } } }
- FileCleanTasklet:做流程最后的清理处理,删除zip文件
package spring.batch.readFile; import org.springframework.batch.core.StepContribution; import org.springframework.batch.core.scope.context.ChunkContext; import org.springframework.batch.core.step.tasklet.Tasklet; import org.springframework.batch.repeat.RepeatStatus; import org.springframework.core.io.Resource; import java.io.File; /** * @Author: huhx * @Date: 2017-11-01 上午 9:44 */ public class FileCleanTasklet implements Tasklet { private Resource resource; public void setResource(Resource resource) { this.resource = resource; } @Override public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception { File file = resource.getFile(); file.deleteOnExit(); return RepeatStatus.FINISHED; } }
三、修改JobLaunch.java文件里面的内容
Job job = (Job) context.getBean("readFlatFileJob");
- zip解压后的文件内容:
姓名|年龄|地址|生日 李元芳|32|黄冈|1985-12-15 王昭君|23|武汉|1995-10-15 狄仁杰|21|天津|1958-12-12 孙悟空|34|黄冈|1985-12-25 牛魔王|26|武汉|1999-09-12 孙尚香|27|天津|1969-12-12
- 运行后的数据库batch_user表的数据: