任务:将文件(record.txt)中的数据进行分割,并安装以下规则保存起来。
1.小甲鱼的对话单独保存为boy_*.txt的文件(去掉"小甲鱼:")
2.小客服的对话单独保存为girl_*.txt的文件(去掉"小客服:")
3.文件中总共有三段对话,分别保存为boy_1.txt、boy_2.txt、boy_3.txt、gilr_1.txt、gilr_2.txt、gilr_3.txt
共6个文件。(提示:不同的对话已经使用"===="进行分割)
代码清单1:
#打开record.txt文件 f = open('E:\python\record.txt') #定义3个变量,并对它们初始化 boy = [] girl = [] count = 0 #循环读取文件 for each_line in f: #如果当前内容不"======",则继续读取内容;否则读取,开始写操作 if each_line[:6] != "======": #读取的内容以":"进行分割,分割后分别赋值给元组元素role和spoken (role,spoken) = each_line.split(':',1) #如果对话角色为"小甲鱼",则将文件追加到boy列表中 if role == '小甲鱼': boy.append(spoken) #如果对话角色为"小客服",则将文件追加到girl列表中 if role == '小客服': girl.append(spoken) else: #定义输出文件名称 file_name_boy = 'boy_'+str(count)+'.txt' file_name_girl = 'girl'+str(count)+'.txt' #打开文件 boy_file = open(file_name_boy,'w') girl_file = open(file_name_girl,'w') #writelines的参数是序列(比如列表),它会迭代帮你写入文件。 boy_file.writelines(boy) girl_file.writelines(girl) #关闭文件对象 boy_file.close() girl_file.close() #当前写操作完毕后,必须进行初始化操作,以准备下一个的写入操作 boy = [] girl = [] count += 1 #因为第三段对话的结尾没有"===",所以需要再次进行上门的重复写操作,保存第三段对话 #定义输出文件名称 file_name_boy = 'boy_'+str(count)+'.txt' file_name_girl = 'girl'+str(count)+'.txt' #打开文件 boy_file = open(file_name_boy,'w') girl_file = open(file_name_girl,'w') #writelines的参数是序列(比如列表),它会迭代帮你写入文件。 boy_file.writelines(boy) girl_file.writelines(girl) #关闭文件对象 boy_file.close() girl_file.close() #关闭文件对象 f.close()
代码清单2:
#定义一个保存文件的方法 def save_file(boy,girl,count): #定义输出文件名称 file_name_boy = 'boy_'+str(count)+'.txt' file_name_girl = 'girl'+str(count)+'.txt' #打开文件 boy_file = open(file_name_boy,'w') girl_file = open(file_name_girl,'w') #writelines的参数是序列(比如列表),它会迭代帮你写入文件。 boy_file.writelines(boy) girl_file.writelines(girl) #关闭文件对象 boy_file.close() girl_file.close() #定义一个读取和分割文件内容的方法 def read_file(filename): #打开record.txt文件 f = open('E:\python\record.txt') #定义3个变量,并对它们初始化 boy = [] girl = [] count = 0 #循环读取文件 for each_line in f: #如果当前内容不"======",则继续读取内容;否则读取,开始写操作 if each_line[:6] != "======": #读取的内容以":"进行分割,分割后分别赋值给元组元素role和spoken (role,spoken) = each_line.split(':',1) #如果对话角色为"小甲鱼",则将文件追加到boy列表中 if role == '小甲鱼': boy.append(spoken) #如果对话角色为"小客服",则将文件追加到girl列表中 if role == '小客服': girl.append(spoken) else: #保存文件 save_file(boy,girl,count) #保存完文件后,再初始化变量 boy = [] girl = [] count += 1 #因为第三段对话的结尾没有"===",所以需要再调用save_file方法,保存第三段对话 save_file(boy,girl,count) #关闭文件对象 f.close() #主方法:只要调用read_file就可以完成所有的操作 read_file('E:\python\record.txt')
问题延伸: 如下图:为什么boy[]、girl[]、count位置不同,结果完全不同呢?
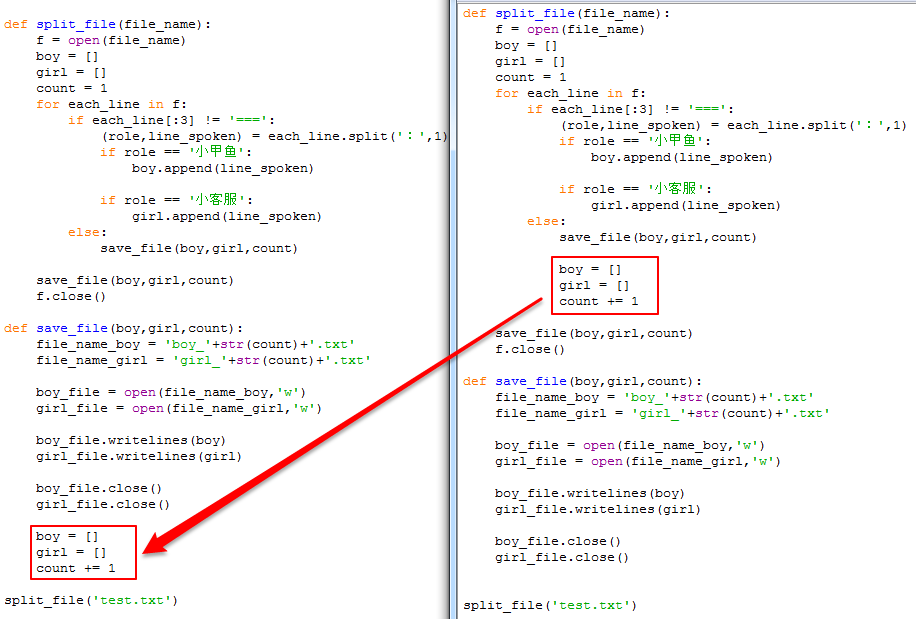
原因分析:
因为boy,girl,count三个变量是做为split_file()函数的局部变量,当把它们放在split_file()里面的时候,是对3个变量进行了初始化。
但是当你把它们放到下面save_file()函数里面的时候,就是在save_file()函数里面重新定义了三个名叫boy, girl,count的变量,
那么它和split_file()函数里面的变量是完全没有关系的。