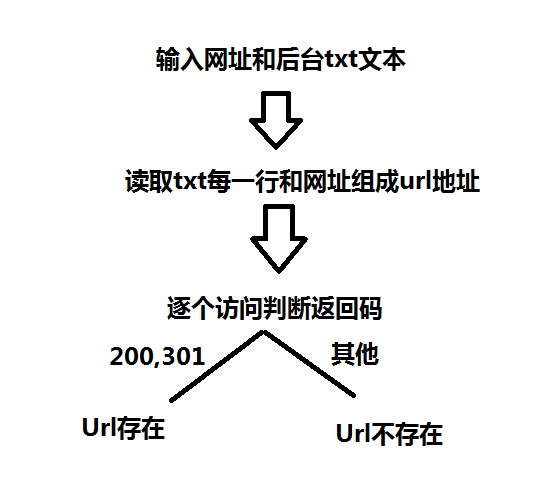
Python 网站后台扫描脚本
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
#!/usr/bin/python#coding=utf-8import sysimport urllibimport timeurl = "http://123.207.123.228/"txt = open(r"C:UserswwDesktophoutaiphp.txt","r")open_url = []all_url = []def search_url(url,txt): with open(r"C:UserswwDesktophoutaiphp.txt","r") as f : for each in f: each = each.replace('
','') urllist = url+each all_url.append(urllist) print("查找:"+urllist+'
') try: req = urllib.urlopen(urllist) if req.getcode() == 200: open_url.append(urllist) if req.getcode() == 301: open_url.append(urllist) except: passdef main(): search_url(url,txt) if open_url: print("后台地址:") for each in open_url: print("[+]"+each) else: print("没有找到网站后台")if __name__ == "__main__": main() |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
#!/usr/bin/python#coding=utf-8import sysimport urllibimport timeurl = "http://123.207.123.228/"txt = open(r"C:UserswwDesktophoutaiphp.txt","r")open_url = []all_url = []def search_url(url,txt): with open(r"C:UserswwDesktophoutaiphp.txt","r") as f : for each in f: each = each.replace('
','') urllist = url+each all_url.append(urllist) handle_url(urllist)def handle_url(urllist): print("查找:"+urllist+'
') try: req = urllib.urlopen(urllist) if req.getcode() == 200: open_url.append(urllist) if req.getcode() == 301: open_url.append(urllist) except: passdef main(): search_url(url,txt) if open_url: print("后台地址:") for each in open_url: print("[+]"+each) else: print("没有找到网站后台")if __name__ == "__main__": main() |

师傅让我多看看-->多线程
这里就加个多线程吧。

#!/usr/bin/python
#coding=utf-8
import sys
import urllib
import time
import threading
url = "http://123.207.123.228/"
txt = open(r"C:UserswwDesktophoutaiphp.txt","r")
open_url = []
all_url = []
threads = []
def search_url(url,txt):
with open(r"C:UserswwDesktophoutaiphp.txt","r") as f :
for each in f:
each = each.replace('
','')
urllist = url+each
all_url.append(urllist)
def handle_url(urllist):
print("查找:"+urllist+'
')
try:
req = urllib.urlopen(urllist)
if req.getcode() == 200:
open_url.append(urllist)
if req.getcode() == 301:
open_url.append(urllist)
except:
pass
def main():
search_url(url,txt)
for each in all_url:
t = threading.Thread(target = handle_url,args=(each,))
threads.append(t)
t.start()
for t in threads:
t.join()
if open_url:
print("后台地址:")
for each in open_url:
print("[+]"+each)
else:
print("没有找到网站后台")
if __name__ == "__main__":
start = time.clock()
main()
end = time.clock()
print("spend time is:%.3f seconds" %(end-start))
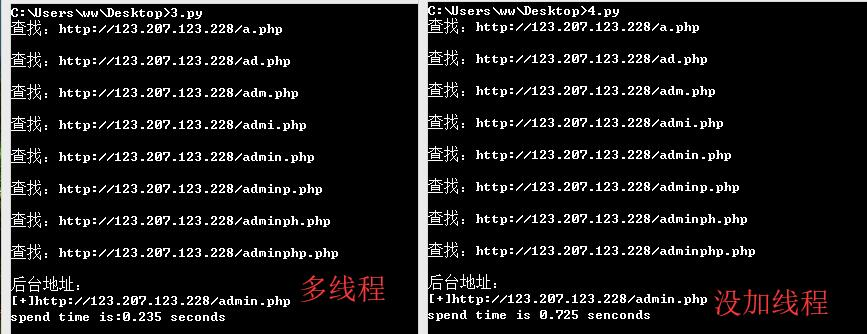
多线程和没加线程的时间对比
--------------------------------------------------------------------------------------------------------------------------------------------------
利用zoomeye搜索
调用ZoomEye API获取信息
主要涉及模块urllib,json,os模块。
# coding: utf-8
import os
import requests
import json
access_token = ''
ip_list = []
def login():
"""
输入用户米密码 进行登录操作
:return: 访问口令 access_token
"""
user = raw_input('[-] input : username :')
passwd = raw_input('[-] input : password :')
data = {
'username' : user,
'password' : passwd
}
data_encoded = json.dumps(data) # dumps 将 python 对象转换成 json 字符串
try:
r = requests.post(url = 'https://api.zoomeye.org/user/login',data = data_encoded)
r_decoded = json.loads(r.text) # loads() 将 json 字符串转换成 python 对象
global access_token
access_token = r_decoded['access_token']
except Exception,e:
print '[-] info : username or password is wrong, please try again '
exit()
def saveStrToFile(file,str):
"""
将字符串写如文件中
:return:
"""
with open(file,'w') as output:
output.write(str)
def saveListToFile(file,list):
"""
将列表逐行写如文件中
:return:
"""
s = '
'.join(list)
with open(file,'w') as output:
output.write(s)
def apiTest():
"""
进行 api 使用测试
:return:
"""
page = 1
global access_token
with open('access_token.txt','r') as input:
access_token = input.read()
# 将 token 格式化并添加到 HTTP Header 中
headers = {
'Authorization' : 'JWT ' + access_token,
}
# print headers
while(True):
try:
r = requests.get(url = 'https://api.zoomeye.org/host/search?query="phpmyadmin"&facet=app,os&page=' + str(page),
headers = headers)
r_decoded = json.loads(r.text)
# print r_decoded
# print r_decoded['total']
for x in r_decoded['matches']:
print x['ip']
ip_list.append(x['ip'])
print '[-] info : count ' + str(page * 10)
except Exception,e:
# 若搜索请求超过 API 允许的最大条目限制 或者 全部搜索结束,则终止请求
if str(e.message) == 'matches':
print '[-] info : account was break, excceeding the max limitations'
break
else:
print '[-] info : ' + str(e.message)
else:
if page == 10:
break
page += 1
def main():
# 访问口令文件不存在则进行登录操作
if not os.path.isfile('access_token.txt'):
print '[-] info : access_token file is not exist, please login'
login()
saveStrToFile('access_token.txt',access_token)
apiTest()
saveListToFile('ip_list.txt',ip_list)
if __name__ == '__main__':
main()
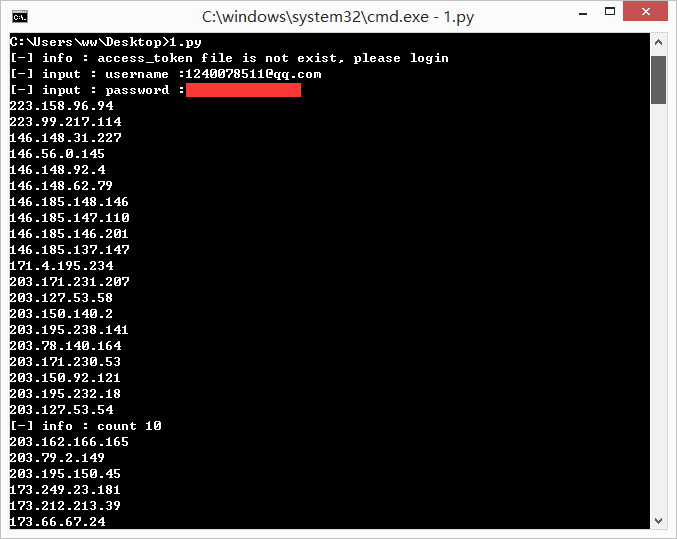
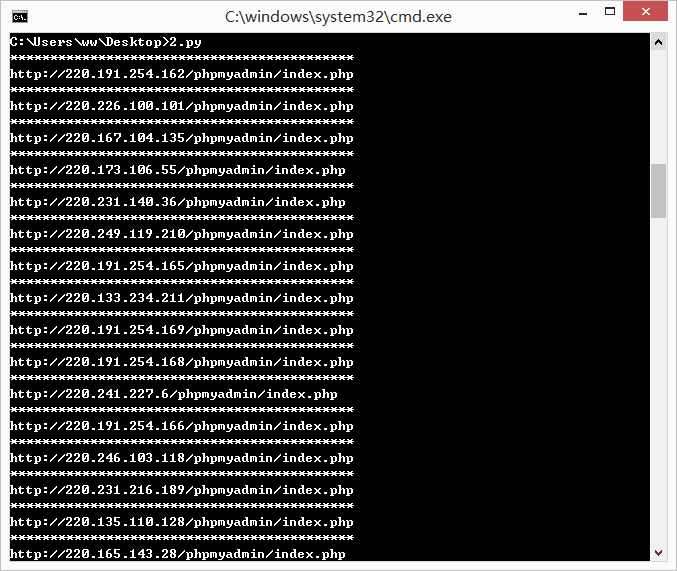
上面的脚本是搜索 phpmyadmin 的。搜索得到的 IP 会保存在同路径下的 ip_list.txt 文件。
但是搜索到的 ip 并不是都能够访问的,所以这里写个了识别 phpmyadmin 的脚本,判断是否存在,是则输出。
#!/usr/bin/python
#coding=utf-8
import sys
import time
import requests
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:56.0) Gecko/20100101 Firefox/56.0"}##浏览器请求头
open_url = []
all_url = []
payloa = 'http://'
payload = '/phpmyadmin/index.php'
def search_url():
with open(r"C:UserswwDesktopip_list.txt","r") as f :
for each in f:
each = each.replace('
','')
urllist = payloa+each+payload
all_url.append(urllist)
handle_url(urllist)
def handle_url(urllist):
#print('
'+urllist)
#print '----------------------------'
try:
start_htm = requests.get(urllist,headers=headers)
#print start_htm
if start_htm.status_code == 200:
print '*******************************************'
print urllist
except:
pass
if __name__ == "__main__":
search_url()
加个多线程,毕竟工作量很大。
#!/usr/bin/python
#coding=utf-8
import sys
import time
import requests
import threading
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:56.0) Gecko/20100101 Firefox/56.0"}##浏览器请求头
open_url = []
all_url = []
threads = []
payloa = 'http://'
payload = '/phpmyadmin/index.php'
def search_url():
with open(r"C:UserswwDesktopip_list.txt","r") as f :
for each in f:
each = each.replace('
','')
urllist = payloa+each+payload
all_url.append(urllist)
#handle_url(urllist)
def handle_url(urllist):
#print('
'+urllist)
#print '----------------------------'
try:
start_htm = requests.get(urllist,headers=headers)
#print start_htm
if start_htm.status_code == 200:
print '*******************************************'
print urllist
except:
pass
def main():
search_url()
for each in all_url:
t = threading.Thread(target=handle_url,args=(each,))
threads.append(t)
t.start()
for t in threads:
t.join()
if __name__ == "__main__":
start = time.clock()
main()
end = time.clock()
print("spend time is %.3f seconds" %(end-start))
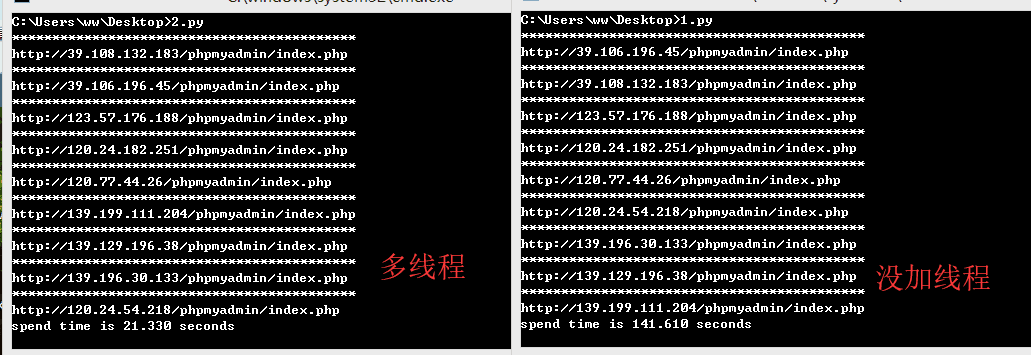
这下就方便了许多。
任重而道远!