参考:http://blog.csdn.net/google19890102/article/details/50522945
0-1损失函数

平方损失函数(最小二乘法)
最小二乘法是线性回归的一种,OLS将问题转化成了一个凸优化问题。在线性回归中,它假设样本和噪声都服从高斯分布(为什么假设成高斯分布呢?其实这里隐藏了一个小知识点,就是中心极限定理,可以参考
- 简单,计算方便;
- 欧氏距离是一种很好的相似性度量标准;
- 在不同的表示域变换后特征性质不变。
平方损失(Square loss)的标准形式如下:

当样本个数为n时,此时的损失函数变为:

Y-f(X)表示的是残差,整个式子表示的是残差的平方和,而我们的目的就是最小化这个目标函数值(注:该式子未加入正则项),也就是最小化残差的平方和(residual sum of squares,RSS)。
而在实际应用中,通常会使用均方差(MSE)作为一项衡量指标,公式如下:

Log损失函数
Log损失是0-1损失函数的一种代理函数,Log损失的具体形式如下:
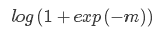
运用Log损失的典型分类器是Logistic回归算法。
Hinge损失函数
Hinge损失是0-1损失函数的一种代理函数,Hinge损失的具体形式如下:
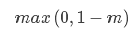
运用Hinge损失的典型分类器是SVM算法。
指数损失
指数损失是0-1损失函数的一种代理函数,指数损失的具体形式如下:
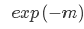
运用指数损失的典型分类器是AdaBoost算法。
感知损失
感知损失是Hinge损失的一个变种,感知损失的具体形式如下:
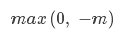
运用感知损失的典型分类器是感知机算法。