1.字符串操作:
解析身份证号:生日、性别、出生地等。
地址码: 表示编码对象常住户口所在县(市、旗、区)的行政区划代码。
出生日期码:表示编码对象出生的年、月、日,年、月、日代码之间不用分隔符,格式为YYYYMMDD,如19880328。
顺序码: 表示在同一地址码所标识的区域范围内,对同年、同月、同日出生的人编定的顺序号,顺序码的奇数分配给男性,偶数分配给女性。
校验码: 根据本体码,通过采用ISO 7064:1983,MOD 11-2校验码系统计算出校验码。前面有提到数字校验码,我们知道校验码也有X的,实质上为罗马字符X,相当于10.
凯撒密码编码与解码
凯撒加密(Caesar cipher)是一种简单的消息编码方式:它根据字母表将消息中的每个字母移动常量位k。举个例子如果k等于3,则在编码后的消息中,每个字母都会向前移动3位:a会被替换为d;b会被替换成f;依此类推。字母表末尾将回卷到字母表开头。于是,w会被替换为z, x会被替换为a。在解码消息的时候,每个字母会反方向移动同样的位数。
网址观察与批量生成
像学校官网在新闻模块,每一页都有相对应在html页面,比如第一页,网址就为:http://news.gzcc.cn/html/xiaoyuanxinwen/1.html 以此类推。可以直接使用for循环输出网址。
for i in range(1,6):
url='http://news.gzcc.cn/html/xiaoyuanxinwen/{}.html'.format(i)
print(url)
2.英文词频统计预处理
首先我先在把文章先放在编译器先执行一遍
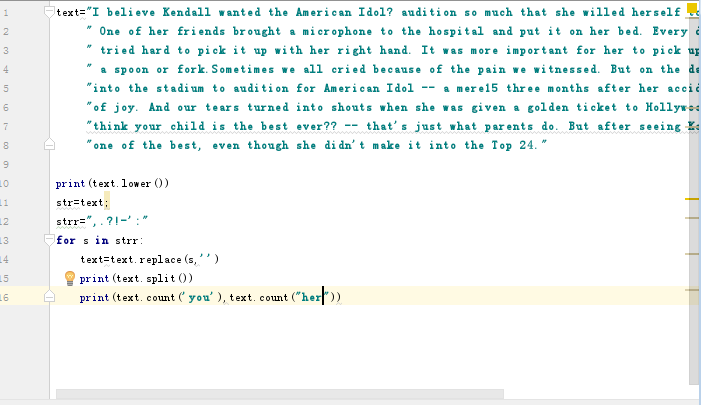
结果如图:

然后在把这些文章放在E盘中进行文件读取操作,代码如图:
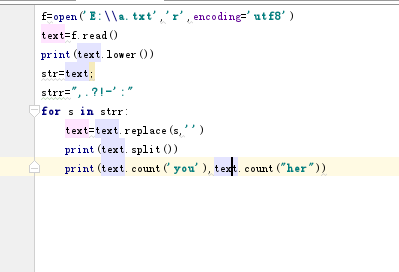
看起来确实简便了很多,结果如图:

此次进行文件操作在结果与上面在图一样,说明我的文件操作没有错误。