【摘要】Sqoop是一种用于在Apache Hadoop和结构化数据存储(如关系数据库)之间高效传输批量数据的工具 。本文将简单介绍Sqoop作业执行时相关的类及方法,并将该过程与MapReduce的执行结合,分析数据如何从源端迁移到目的端。
Sqoop作业执行过程
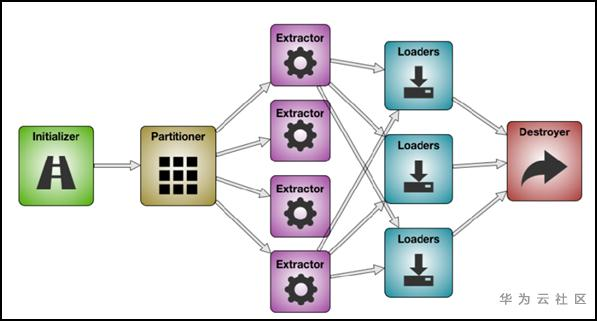
抛开MR的执行过程,Sqoop执行时用到的关键类总共有5个,Initializer、Partitioner、Extractor、Loader、Destroyer。执行流程如下图所示
-
Initializer:初始化阶段,源数据校验,参数初始化等工作;
-
Partitioner:源数据分片,根据作业并发数来决定源数据要切分多少片;
-
Extractor:开启extractor线程,根据用户配置从内存中构造数据写入队列;
-
Loader:开启loader线程,从队列中读取数据并抛出;
-
Destroyer:资源回收,断开sqoop与数据源的连接,并释放资源;
因此,每次新建一个连接器都要实现上述5个类。
Initializer
Initializer是在sqoop任务提交到MR之前被调用,主要是做迁移前的准备,例如连接数据源,创建临时表,添加依赖的jar包等。它是sqoop作业生命周期的第一步,主要API如下
public abstract void initialize(InitializerContext context, LinkConfiguration linkConfiguration,JobConfiguration jobConfiguration); public List<String> getJars(InitializerContext context, LinkConfiguration linkConfiguration,JobConfiguration jobConfiguration){ return new LinkedList<String>(); } public abstract Schema getSchema(InitializerContext context, LinkConfiguration linkConfiguration,JobConfiguration jobConfiguration) { return new NullSchema(); }
其中getSchema()方法被From或者To端的connector在提取或者载入数据时用来匹配数据。例如,一个GenericJdbcConnector会调用它获取源端Mysql的数据库名,表名,表中的字段信息等。
Destroyer
Destroyer 是在作业执行结束后被实例化,这是Sqoop作业的最后一步。清理任务,删除临时表,关闭连接器等。
public abstract void destroy(DestroyerContext context, LinkConfiguration linkConfiguration,JobConfiguration jobConfiguration);
Partitioner
Partitioner创建分区Partition,Sqoop默认创建10个分片,主要API如下
public abstract List<Partition> getPartitions(PartitionerContext context, LinkConfiguration linkConfiguration, FromJobConfiguration jobConfiguration);
Partition类中实现了readFields()方法和write()方法,方便读写
public abstract class Partition { public abstract void readFields(DataInput in) throws IOException; public abstract void write(DataOutput out) throws IOException; public abstract String toString(); }
Extractor
Extractor类根据分片partition和配置信息从源端提取数据,写入SqoopMapDataWriter中,SqoopMapDataWriter是SqoopMapper的内部类它继承了DataWriter类。此外它打包了SqoopWritable类,以中间数据格式保存从源端读取到的数据。
public abstract void extract(ExtractorContext context, LinkConfiguration linkConfiguration, JobConfiguration jobConfiguration, SqoopPartition partition);
该方法内部核心代码如下
while (resultSet.next()) { ... context.getDataWriter().writeArrayRecord(array); ... }
Loader
loader从源端接受数据,并将其载入目的端,它必须实现如下接口
public abstract void load(LoaderContext context, ConnectionConfiguration connectionConfiguration, JobConfiguration jobConfiguration) throws Exception; load方法从SqoopOutputFormatDataReader中读取,它读取“中间数据格式表示形式” _中的数据并将其加载到数据源。此外Loader必须迭代的调用DataReader()直到它读完。 while ((array = context.getDataReader().readArrayRecord()) != null) { ... }
MapReduce执行过程
上一节避开MR执行过程,仅仅从Extractor和Loader过程描述迁移过程。下面将结合MR的执行过程详细的介绍一个Sqoop迁移作业流程。
初始化
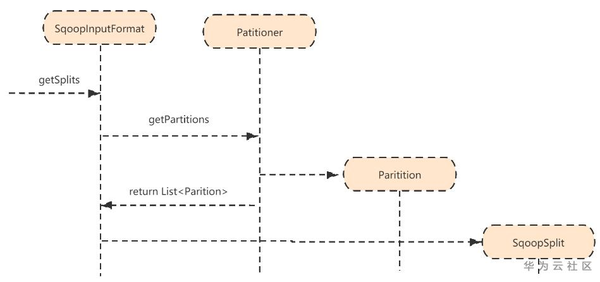
1)作业初始化阶段,SqoopInputFormat读取给源端数据分片的过程
-
SqoopInputFormat的getSplits方法会调用Partitioner类的getPartitions方法
-
将返回的Partition列表包装到SqoopSplit中;
-
默认分片个数为10
这里每个Partition分片会交给一个Mapper执行。每个Mapper分别启动一个extractor线程和Loader线程迁移数据。
Mapper
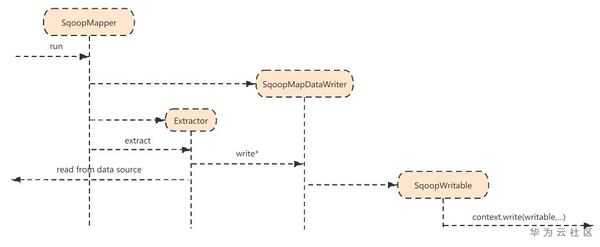
2)作业执行阶段的Mapper过程
-
SqoopMapper包含了一个SqoopMapDataWriter类,
-
Mapper的run()调用Extractor.extract方法,该方法迭代的获取源端数据再调用DataWriter写入Context中
private Class SqoopMapDataWriter extends DataWriter { ... private void writeContent() { ... context.wirte(writable, NullWritable.get()); // 这里的writable 是SqoopWritable的一个对象 ... } ... }
注意:这里的Context中存的是KV对,K是SqoopWritable,而V仅是一个空的Writable对象。SqoopWritable中实现了write和readField,用于序列化和反序列化。
Reducer
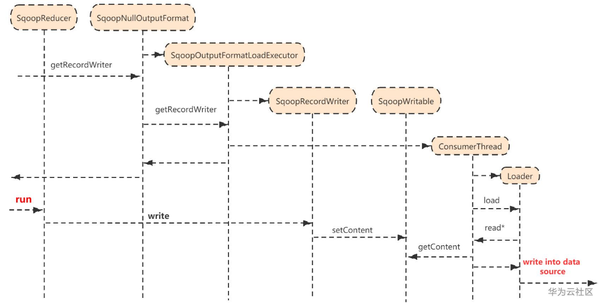
3)作业执行阶段的Reduce过程,
-
SqoopOutputFormatLoadExecutor包装了SqoopOuputFormatDataReader,SqoopRecordWriter, ConsumerThread三个内部类;
-
SqoopNullOutputFormat调用getRecordWriter时创建一个线程:ConsumerThread,代码如下
public RecordWriter<SqoopWritable, NullWritable> getRecordWriter() { executorService = Executors.newSingleThreadExecutor(...); consumerFuture = executorService.submit(new ConsumerThread(context)); return writer; }
-
ConsumerThread集成了Runnable接口,线程内部调用Loader.load(...)方法,该方法用DataReader迭代的从Context中读取出SqoopWritable,并将其写入一个中间数据格式再写入目的端数据库中。
private class ConsumerThread implements Runnable { ... public void run() { ... Loader.load(loaderContext, connectorLinkConfig, ConnectorToJobConfig); ... } ... }
注意:
-
再本地模式下,Sqoop提交任务时没有设置SqoopReducer.class,MR会调用一个默认的reducer.class。
-
setContent就是SqoopRecordWriter.write(...),它将SqoopWritable反序列化后存入中间存储格式中,即IntermediateDataFormat。与之对应,getContent就是从该中间存储格式中读取数据。
-
Sqoop定义了一个可插拔的中间数据格式抽象类,IntermediateDataFormat类,SqoopWritable打包了这个抽象类用来保存中间数据。
以上即为Sqoop作业执行时相关的类及方法内容,希望对大家在进行数据迁移过程中有所帮助。
