HDFS是Hadoop应用程序使用的主要分布式存储。HDFS集群主要由管理文件系统元数据的NameNode和存储实际数据的DataNodes组成,HDFS架构图描述了NameNode,DataNode和客户端之间的基本交互。客户端联系NameNode进行文件元数据或文件修改,并直接使用DataNodes执行实际的文件I / O。
Hadoop支持shell命令直接与HDFS进行交互,同时也支持JAVA API对HDFS的操作,例如,文件的创建、删除、上传、下载、重命名等。
HDFS中的文件操作主要涉及以下几个类:
Configuration:提供对配置参数的访问
FileSystem:文件系统对象
Path:在FileSystem中命名文件或目录。 路径字符串使用斜杠作为目录分隔符。 如果以斜线开始,路径字符串是绝对的
FSDataInputStream和FSDataOutputStream:这两个类分别是HDFS中的输入和输出流
下面是JAVA API对HDFS的操作过程:
1.项目结构
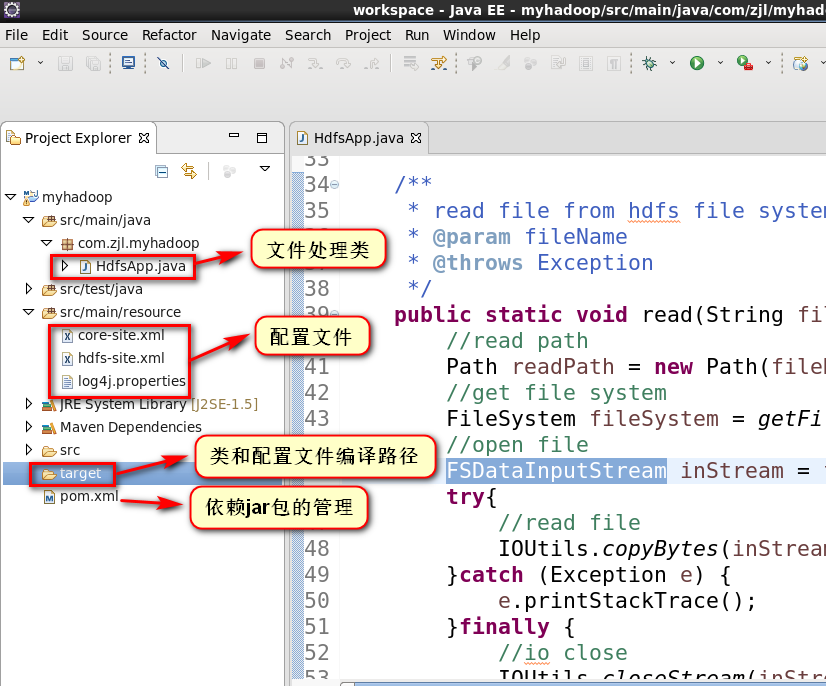
2.pom.xml配置


1 <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" 2 xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> 3 <modelVersion>4.0.0</modelVersion> 4 5 <groupId>com.zjl</groupId> 6 <artifactId>myhadoop</artifactId> 7 <version>0.0.1-SNAPSHOT</version> 8 <packaging>jar</packaging> 9 10 <name>myhadoop</name> 11 <url>http://maven.apache.org</url> 12 13 <properties> 14 <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> 15 <hadoop.version>2.5.0</hadoop.version> 16 </properties> 17 18 <dependencies> 19 <dependency> 20 <groupId>org.apache.hadoop</groupId> 21 <artifactId>hadoop-client</artifactId> 22 <version>${hadoop.version}</version> 23 </dependency> 24 <dependency> 25 <groupId>junit</groupId> 26 <artifactId>junit</artifactId> 27 <version>3.8.1</version> 28 </dependency> 29 </dependencies> 30 </project>
3.拷贝hadoop安装目录下与HDFS相关的配置(core-site.xml,hdfs-site.xml,log4j.properties)到resource目录下
1 [hadoop@hadoop01 ~]$ cd /opt/modules/hadoop-2.6.5/etc/hadoop/ 2 [hadoop@hadoop01 hadoop]$ cp core-site.xml hdfs-site.xml log4j.properties /opt/tools/workspace/myhadoop/src/main/resource/ 3 [hadoop@hadoop01 hadoop]$
(1)core-site.xml
1 <?xml version="1.0" encoding="UTF-8"?> 2 <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> 3 <!-- 4 Licensed under the Apache License, Version 2.0 (the "License"); 5 you may not use this file except in compliance with the License. 6 You may obtain a copy of the License at 7 8 http://www.apache.org/licenses/LICENSE-2.0 9 10 Unless required by applicable law or agreed to in writing, software 11 distributed under the License is distributed on an "AS IS" BASIS, 12 WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. 13 See the License for the specific language governing permissions and 14 limitations under the License. See accompanying LICENSE file. 15 --> 16 17 <!-- Put site-specific property overrides in this file. --> 18 19 <configuration> 20 <property> 21 <name>fs.defaultFS</name> 22 <!-- 如果没有配置,默认会从本地文件系统读取数据 --> 23 <value>hdfs://hadoop01.zjl.com:9000</value> 24 </property> 25 <property> 26 <name>hadoop.tmp.dir</name> 27 <!-- hadoop文件系统依赖的基础配置,很多路径都依赖它。如果hdfs-site.xml中不配置namenode和datanode的存放位置,默认就放在这个路径中 --> 28 <value>/opt/modules/hadoop-2.6.5/data/tmp</value> 29 </property> 30 </configuration>
(2)hdfs-site.xml
1 <?xml version="1.0" encoding="UTF-8"?> 2 <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> 3 <!-- 4 Licensed under the Apache License, Version 2.0 (the "License"); 5 you may not use this file except in compliance with the License. 6 You may obtain a copy of the License at 7 8 http://www.apache.org/licenses/LICENSE-2.0 9 10 Unless required by applicable law or agreed to in writing, software 11 distributed under the License is distributed on an "AS IS" BASIS, 12 WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. 13 See the License for the specific language governing permissions and 14 limitations under the License. See accompanying LICENSE file. 15 --> 16 17 <!-- Put site-specific property overrides in this file. --> 18 19 <configuration> 20 <property> 21 <!-- default value 3 --> 22 <name>dfs.replication</name> 23 <value>1</value> 24 </property> 25 </configuration>
(3)采用默认即可,打印hadoop的日志信息所需的配置文件。如果不配置,运行程序时eclipse控制台会提示警告
4.启动hadoop的hdfs的守护进程,并在hdfs文件系统中创建文件(文件共步骤5中java程序读取)
1 [hadoop@hadoop01 hadoop]$ cd /opt/modules/hadoop-2.6.5/ 2 [hadoop@hadoop01 hadoop-2.6.5]$ sbin/start-dfs.sh 3 17/06/21 22:59:32 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 4 Starting namenodes on [hadoop01.zjl.com] 5 hadoop01.zjl.com: starting namenode, logging to /opt/modules/hadoop-2.6.5/logs/hadoop-hadoop-namenode-hadoop01.zjl.com.out 6 hadoop01.zjl.com: starting datanode, logging to /opt/modules/hadoop-2.6.5/logs/hadoop-hadoop-datanode-hadoop01.zjl.com.out 7 Starting secondary namenodes [0.0.0.0] 8 0.0.0.0: starting secondarynamenode, logging to /opt/modules/hadoop-2.6.5/logs/hadoop-hadoop-secondarynamenode-hadoop01.zjl.com.out 9 17/06/21 23:00:06 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 10 [hadoop@hadoop01 hadoop-2.6.5]$ jps 11 3987 NameNode 12 4377 Jps 13 4265 SecondaryNameNode 14 4076 DataNode 15 3135 org.eclipse.equinox.launcher_1.3.201.v20161025-1711.jar 16 [hadoop@hadoop01 hadoop-2.6.5]$ bin/hdfs dfs -mkdir -p /user/hadoop/mapreduce/wordcount/input 17 17/06/21 23:07:21 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 18 [hadoop@hadoop01 hadoop-2.6.5]$ cat wcinput/wc.input 19 hadoop yarn 20 hadoop mapreduce 21 hadoop hdfs 22 yarn nodemanager 23 hadoop resourcemanager 24 [hadoop@hadoop01 hadoop-2.6.5]$ bin/hdfs dfs -put wcinput/wc.input /user/hadoop/mapreduce/wordcount/input/ 25 17/06/21 23:20:40 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 26 [hadoop@hadoop01 hadoop-2.6.5]$
5.java代码
1 package com.zjl.myhadoop; 2 3 import java.io.File; 4 import java.io.FileInputStream; 5 6 import org.apache.hadoop.conf.Configuration; 7 import org.apache.hadoop.fs.FSDataInputStream; 8 import org.apache.hadoop.fs.FSDataOutputStream; 9 import org.apache.hadoop.fs.FileSystem; 10 import org.apache.hadoop.fs.Path; 11 import org.apache.hadoop.io.IOUtils; 12 13 /** 14 * 15 * @author hadoop 16 * 17 */ 18 public class HdfsApp { 19 20 /** 21 * get file system 22 * @return 23 * @throws Exception 24 */ 25 public static FileSystem getFileSystem() throws Exception{ 26 //read configuration 27 //core-site.xml,core-default-site.xml,hdfs-site.xml,hdfs-default-site.xml 28 Configuration conf = new Configuration(); 29 //create file system 30 FileSystem fileSystem = FileSystem.get(conf); 31 return fileSystem; 32 } 33 34 /** 35 * read file from hdfs file system,output to the console 36 * @param fileName 37 * @throws Exception 38 */ 39 public static void read(String fileName) throws Exception { 40 //read path 41 Path readPath = new Path(fileName); 42 //get file system 43 FileSystem fileSystem = getFileSystem(); 44 //open file 45 FSDataInputStream inStream = fileSystem.open(readPath); 46 try{ 47 //read file 48 IOUtils.copyBytes(inStream, System.out, 4096, false); 49 }catch (Exception e) { 50 e.printStackTrace(); 51 }finally { 52 //io close 53 IOUtils.closeStream(inStream); 54 } 55 } 56 57 public static void upload(String inFileName, String outFileName) throws Exception { 58 59 //file input stream,local file 60 FileInputStream inStream = new FileInputStream(new File(inFileName)); 61 62 //get file system 63 FileSystem fileSystem = getFileSystem(); 64 //write path,hdfs file system 65 Path writePath = new Path(outFileName); 66 67 //output stream 68 FSDataOutputStream outStream = fileSystem.create(writePath); 69 try{ 70 //write file 71 IOUtils.copyBytes(inStream, outStream, 4096, false); 72 }catch (Exception e) { 73 e.printStackTrace(); 74 }finally { 75 //io close 76 IOUtils.closeStream(inStream); 77 IOUtils.closeStream(outStream); 78 } 79 } 80 public static void main( String[] args ) throws Exception { 81 //1.read file from hdfs to console 82 // String fileName = "/user/hadoop/mapreduce/wordcount/input/wc.input"; 83 // read(fileName); 84 85 //2.upload file from local file system to hdfs file system 86 //file input stream,local file 87 String inFileName = "/opt/modules/hadoop-2.6.5/wcinput/wc.input"; 88 String outFileName = "/user/hadoop/put-wc.input"; 89 upload(inFileName, outFileName); 90 } 91 }
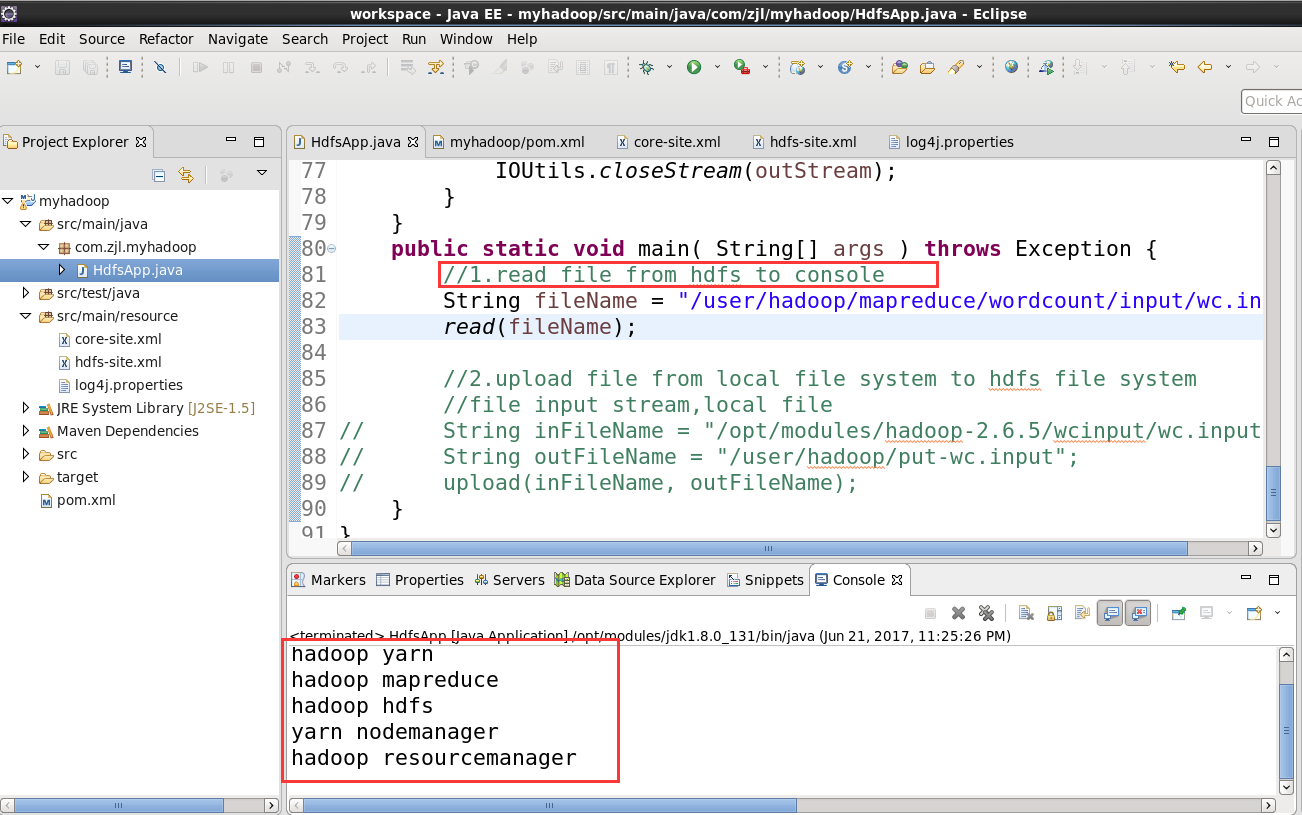
6.调用方法 read(fileName)
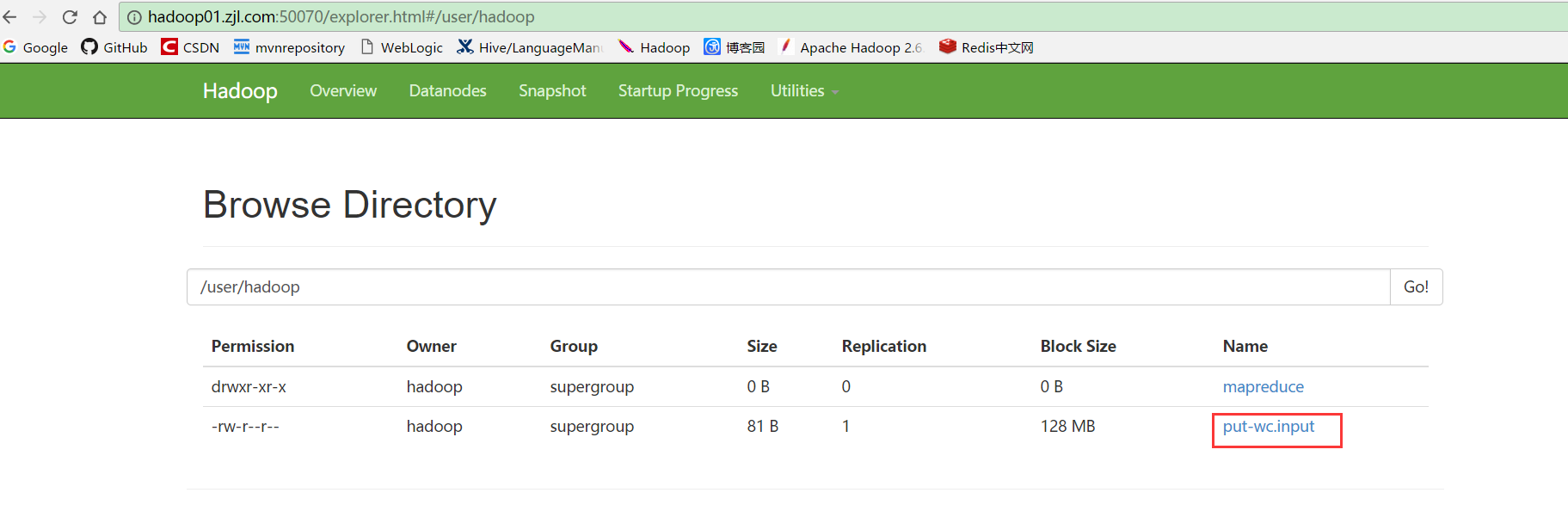
7.进入hdfs文件系统查看/user/hadoop目录
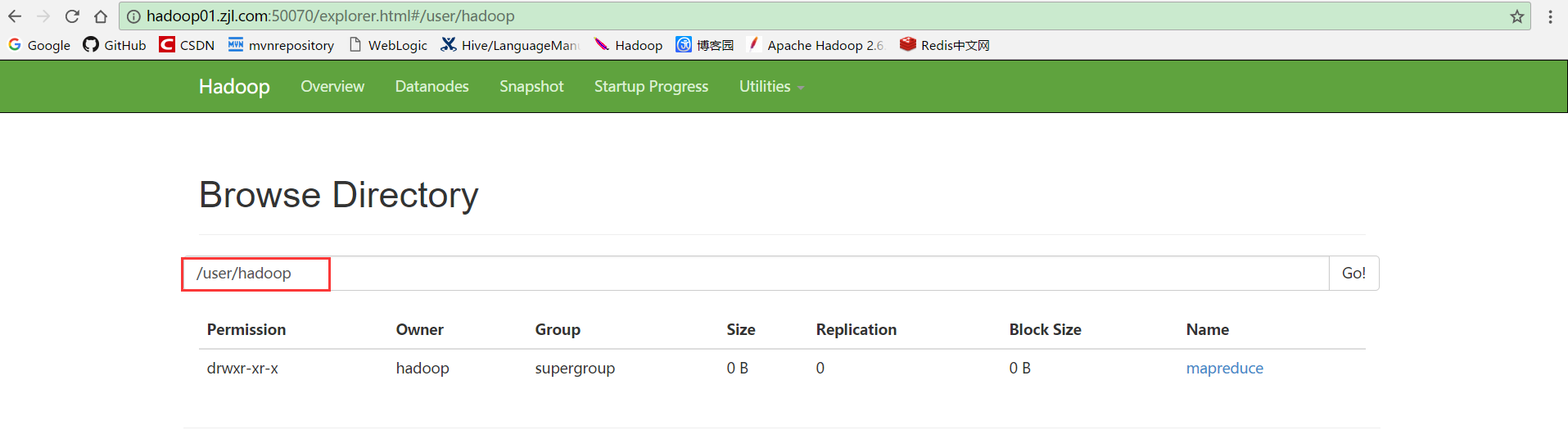
8.调用upload(inFileName, outFileName),然后刷新步骤7的页面,文件上传成功