数据质量:
1/ 数据质量控制环节
2/ 元数据管理
数据质量包括:
数据的完整性
数据自成体系、无数据缺失(包括实体记录缺失、字段信息缺失)
数据一致性:
在整个数仓中,同一数据各主题、层次数据一致
正确性:
在数仓各部分、确保数据不失真
及时性:
整个数仓处理过程中,数据及时到位、及时反馈
数据质量的控制不只是在数据进入数仓后才开始,而是渗透到数据流通的各个环节:
数据生产
数据采集与同步
数据模型设计
ETL开发
指标体系
比如:
一、数据生产环节面临的问题:
1/ 业务侧有独立的设计,数据仓库开发人员不易介入
2/ 一般公司业务现行,数据仓库建设靠后,业务设计的时候没有兼顾数据侧
3/ 传统公司业务较稳定,但互联网公司业务频繁变动,会存在信息不同步或同步不及时
4/ 源侧数据随意变更
解决思路:
1/ 尽可能的向业务侧靠拢,了解公司产品、了解业务侧技术架构,向他们灌输数据思维,强调数据的重要性
2/ 流程方面,推动或约束产品经理、研发设计人员同步产品动态信息,参与产品需求评审、技术方案评审,甚至出一些表、接口设计规范,形成上线通报机制
3/ 技术方面,无论多么完善的流程,都会打折落地,所以要从技术角度去控制,比如利用技术手段捕获上线结构变化来避免信息不同步
二、数据采集与同步:
问题:
1/ 数据源侧的采集边界控制
2/ 采集方案要兼顾 源侧的存储方案和技术架构
3/ 采集过程中的变化数据
解决办法:
1/ 能够自己采集的,自己去源侧采集数据,更方便控制数据采集边界.部分场景不允许自己采集的(比如银行有些数据是不允许采集的,此时谁的数据谁负责出,推送到统一的接口),但需要数仓侧定义接口规范,确保统一的数据接入规范.
2/ 面对不同系统不同的存储方案或技术架构,采集侧尽量采用统一的采集方案,避免到数仓侧的标准不统一
3/ 对于采集过程中的数据变化,第一需要控制好采集边界,第二需要定义清楚变化部分的数据归属,一定程度上允许多采集下一个周期的数据,但不可少采集
4/设计合理的补偿策略
三、数据模型设计:

四、 ETL开发:(数仓重点关注)
job可重复性
可局部修复
程序灵活高质量
合理的review机制
敏感的监控机制、灵活的优先级策略(尤其对调度)
五、指标体系:
统一的指标口径、定义 (高层的人推动)
构建指标管理系统,不仅停留在口头层面(做了,让用户去用。而不是还没做,征求大家的规范,再按规范去做。认为好就先推出去)
六、事后校验:(数仓重点关注)

元数据管理:
描述、管理数据的数据称为元数据
1/ 数据仓库模型
2/ 调度过程数据
3/ 数据字典(hive表里)
4/ 血缘关系(各个表间的血缘关系,通过这个可以知道表的数据关系)
5/ 指标体系

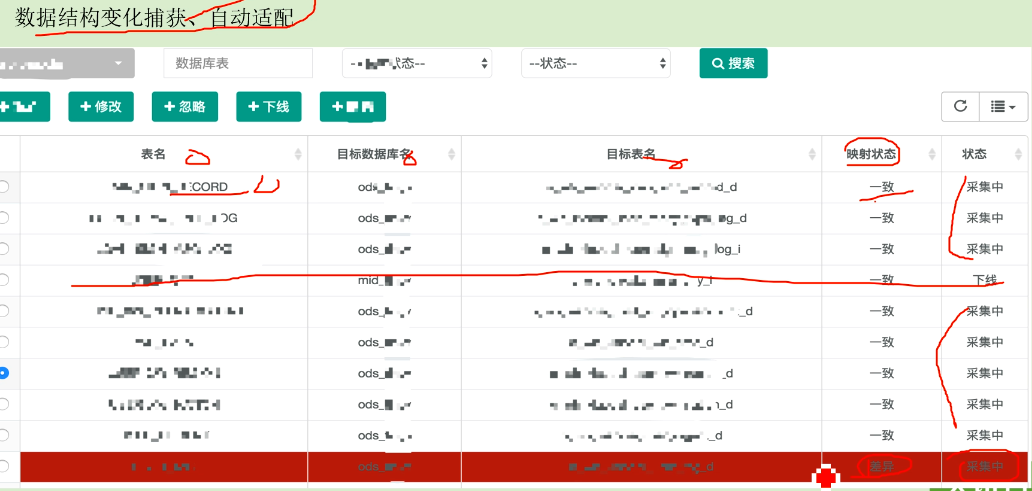
案例:某公司的数据管理平台

#能够找到原系统的数据库,采集到哪儿,目标表名,数据是否一致(能发现源端是否发生变化),状态。
任务依赖:

数据质量监控,某一指标,指标名称

命名规范:



对ods层:

ETL脚本命名规范:



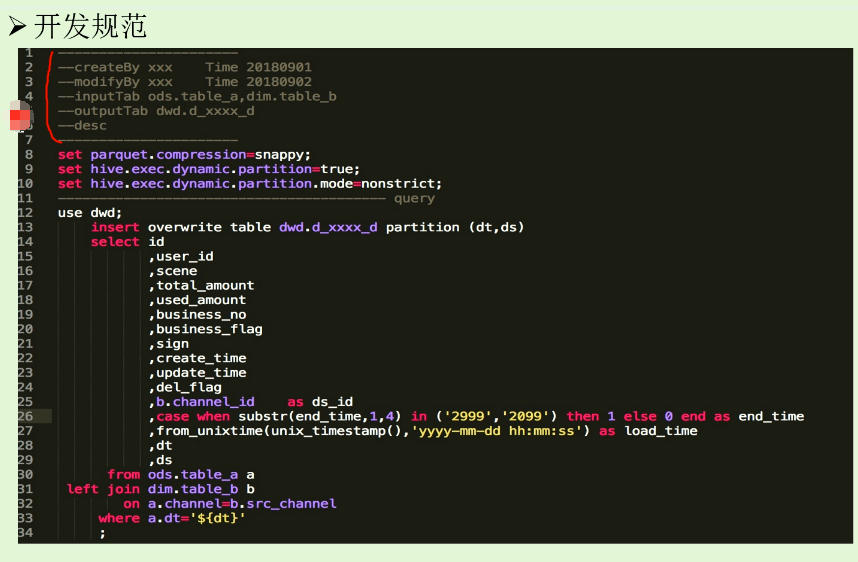
开发规范:

样例: