补交的作业(疫情在家学习期间无电脑,之前在家时已向老师说明情况了):
作业1:https://www.cnblogs.com/hongxinma/p/12895161.html
作业2:https://www.cnblogs.com/hongxinma/p/12895392.html
作业3:https://www.cnblogs.com/hongxinma/p/12895719.html
作业4:https://www.cnblogs.com/hongxinma/p/12900949.html
作业5:https://www.cnblogs.com/hongxinma/p/12904246.html
作业6:https://www.cnblogs.com/hongxinma/p/12908789.html
作业7:https://www.cnblogs.com/hongxinma/p/12908830.html
作业8:https://www.cnblogs.com/hongxinma/p/12908886.html
作业9:https://www.cnblogs.com/hongxinma/p/12908900.html
答:
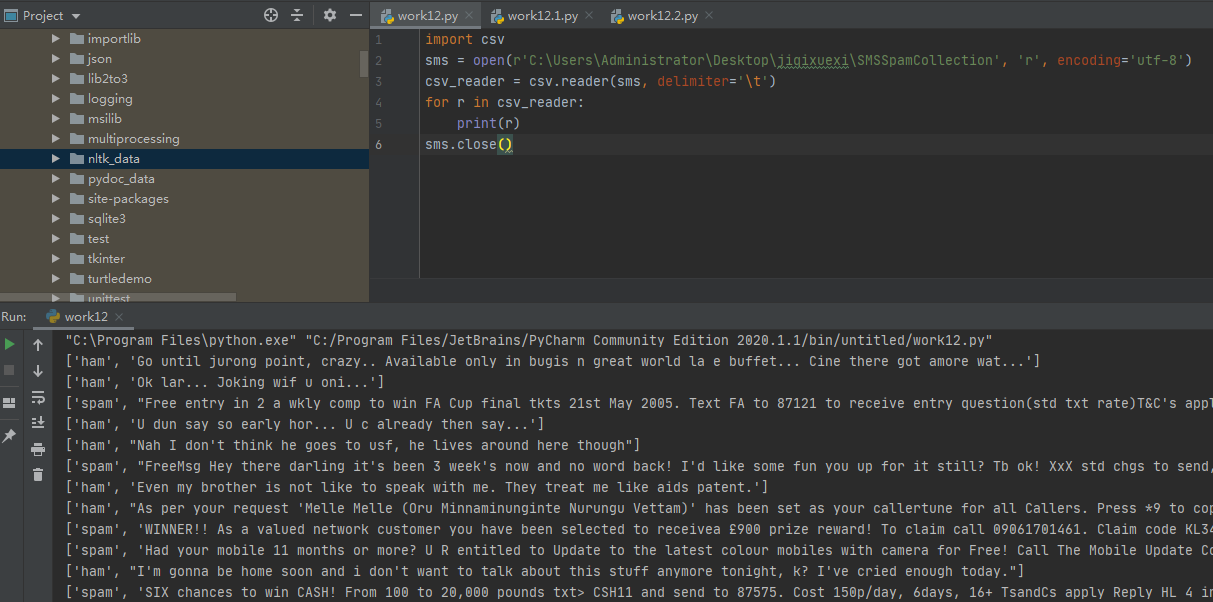
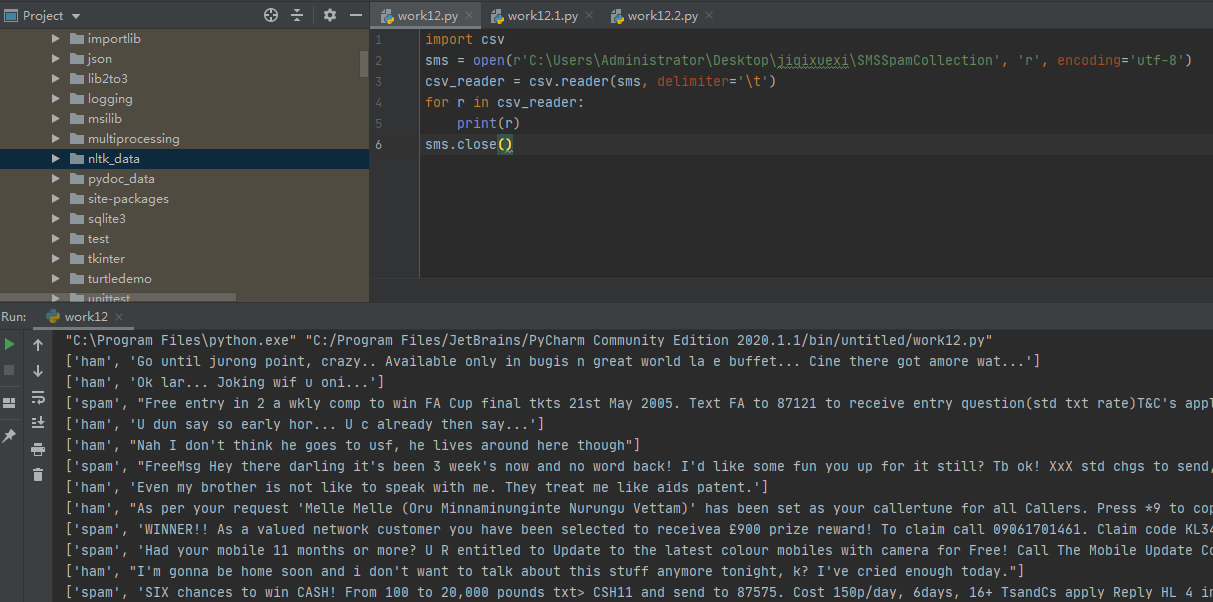
1.读取
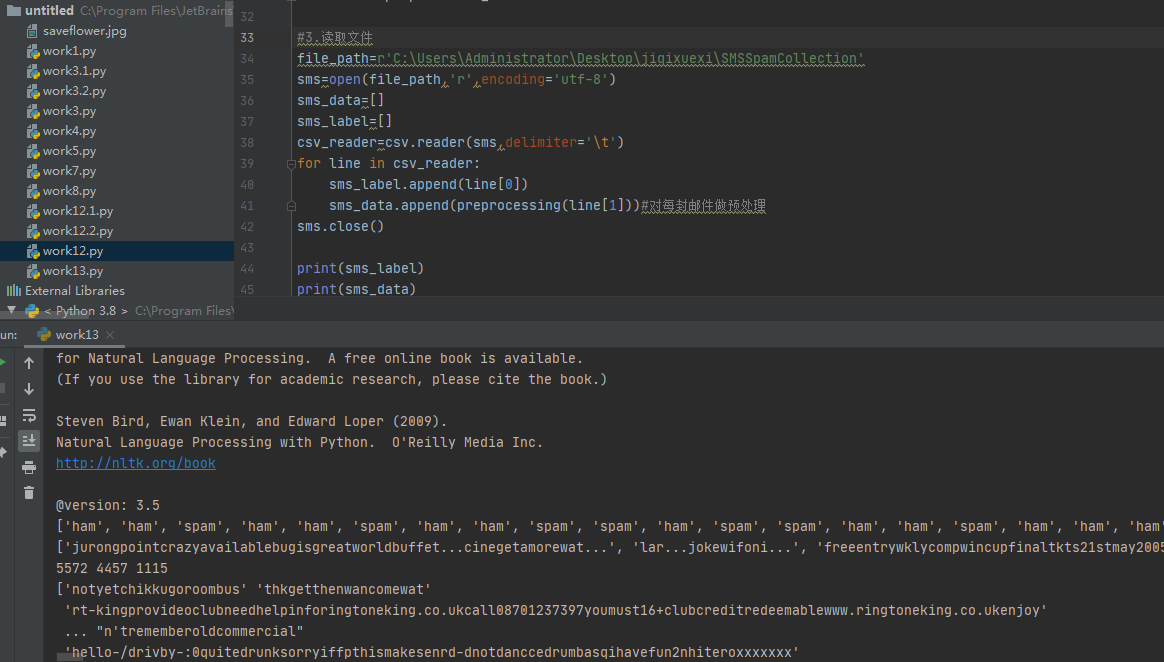
2.数据预处理
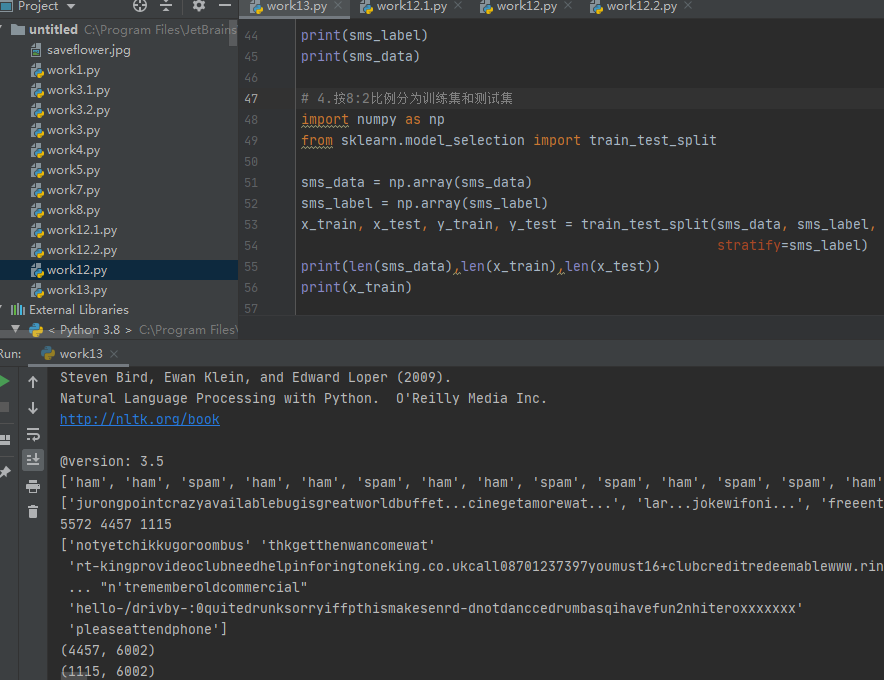
3.数据划分—训练集和测试集数据划分
from sklearn.model_selection import train_test_split
x_train,x_test, y_train, y_test = train_test_split(data, target, test_size=0.2, random_state=0, stratify=y_train)
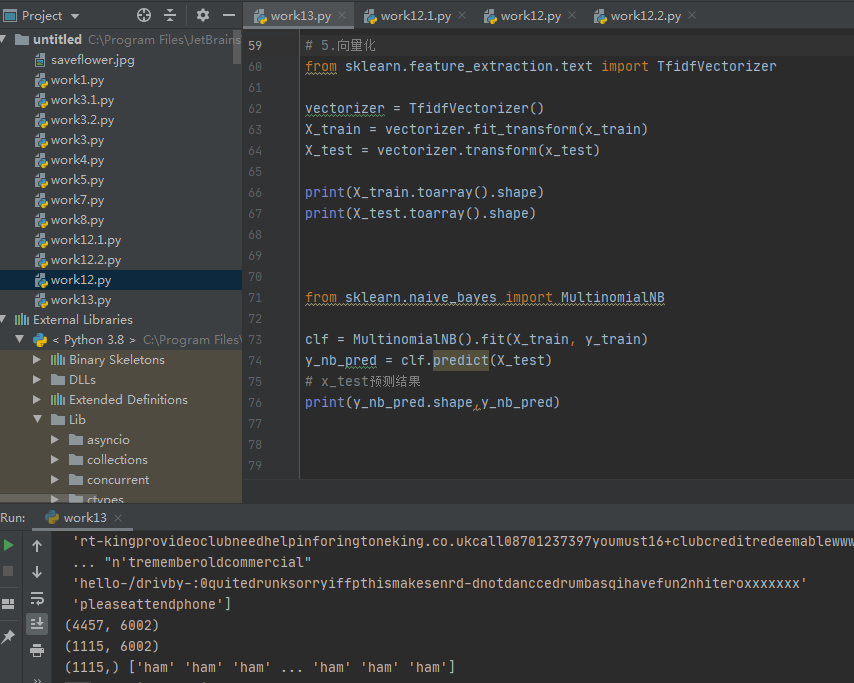
4.文本特征提取
sklearn.feature_extraction.text.CountVectorizer
sklearn.feature_extraction.text.TfidfVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf2 = TfidfVectorizer()
观察邮件与向量的关系
向量还原为邮件
4.模型选择
from sklearn.naive_bayes import GaussianNB
from sklearn.naive_bayes import MultinomialNB
说明为什么选择这个模型?
答:朴素贝叶斯分类器是一种有监督的学习方法,适用于处理不确定性信息。其表现出高精度和高效率,具有最小的误分类率,耗时开销小。
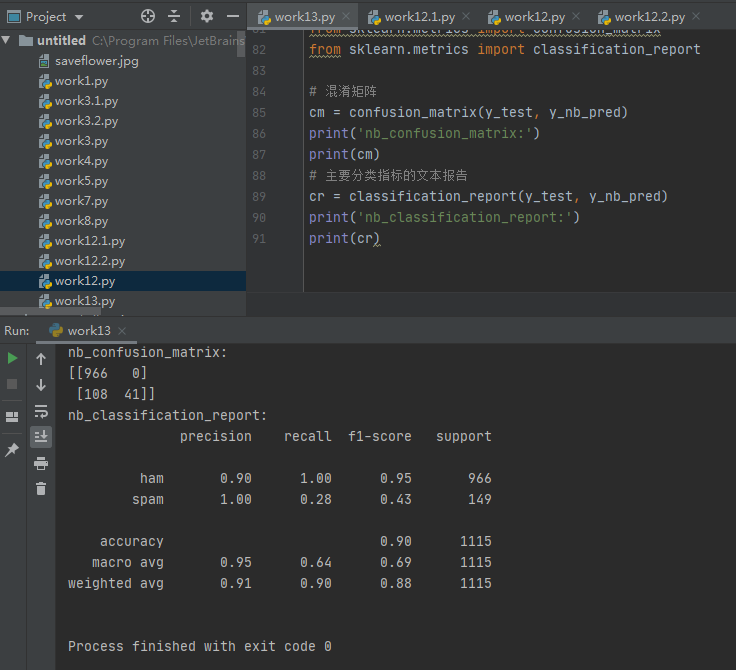
5.模型评价:混淆矩阵,分类报告
from sklearn.metrics import confusion_matrix
confusion_matrix = confusion_matrix(y_test, y_predict)
说明混淆矩阵的含义
from sklearn.metrics import classification_report
说明准确率、精确率、召回率、F值分别代表的意义
答:混淆矩阵是数据科学、数据分析和机器学习中总结分类模型预测结果的情形分析表,以矩阵形式将数据集中的记录按照真实的类别与分类模型作出的分类判断两个标准进行汇总。

6.比较与总结
如果用CountVectorizer进行文本特征生成,与TfidfVectorizer相比,效果如何?
答:CountVectorizer只考虑每种词汇在该训练文本中出现的频率,而TfidfVectorizer除了考量某一词汇在当前训练文本中出现的频率之外,同时关注包含这个词汇的其它训练文本数目的倒数。相比之下,训练文本的数量越多,TfidfVectorizer这种特征量化方式就更有优势。