2017-2018-1 20155329 《信息安全系统设计基础》第6周学习总结
教材学习内容总结
系统级I/O
- 输入输出I/O是在主存和外部设备(如磁盘,网络和终端)之间拷贝数据的过程。
- 输入就是从I/O设备拷贝数据到主存,而输出就是从主存拷贝数据到I/O设备。
- 所有语言的运行时系统都提供执行I/O的较高级别的工具。例如,ANSI C提供标准I/O库,包含像printf和scanf这样执行带缓冲区的I/O函数。C++语言用它的重载操作符<<(输出)和>>(输入)提供了类似的功能。在UNIX系统中,是通过使用由内核提供的系统级Unix I/O函数来实现这些比较高级的I/O函数的。
打开文件
- 一个应用程序通过要求内核打开相应的文件,来宣告它想要访问一个I/O设备。内核返回一个小的非负整数,叫做描述符,它在后续对此文件的所有操作中标识这个文件。内核记录有关这个打开文件的所有信息。应用程序只需记住这个描述符。Unⅸ外壳创建的每个进程开始时都有三个打开的文件:标准输入(描述符为0)、标准输出(描述符为1)和标准错误(描述符为2)。头文件可用来代替显式的描述符值。
改变当前的文件位置。
- 对于每个打开的文件,内核保持着一个文件位置k,初始为0。这个文件位置是从文件开头起始的字节偏移量。应用程序能够通过执行seek操作,显式地设置文件的当前位置为k。
读写文件。
- 一个读操作就是从文件拷贝n>0个字节到存储器,从当前文件位置k开始,然后将k增加到k+n。给定一个大小为m字节的文件,当k>=m时执行读操作会触发―个称为end-of-file(EOF)的条件,应用程序能检测到这个条件。在文件结尾处处并没有明确的“EOF”符号。
关闭文件。
- 当应用完成了对文件的访问之后,它就通知内核关闭这个文件。作为响应,内核释放文件打开时创建的数据结构,并将这个描述符恢复到可用的描述符池中。无论一个进程因为何种原因终止时,内核都会关闭所有打开的文件并释放它们的存储器资源。
旁注:size_t是作为usigned int,而ssize_t是作为int。
在某些情况下,read和write传送的字节比应用程序要求的要少。出现这种情况的可能的原因有:
旁注:size_t是作为usigned int,而ssize_t是作为int。
在某些情况下,read和write传送的字节比应用程序要求的要少。出现这种情况的可能的原因有:
读时遇到EOF。假设该文件从当前文件位置开始只含有20个字节,而应用程序要求我们以50个字节的片进行读取,这样一来,这个read的返回的值是20,在此之后的read则返回0。
从终端读文本行。如果打开的文件是与终端相关联的,那么每个read函数将一次传送一个文本行,返回的不足值等于文本行的大小。
读和写socket。如果打开的文件对应于网络套接字,那么内部缓冲约束和较长的网络延迟会导致read和write返回不足值。
用RIO包健壮地读写
RIO提供了两类不同的函数:
- 无缓冲的输入输出函数
- 带缓冲的输入函数
RIO的无缓冲的输入输出函数
- rio_readn函数从描述符fd的当前文件位置最多传送n个字节到存储器位置usrbuf。类似的rio_writen函数从位置usrbuf传送n个字节到描述符fd。rio_readn函数在遇到EOF时只能返回一个不足值。rio_writen函数绝不会返回不足值。
- 注意:如果rio_readn和rio_writen函数被一个从应用信号处理程序的返回中断,那么每个函数都会手动地重启read或write。
RIO的带缓冲的输入函数
- 一个文本行就是一个由 换行符 结尾的ASCII码字符序列。在Unix系统中,换行符是‘ ’,与ASCII码换行符LF相同,数值为0x0a。假设我们要编写一个程序来计算文本文件中文本行的数量应该如何来实现呢?
一种方法是用read函数来一次一个字节地从文件传送到用户存储器,检查每个字节来查找换行符。这种方法的问题就是效率不高,每次取文件中的一个字节都要求陷入内核。
一种更好的方法是调用一个包装函数(rio_readlineb),它从一个内部缓冲区拷贝一个文本行,当缓冲区变空时,会自动的调用read系统调用来重新填满缓冲区。
- 在带缓冲区的版本中,每打开一个描述符都会调用一次rio_readinitb函数,它将描述符fd和地址rp处的一个类型为rio_t的读缓冲区联系起来。
- rio_readinitb函数从文件rp读取一个文本行(包括结尾的换行符),将它拷贝到存储器位置usrbuf,并且用空字符来结束这个文本行。
- RIO读程序的核心是rio_read函数,rio_read函数可以看成是Unix read函数的带缓冲区的版本。当调用rio_read要求读取n个字节的时候,读缓冲区内有rp->rio_cnt个未读的字节。如果缓冲区为空的时候,就会调用read系统函数去填满缓冲区。这个read调用收到一个不足值的话并不是一个错误,只不过读缓冲区的是填充了一部分。
- 一旦缓冲区非空,rio_read就从读缓冲区拷贝n和rp->rio_cnt中较小值个字节到用户缓冲区,并返回拷贝字节的数目。
- 对于应用程序来说,rio_read和系统调用read有着相同的语义。出错时返回-1;在EOF时,返回0;如果要求的字节超过了读缓冲区内未读的字节的数目,它会返回一个不足值。rio_readlineb函数多次调用rio_read函数。每次调用都从读缓冲区返回一个字节,然后检查这个字节是否是结尾的换行符。
- rio_readlineb函数最多读取(maxlen-1)个字节,余下的一个字节留给结尾的空字符。超过maxlen-1字节的文本行被截断,并用一个空字符结束。
#10.5 读取文件元数据
-
应用程序能够通过调用stat和fstat函数,检索到关于文件的信息。
-
stat函数结构

-
st_size成员包含了文件的字节数大小。st_mode成员则编码了文件访问许可位和文件类型。Unix识别大量不同的文件类型。普通文件包括某种类型的二进制或文本数据。对于内核而言,文本文件和二进制文件毫无区别。
-
目录文件包含关于其他文件的信息。套接字是一种用来通过网络与其他进程通信的文件。Unix提供的宏指令根据st_mode成员来确定文件的类型。这些宏的一个子集如下:

共享文件
内核用三个相关数据结构来表示打开的文件
- 描述符表
- 文件表
- v-node表
i/o重定向
-
Unix外壳提供了I/O重定向操作符,允许用户将磁盘文件和标准输入输出联系起来。
-
I/O重定向的工作方式: 一种是使用dup2函数。

-
dup2函数拷贝描述符表表项oldfd到描述符表表项newfd,覆盖描述符表表项newfd以前的内容。如果newfd已经打开了,dup2会在拷贝oldfd之前关闭newfd。
标准i/o
- ANSI C定义了一组高级输入输出函数,成为标准I/O库,为程序员提供了Unix I/O的较高级别的替代。这个库(libc)提供了打开和关闭文件的函数(fopen和fclose)、读和写字节的函数(fread和fwrite)、读和写字符串的函数(fgets和fputs)、以及复杂的格式化I/O函数(printf和scanf)。
- 标准I/O库将一个打开的文件模型化为一个流。对于程序员而言,一个流就是一个指向FILE类型的结构的指针。每个ANSI C程序开始时都有三个打开的流stdin、stdout和stderr,分别对应于标准输入、标准输出和标准错误:

这一章的各种I/O包
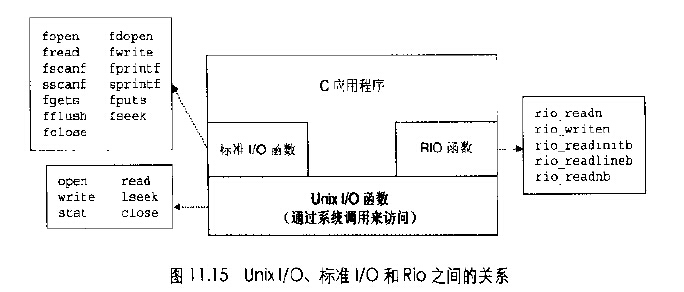
- 标准I/O流,从某种意义上来说是全双工的,因为程序能够在同一个流上执行输入和输出。
- 建议在网络套接字上不要使用标准I/O函数来进行输入和输出。而要使用健壮的RIO函数。