(一)为什么要实现读写分离?
为了服务器承载更多的用户?提升了网站的响应速度?分摊数据库服务器的压力?就是为了双机热备又不想浪费备份服务器?上面这些回答,我认为都不是错误的,但也都不是完全正确的。「读写分离」并不是多么神奇的东西,也带不来多么大的性能提升,也许更多的作用的就是数据安全的备份吧。从一个库到读写分离,从理论上对服务器压力来说是会带来一倍的性能提升,但你仔细思考一下,你的应用服务器真的很需要这一倍的提升么?那倒不如你去试着在服务器使用一下缓存系统,如 Memcached、Redis 这些分布式缓存,那性能可能是几十倍的提升。而且,在服务器硬件异常强悍及性能廉价的今天,完全更没必要了,所以,在今天,我认为它更多的职责就是为了数据安全而设计的,同时又提升了一些性能,这样也挺好。
总结:分摊数据库服务器的压力,并保证数据库数据安全。
(二)如何实现读写分离?
读写分离方式很简单,就是在你读数据时去连接从库,在你写数据的时候去连接主库,具体代码实现当然就是连接时候去操作了,这没什么难度,在代码里写就是了,但是这样源程序就要被改动了,假设一个场景,我们已经部署好了数据库服务器,这个要实现主从,当然这种方法就有限制了。
巧妙的使用AOP就可以实现: AOP 可以在方法开始执行前后插入执行我们想要的代码,那这样,我们可以在执行数据库操作前根据业务来动态切换数据源,这种方式首先不需要在业务代码中去做切换,二是可能以后我们不需要读写分离了,把 AOP 切换的代码去掉就行了,三是可能就是拓展性更强。
(三)主从数据库如何保证数据一致性?
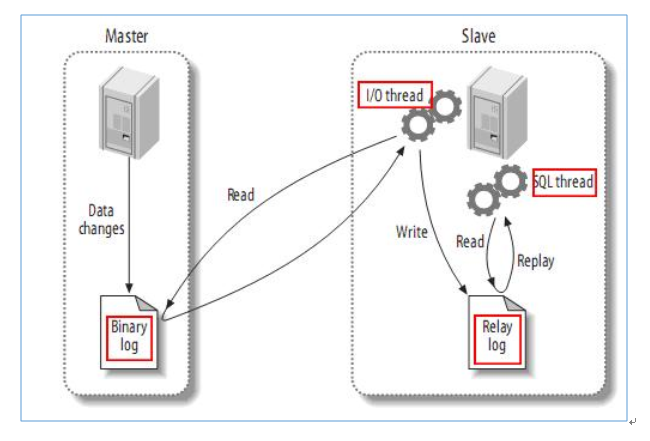
数据的一致性通过主从复制实现,以mysql主(称master)从(称slave)复制的原理为例:
1、master将数据改变记录到二进制日志(binary log)中,也即是配置文件log-bin指定的文件(这些记录叫做二进制日志事件,binary log events);
2、slave将master的binary logevents拷贝到它的中继日志(relay log);
3、slave重做中继日志中的事件,将改变反映它自己的数据(数据重演);
(四)主从配置需要注意的地方
1、主DB server和从DB server数据库的版本一致;
2、主DB server和从DB server数据库数据一致,这里就可以把主的备份在从上还原,也可以直接将主的数据目录拷贝到从的相应数据目录;
3、主DB server开启二进制日志,主DB server和从DB server的server_id都必须唯一;
(五)一主一从与一主多从的区别以及实现
我的上一篇文章主要讨论一主多从,而且只是给了实际应用中的实现方向,自己实现具体的这个可以参考链接:
https://blog.csdn.net/zbw18297786698/article/details/54343188