引言
debug spark可谓是研究spark源码的利器。spark local模式和其他分布式模式有很大不同,虽然可以在local模式下进行debug,但有很多东西只有在分布式模式下才有用。本文主要介绍在idea上如何remote debug spark的standalone模式的四大部分:Master、Worker、Driver、Executor(yarn模式比较复杂,还需要结合yarn的debug模式才能搞定,但研究standalone已经可以搞清楚spark的大部分原理了)。
主要思想
具体操作
spark-class的修改
修改spark/bin/spark-class文件:
都是在OUR_JAVA_OPTS中加入了
-Xdebug -Xrunjdwp:transport=dt_socket,address=8002,server=y,suspend=n具体见:
'org.apache.spark.deploy.master.Master')
OUR_JAVA_OPTS="$SPARK_DAEMON_JAVA_OPTS $SPARK_MASTER_OPTS -Xdebug -Xrunjdwp:transport=dt_socket,address=8500,server=y,suspend=n"
OUR_JAVA_MEM=${SPARK_DAEMON_MEMORY:-$DEFAULT_MEM}
;;
'org.apache.spark.deploy.worker.Worker')
OUR_JAVA_OPTS="$SPARK_DAEMON_JAVA_OPTS $SPARK_WORKER_OPTS -Xdebug -Xrunjdwp:transport=dt_socket,address=8511,server=y,suspend=n"
OUR_JAVA_MEM=${SPARK_DAEMON_MEMORY:-$DEFAULT_MEM}
'org.apache.spark.deploy.SparkSubmit')
OUR_JAVA_OPTS="$SPARK_JAVA_OPTS $SPARK_SUBMIT_OPTS -Xdebug -Xrunjdwp:transport=dt_socket,address=8533,server=y,suspend=n"
OUR_JAVA_MEM=${SPARK_DRIVER_MEMORY:-$DEFAULT_MEM}这样也可以对HistoryServer等进行这样的debug。
Executor debug配置
直接在sparkConf中进行设置:
sparkConf.setAppName("sparktest").set("spark.executor.extraJavaOptions", "-Xdebug -Xrunjdwp:transport=dt_socket,address=8522,server=y,suspend=n")
启动standalone
本机既作为master又作为worker,这样所有操作其实都是在本机上操作的,(当然有耐心的话,可以搞搞多台机器上的)。
1、启动master:在spark/sbin下启动
$SPARK_HOME/sbin/start-master.sh
2、启动worker:(注意:如果master启动时为形式:spark://ip:port形式还是spark://hostname:port,启动worker时需要与之对应,否则会出现连接master失败的情况)
$SPARK_HOME/bin/spark-class org.apache.spark.deploy.worker.Worker spark://localhost:7077查看Master和Worker进程,可以看到remote debug已经打开
/System/Library/Frameworks/JavaVM.framework/Versions/CurrentJDK/Home/bin/java -cp ::/Users/wangzejie/software/spark/spark-1.1.0-bin-hadoop2.3/conf:/Users/wangzejie/software/spark/spark-1.1.0-bin-hadoop2.3/lib/spark-assembly-1.1.0-hadoop2.3.0.jar:/Users/wangzejie/software/spark/spark-1.1.0-bin-hadoop2.3/lib/datanucleus-api-jdo-3.2.1.jar:/Users/wangzejie/software/spark/spark-1.1.0-bin-hadoop2.3/lib/datanucleus-core-3.2.2.jar:/Users/wangzejie/software/spark/spark-1.1.0-bin-hadoop2.3/lib/datanucleus-rdbms-3.2.1.jar -XX:MaxPermSize=128m -Dspark.akka.logLifecycleEvents=true -Xdebug -Xrunjdwp:transport=dt_socket,address=8003,server=y,suspend=n -Xms512m -Xmx512m org.apache.spark.deploy.worker.Worker spark://localhost:7077idea上监听master和worker
spark 1.1源码已经导入idea工程中,在idea的Run/Debug config进行debug端口的设置。具体见下面的图。
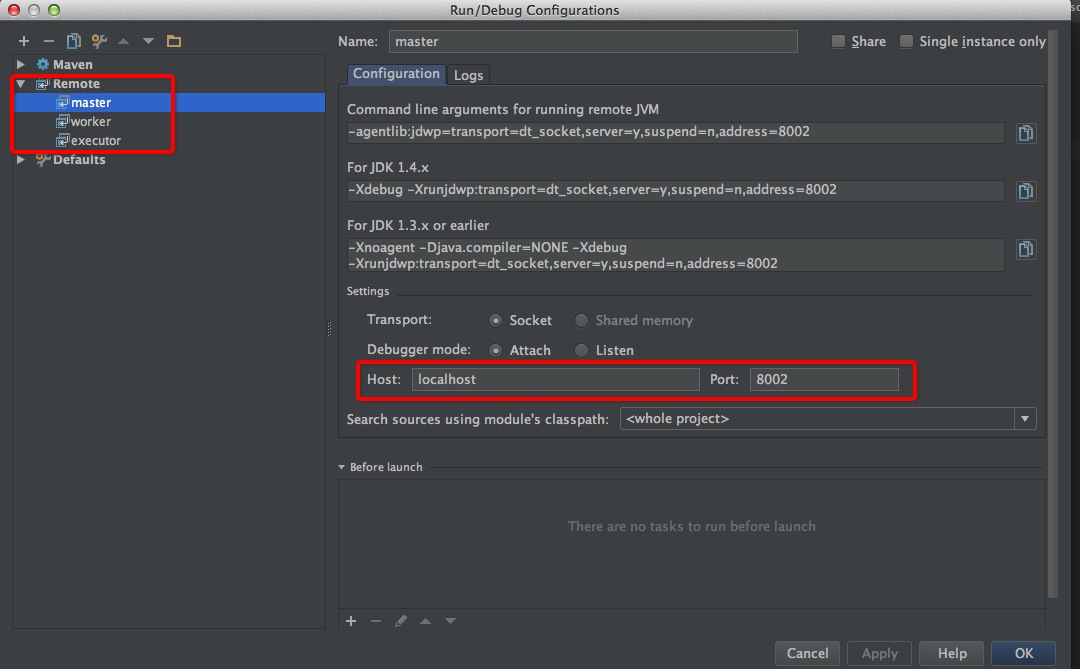
Master、Worker、Driver、Executor都是这样的设置方法。
启动master、worker的remote debug:

选择相应debug,然后点debug按钮。
监听driver
object Main {
def main(args: Array[String]) {
val sparkConf = new SparkConf()
sparkConf.setAppName("sparktest").set("spark.executor.extraJavaOptions", "-Xdebug -Xrunjdwp:transport=dt_socket,address=8005,server=y,suspend=n")
println("sleep begin.")
Thread.sleep(10000) //等待10s,让有足够时间启动driver的remote debug
println("sleep end.")
val sc = new SparkContext(sparkConf)
val rdd = sc.parallelize(1 to 10000, 10)
val count = rdd.reduce(_ + _)
println(count)
}
}
运行到driver的main方法时,我在代码中加入了sleep 10s,便于有足够时间启动driver的remote debug。
这样就可以debug我们的应用程序了。
监听Executor
当executor,具体是CoarseGrainedExecutorBackend被Worker启动时(可以看worker上控制台的日志中是否已经有启动CoarseGrainedExecutorBackend的语句,或在driver多设几个断点从而有足够时间来监听executor)。选择executor进行remote debug。
注意点
2、在debug过程中,可以访问http://localhost:8080 来看运行页面
3、目前是在单机上模拟standalone,没有对hdfs等进行配置,所以都是通过sc.parallelize来进行数据获取。
| bin/spark-submit --class org.apache.spark.examples.sample.RemoteDebug --master spark://master.hadoop:7077 --executor-memory 2g --total-executor-cores 1 /home/spark/spark-1.2.0-bin-hadoop2.4/lib/spark-examples-1.2.1-SNAPSHOT-hadoop2.4.0.jar |