pandas中包含的数据结构共有三种:
1、Series
2、DataFrame
3、Time-series
其中Series和DataFrame是两种常见的数据结构,Time-series为时间序列,这里暂且不去详细讲解。
一、Series
Series是一维数组,与Numpy中的一维array类似。二者与Python基本的数据结构List也很相近,其区别是:List中的元素可以是不同的数据类型,而Array和Series中则只允许存储相同的数据类型,这样可以更有效的使用内存,提高运算效率,并且series可以运用Ndarray或字典的几乎所有索引操作和函数,融合了字典和ndarray的优点。
1、series索引
Series类型是由一组数据及与之相关的数据索引组成
· 自动索引:不创建系统自动创建索引。
· 自定义索引:自定义索引,创建完自定义索引后,自动索引也在。
Series可以理解是一维带‘标签’数组,它的基本操作类似Ndarray和字典,genuine索引对齐。
2、对象创建
Series(列表/元组/字典/标量/Numpy数组/range等序列, <index=param1>)
不写index会自动创建索引,如果写定指定索引,index可以是列表,numpy数组。
例:
import pandas as pd a = pd.Series([1, 2, 3], index=range(0, 3)) b = pd.Series(range(5, 10))
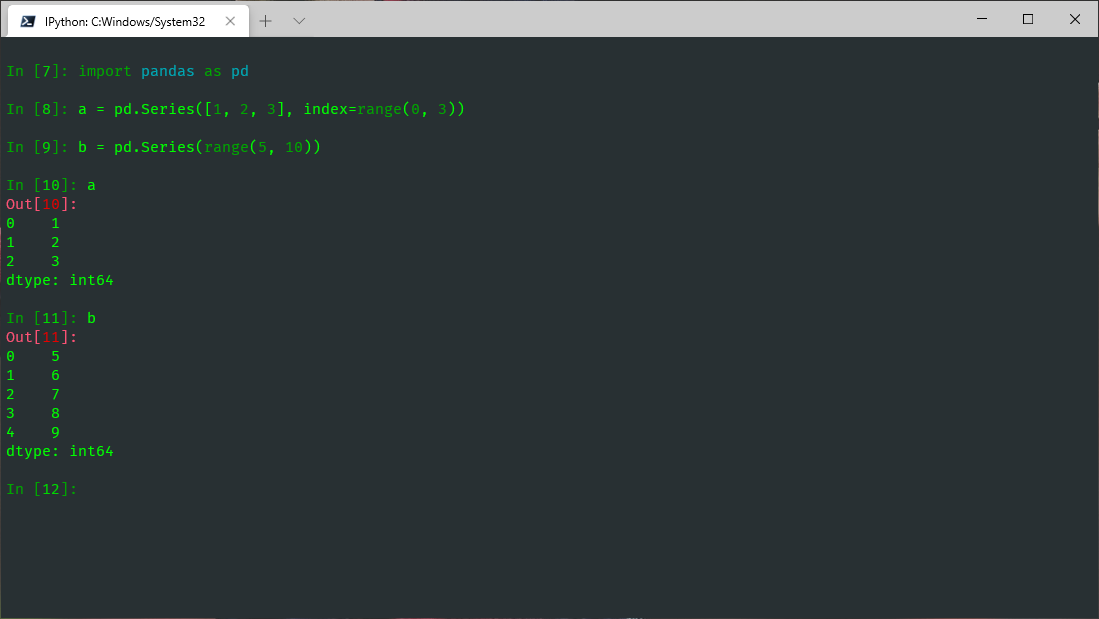
Series的主要属性包括index和values两部分,values获取数据,底层存储的是numpy数组;index获取索引。
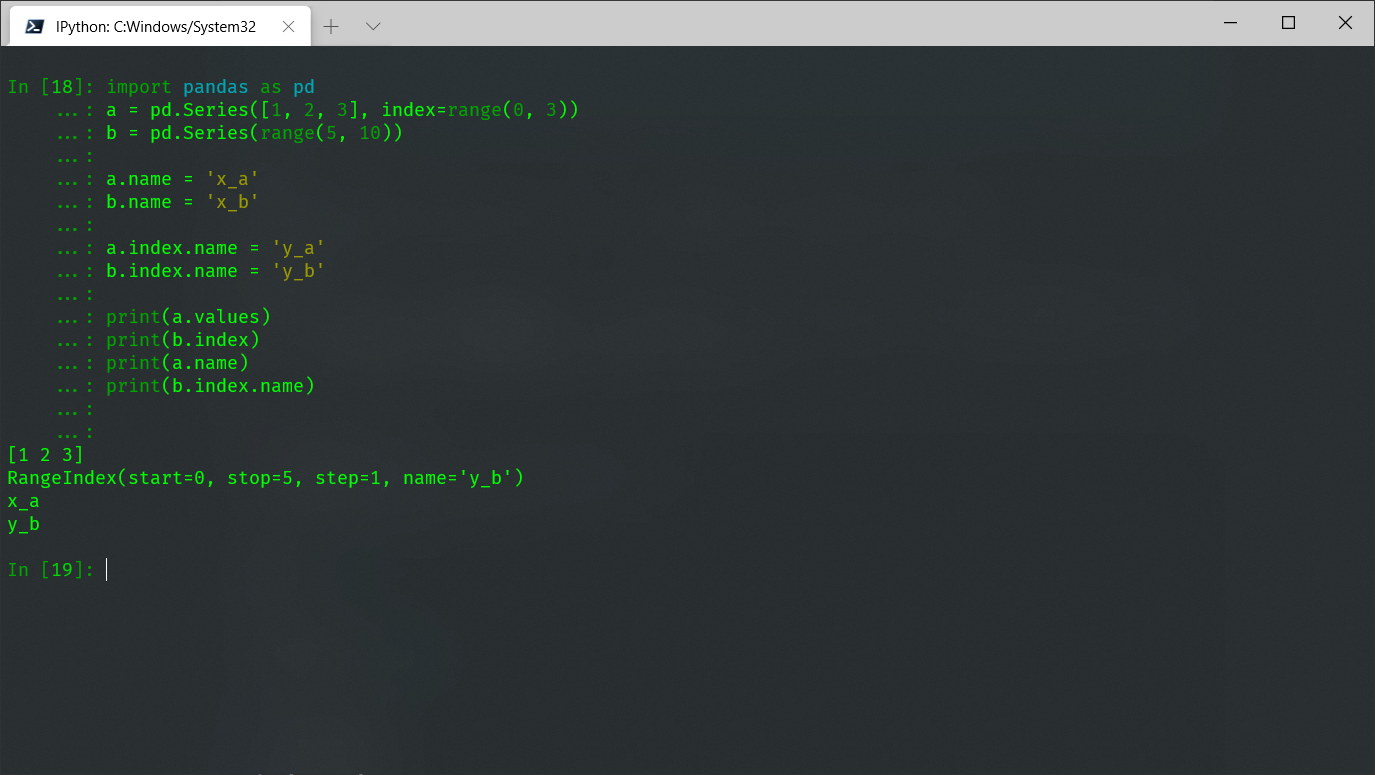
另外,Series还有两个不太重要的属性,series.name和index.name,分别表示series的名字和索引的名字。同时,series还有一些类似于numpy数组的属性,比如dtype和shape等。
例:
import pandas as pd a = pd.Series([1, 2, 3], index=range(0, 3)) b = pd.Series(range(5, 10)) a.name = 'x_a' b.name = 'x_b' a.index.name = 'y_a' b.index.name = 'y_b' print(a.values) print(b.index) print(a.name) print(b.index.name)
4、类型选取
series类型的选取类似numpy数组,索引的方式相同,采用[],numpy中的运算和操作可用于series类型,可以通过自定义索引的列表进行切片也可以通过自动索引进行切片,如果存在自定义索引,则一同被切片。
series类型的操作类似于python字典类型:通过自定义索引访问,保留字in操作,使用get()方法,get(key, default=none)函数返回指定键的值,如果值不再字典中则返回默认值(默认为空),key是要查找的键,default是设置的默认值。
5、Series类型对齐操作
series类型在运算中会自动对齐不同索引的数据,例如:
import pandas as pd a = pd.Series([1, 2, 3], index=range(0, 3)) b = pd.Series(range(5, 10)) print(a + b)

6、数据的获取、修改、删除
① 数据的获取
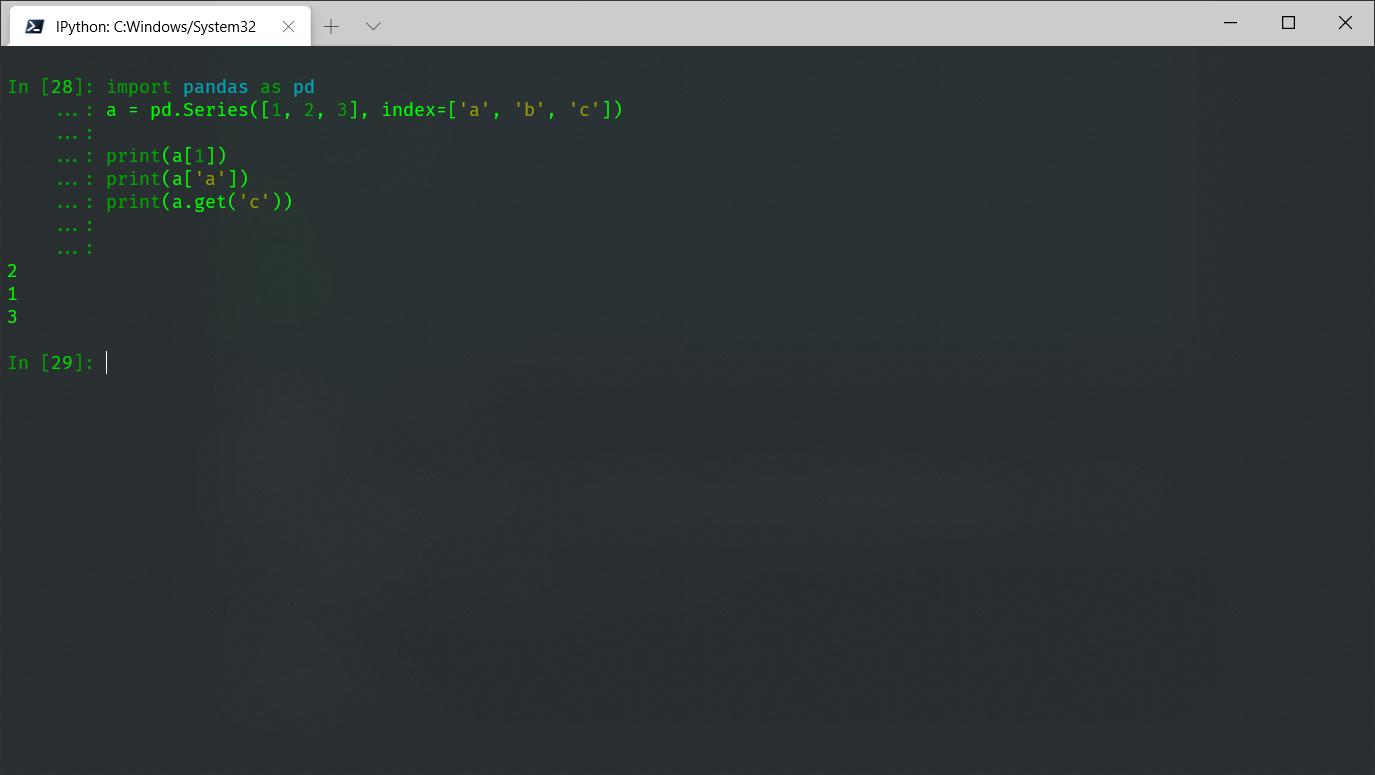
由于具备numpy数组和字典的特性,series可以像使用numpy数组的索引切片或用字典的get一样来用,例如:
import pandas as pd a = pd.Series([1, 2, 3], index=['a', 'b', 'c']) print(a[1]) print(a['a']) print(a.get('c'))
② 数据的修改
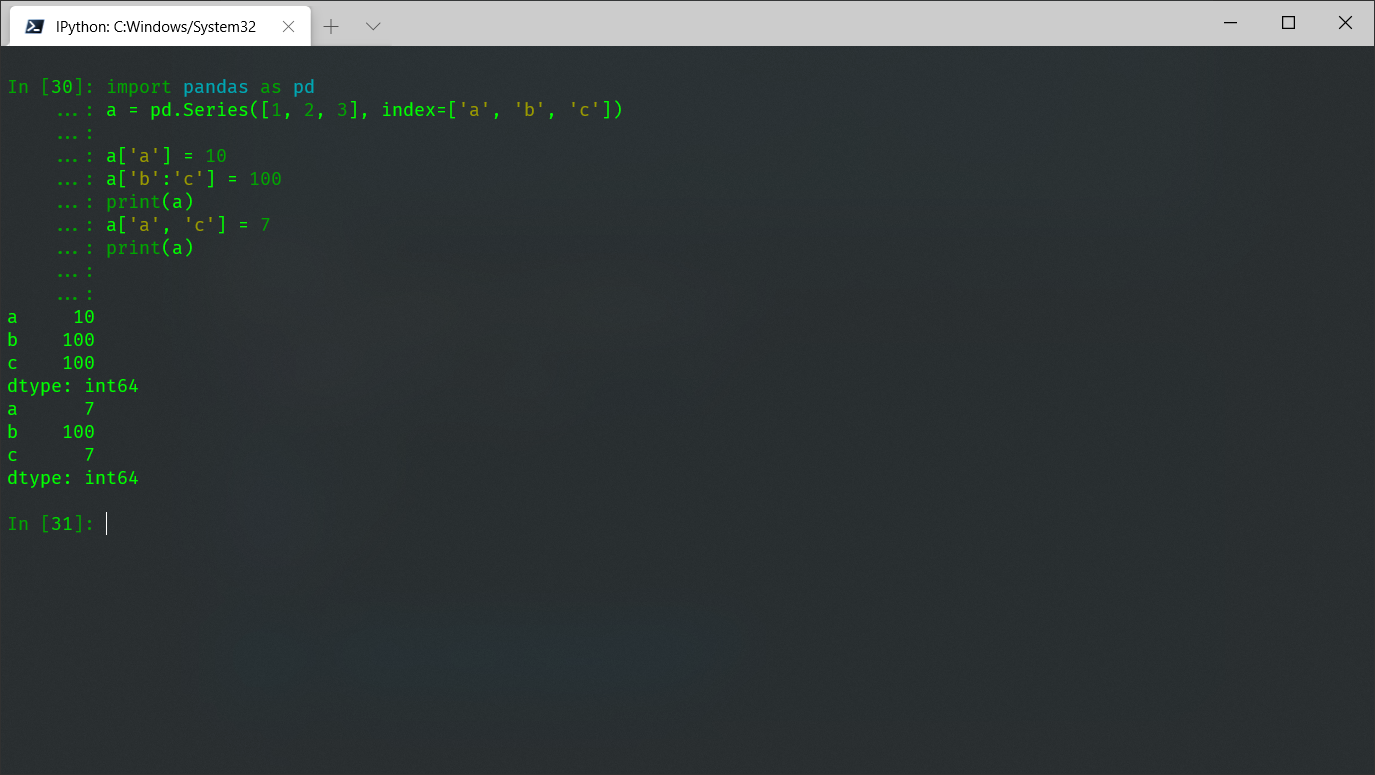
对于series结构一般采用索引和切片的方式修改数据,例如:
import pandas as pd a = pd.Series([1, 2, 3], index=['a', 'b', 'c']) a['a'] = 10 a['b':'c'] = 100 print(a) a['a', 'c'] = 7 print(a) ''' 其中,使用“:”切片时,是修改从index1-index2的所有数据; 使用“,"时,是将index1和index2单独取出来进行修改。 '''
③ 数据的删除
可使用drop方法和pop方法删除数据。使用drop方法则结果改变,使用pop方法则像字典的用法,改变自身。
例如:
import pandas as pd a = pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd']) print(a.drop('a')) print(a.drop(['b', 'd'])) b = pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd']) print(b.pop('a')) # 返回操作状态,成功为True print(b)

二、DataFrame
DataFrame类型由公用相同索引的一组序列组成,是一个表格型的数据类型,每列值类型可以不同。DataFrame即有行索引也有列索引:Index axis = 0(默认)、Column axis = 1(默认)。
DataFrame常用于表达二维数据,但可以表达多维数据,基本操作类似于Series,依据行列索引。
1、DataFrame的创建
① 从内存中创建
DataFrame(字典/列表/numpy数组/DataFrame, index=0, columns=1)
说明:在创建的时候也可以不指定index和columns,在创建完后单独设置这两个属性。
参数:
-
字典 - key作为列名,value作为该列的值。
-
列表 - 作为值
-
Numpy数组 - 作为值
例:
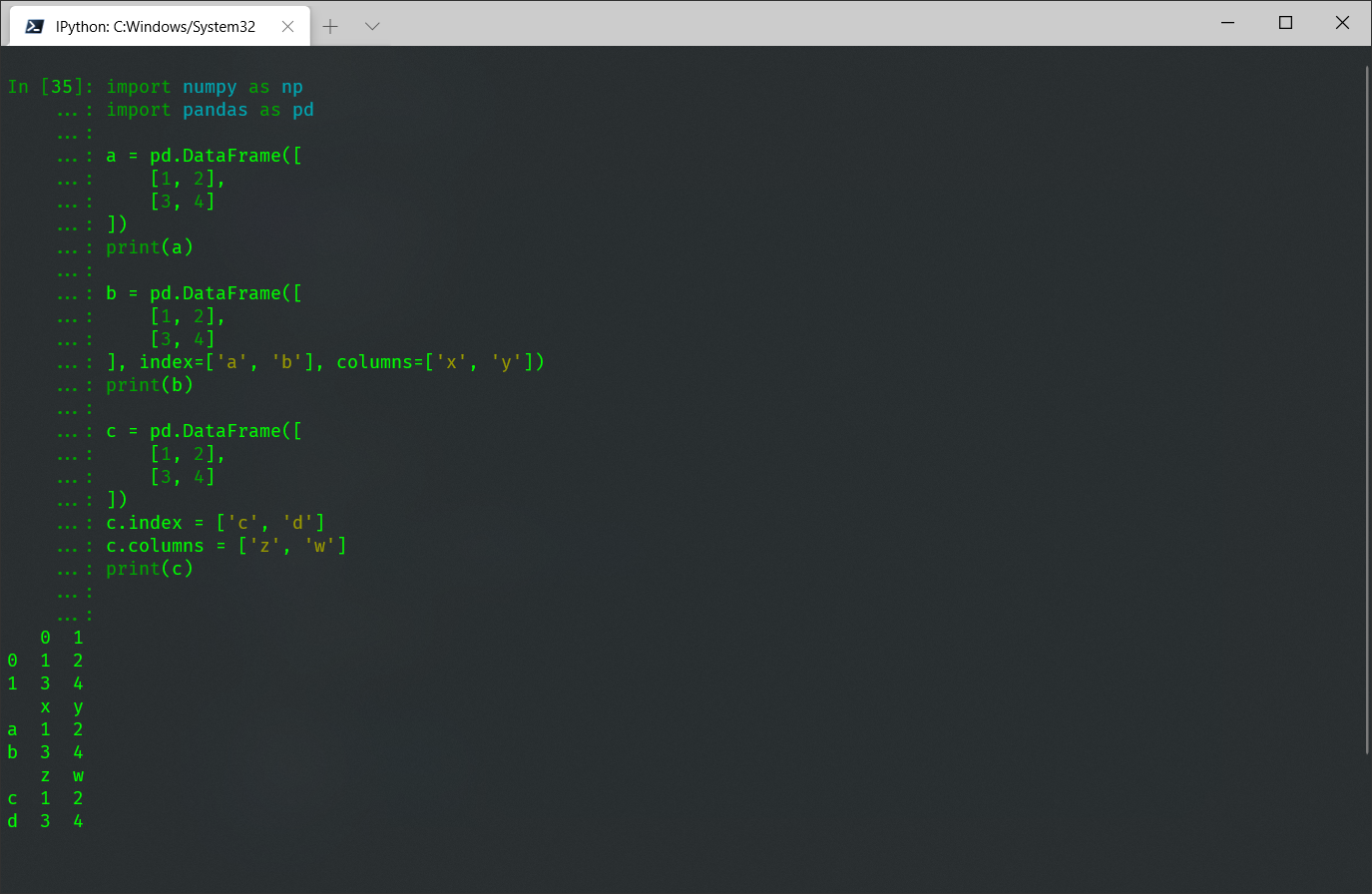
import pandas as pd # 说明:数组也可以使用numpy生成,这里只演示手动输入数组 a = pd.DataFrame([ [1, 2], [3, 4] ]) print(a) b = pd.DataFrame([ [1, 2], [3, 4] ], index=['a', 'b'], columns=['x', 'y']) print(b) c = pd.DataFrame([ [1, 2], [3, 4] ]) c.index = ['c', 'd'] c.columns = ['z', 'w'] print(c)
② 从文件中创建
DataFrame可以从文件中创建:文件第一行默认作为列索引(columns),默认为没有行索引,可以通过indx_dol参数设置第1列或前几行作为行索引。如果第一行不作为列索引,设置 header=None 。文件编码为utf-8,可以通过参数encoding设置编码。
例如:
pd.read_table(filename, sep=' ') # 从限定分隔符的文本文件导入数据,默认是tab pd.read_csv(filename) # 从CSV文件导入数据, 文件是逗号分隔 pd.read_excel(filename) # 从Excel文件导入数据 pd.read_sql(query, connection_object) # 从SQL表/库导入数据 pd.read_json(json_string) # 从json格式字符串导入数据 pd.read_html(url) # 解析url、字符串或者html文件,抽取其中的tables表格 pd.read_clipboard() # 从你的粘贴板获取内容,传给read_table()
同时注意,从文件读取的时候可以可以带行索引,用 index_col=num ,例如:a = pd.read_csv('filename', encoding='utf-8', index_col=0)。若不把第一行作为列索引(有些情况下文件中全部都是数据没有存储索引)则可以这样编写代码:a = pd.read_csv('filename', header=None)。若想查看DataFrame的信息,可以使用info方法,如图:

2、DataFrame数据写入文件
df.to_csv(filename) # 导出数据到CSV文件 df.to_excel(filename) # 导出数据到Excel文件 df.to_sql(table_name, connection_object) # 导出数据到SQL表 df.to_json(filename) # 以Json格式导出数据到文本文件
若将行索引和列索引写入文件,则df.to_csv(filename)后面不带任何参数;若行索引不写入,则df.to_csv(filename, index=False);若行列索引都不写入,则df.to_csv(filename, index=False, header=False)
3、DataFrame的属性
values表示值,index表示行索引,columns表示列索引,index.name表示行索引名字,columns.name表示列索引名字,其他属性:dtypes,shape等,DataFrame同样拥有类似于numpy数组的大部分属性。
例:
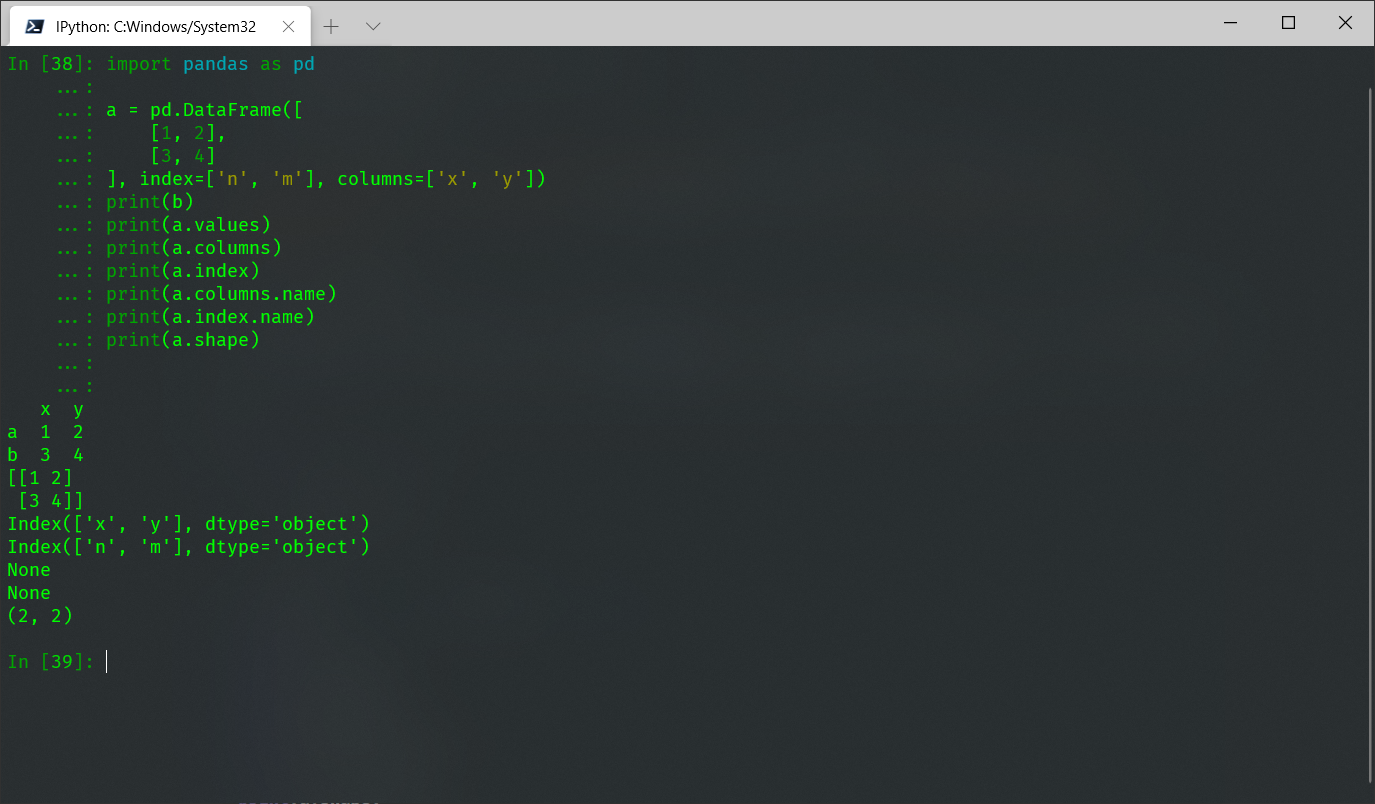
import pandas as pd a = pd.DataFrame([ [1, 2], [3, 4] ], index=['n', 'm'], columns=['x', 'y']) print(b) print(a.values) print(a.columns) print(a.index) print(a.columns.name) print(a.index.name) print(a.shape)
4、DataFrame中的函数和方法
4.1 取值和修改(索引,切片,ix,loc,iloc)
DataFrame的取值和修改应该从三个层次考虑:行列,区域,单元格。每个层次都有其对应的方法:行列df[]、df.ix,区域df.ix[],单元格df.ix,其中ix官方推荐使用iloc和loc代替,loc和iloc的用法和ix基本一样,只是loc参数用手动索引,iloc用自动索引,ix为混用。
4.2 其他函数
查看数据:
df.head(n) # 查看前n行 df.tail(n) # 查看后n行 df.shape # 查看行数和列数 df.info() # 查看索引、数据类型和内存信息 df.describe() # 查看数值型列的汇总统计 df.apply(def_name) # 把df应用于某个函数 # s.value_counts(dropna=False) # 查看Series对象的唯一值和计数
清洗数据:
df.columns = [...] # 重命名列名 df.index = [...] df.isnull() # 检查DataFrame对象中的空值,并返回一个Boolean数组 df.notnull() # 检查DataFrame对象中的非空值,并返回一个Boolean数组 df.dropna() # 删除所有包含空值的行 df.dropna(axis=1) # 删除所有包含空值的列 df.fillna(x) # 用x替换DataFrame对象中所有的空值 df.set_index('column_one') # 更改索引列 df.dropna(axis=1, thresh=n) # 删除所有小于n个非空值的列 df.rename(columns=lambda x: x + '1') # 批量更改列名 df.rename(columns={'old_name': 'new_ name'}) # 选择性更改列名 df.rename(index=lambda x: x + 1) # 批量重命名索引
数据规整:
df[df[col] > 0.5] # 选择col列的值大于0.5的行 df.sort_values(col1) # 按照列col1排序数据, 默认升序排列 df.sort_values(col2, ascending=False) # 按照列col1降序排列数据 df.sort_values([col1, col2], ascending=[True, False]) # 先按列col1升序排列,后按col2降序排列数据 df.groupby(col) # 返回一个按列col进行分组的Groupby对象 df.groupby([col1, col2]) # 返回一个按多列进行分组的Groupby对象 df.groupby(col1).agg(np.mean) # 返回按列col1分组的所有列的均值 df.groupby(col1).sum() # 返回按列col1分组的所有列的和 df.groupby(col1).mean()[col2] # 返回按列col1进行分组后,列col2的均值 data.apply(np.mean) # 对DataFrame中的每一列应用函数np.mean data.apply(np.max, axis=1) # 对DataFrame中的每一行应用函数np.max # 创建一个按列col1进行分组,并计算col2和col3各自均值的数据透视表 df.pivot_table(index=col1, values=[col2, col3], aggfunc=np.mean) pd.crosstab(df.col1, df.col2) # 按照指定的行(col1)和列(col2)统计分组频数
数据合并:
df1.append(df2) # 将df2中的行添加到df1的尾部 pd.concat([df1, df2], axis=0) # 将df2中的行添加到df1的底部(axis=1的时候将df2的列添加到df1的尾部)
数据统计:
df.describe() # 查看数据值列的汇总统计 df.mean() # 返回所有列的均值 df.corr() # 返回列与列之间的相关系数 df.count() # 返回每一列中的非空值的个数 df.max() # 返回每一列的最大值 df.min() # 返回每一列的最小值 df.median() # 返回每一列的中位数 df.std() # 返回每一列的标准差