解决JVM运行中的问题 一个案例理解常用工具 测试代码: /** * 从数据库中读取信用数据,套用模型,并把结果进行记录和传输 */ public class T15_FullGC_Problem01 { private static class CardInfo { BigDecimal price = new BigDecimal(0.0); String name = "张三"; int age = 5; Date birthdate = new Date(); public void m() {} } private static ScheduledThreadPoolExecutor executor = new ScheduledThreadPoolExecutor(50, new ThreadPoolExecutor.DiscardOldestPolicy()); public static void main(String[] args) throws Exception { executor.setMaximumPoolSize(50); for (;;){ modelFit(); Thread.sleep(100); } } private static void modelFit(){ List<CardInfo> taskList = getAllCardInfo(); taskList.forEach(info -> { // do something executor.scheduleWithFixedDelay(() -> { //do sth with info info.m(); }, 2, 3, TimeUnit.SECONDS); }); } private static List<CardInfo> getAllCardInfo(){ List<CardInfo> taskList = new ArrayList<>(); for (int i = 0; i < 100; i++) { CardInfo ci = new CardInfo(); taskList.add(ci); } return taskList; } } java -Xms200M -Xmx200M -XX:+PrintGC com.mashibing.jvm.gc.T15_FullGC_Problem01 一般是运维团队首先受到报警信息(CPU Memory) top命令观察到问题:内存不断增长 CPU占用率居高不下 top -Hp +pid观察进程中的线程,哪个线程CPU和内存占比高 jps定位具体java进程 jstack 定位线程状况,重点关注:WAITING BLOCKED jstack +PID

eg.
waiting on condition [0xe7f5a000] (a java.lang.Object) 假如有一个进程中100个线程,很多线程都在waiting on <xx> , 一定要找到是哪个线程持有这把锁

怎么找?搜索jstack dump的信息,找<xx> ,看哪个线程持有这把锁RUNNABLE
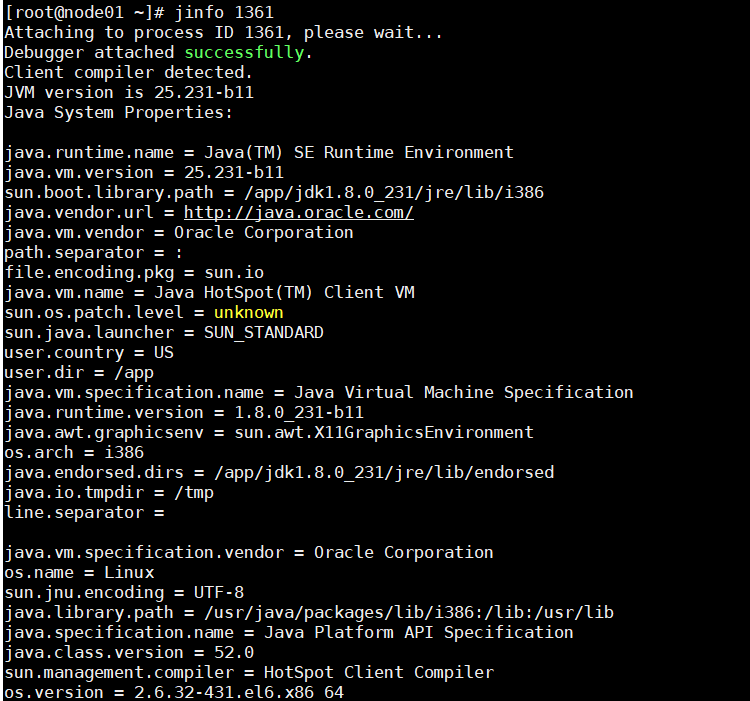
作业:1:写一个死锁程序,用jstack观察 2 :写一个程序,一个线程持有锁不释放,其他线程等待 为什么阿里规范里规定,线程的名称(尤其是线程池)都要写有意义的名称 怎么样自定义线程池里的线程名称?(自定义ThreadFactory) jinfo pid 查询虚拟机信息
jstat -gc 动态观察gc情况 / 阅读GC日志发现频繁GC / arthas观察 / jconsole/jvisualVM/ Jprofiler(最好用) jstat -gc 4655 500 :

每个500个毫秒打印GC的情况 如果面试官问你是怎么定位OOM问题的?如果你回答用图形界面(错误)
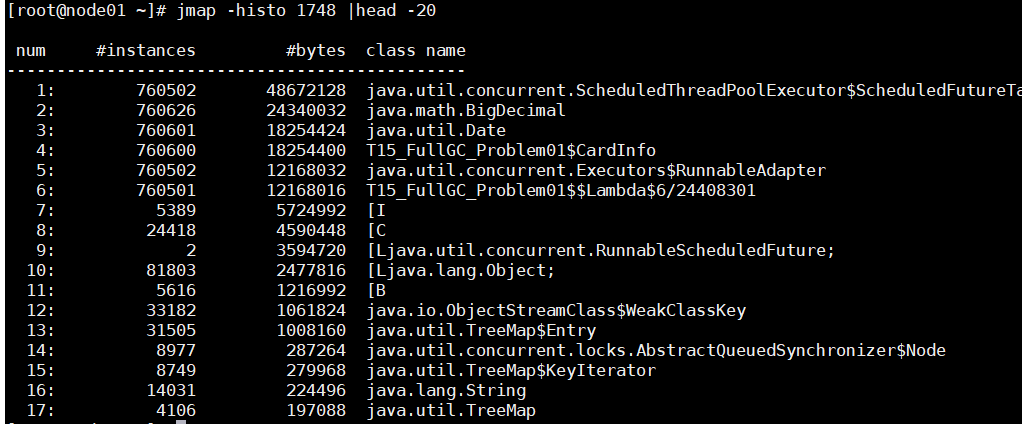
1:已经上线的系统不用图形界面用什么?(cmdline arthas) 2:图形界面到底用在什么地方?测试!测试的时候进行监控!(压测观察) jmap - histo 4655 | head -20,查找有多少对象产生
jmap -dump:format=b,file=xxx pid 1361:
-XX:HeapDumpPath=/x/x 配置jvm启动参数也可以dump 堆文件
线上系统,内存特别大,jmap -demp执行期间会对进程产生很大影响,甚至卡顿(电商不适合) 1:设定了参数HeapDump,OOM的时候会自动产生堆转储文件 2:很多服务器备份(高可用),停掉这台服务器对其他服务器不影响 3:在线定位(一般小点儿公司用不到) java -Xms20M -Xmx20M -XX:+UseParallelGC -XX:+HeapDumpOnOutOfMemoryError T15_FullGC_Problem01 使用MAT / jhat /jvisualvm 进行dump文件分析 https://www.cnblogs.com/baihuitestsoftware/articles/6406271.html jhat -J-mx512M xxx.dump http://192.168.17.11:7000 拉到最后:找到对应链接 可以使用OQL查找特定问题对象 找到代码的问题 问题分析流程: 慢,CPU飙高->top->Jps->Jstack->Jmap jconsole远程连接 程序启动加入参数: java -Djava.rmi.server.hostname=192.168.65.10 -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=11111 -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -XX:+PrintGC -Xms200M -Xmx200M T15_FullGC_Problem01 如果遭遇 Local host name unknown:XXX的错误,修改/etc/hosts文件,把XXX加入进去 192.168.65.10 basic localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 关闭linux防火墙(实战中应该打开对应端口) service iptables stop chkconfig iptables off #永久关闭 windows上打开 jconsole远程连接 192.168.17.11:11111
jvisualvm远程连接
https://www.cnblogs.com/liugh/p/7620336.html (简单做法)
arthas在线排查工具 § 启动arthas java -jar arthas-boot.jar § 绑定java进程 § dashboard命令观察系统整体情况 § help 查看帮助 § help xx 查看具体命令帮助 § https://www.jianshu.com/p/507f7e0cc3a3

为什么需要在线排查?
在生产上我们经常会碰到一些不好排查的问题,例如线程安全问题,用最简单的threaddump或者 heapdump不好查到问题原因。为了排查这些问题,有时我们会临时加一些日志,比如在一些关键的函数里打印出入参,然后重新打包发布,如果打了日志还是没找到问题,继续加日志,重新打包发布。对于上线流程复杂而且审核比较严的公司,从改代码到上线需要层层的流转,会大大影响问题排查的进度。 jvm观察jvm信息 thread定位线程问题 thread + ID
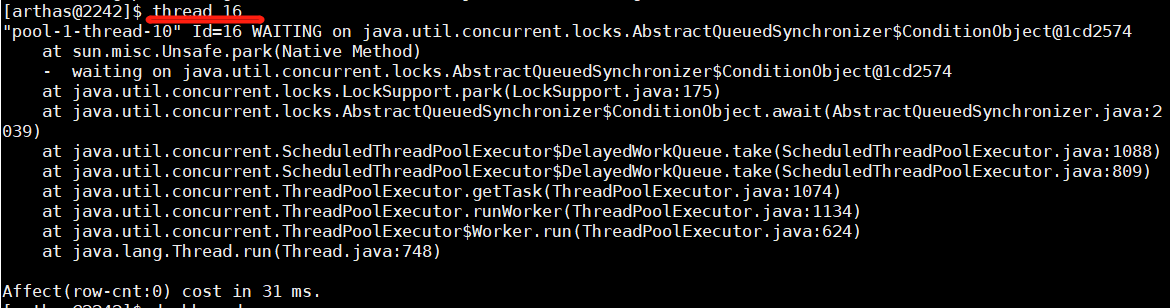
dashboard 观察系统情况
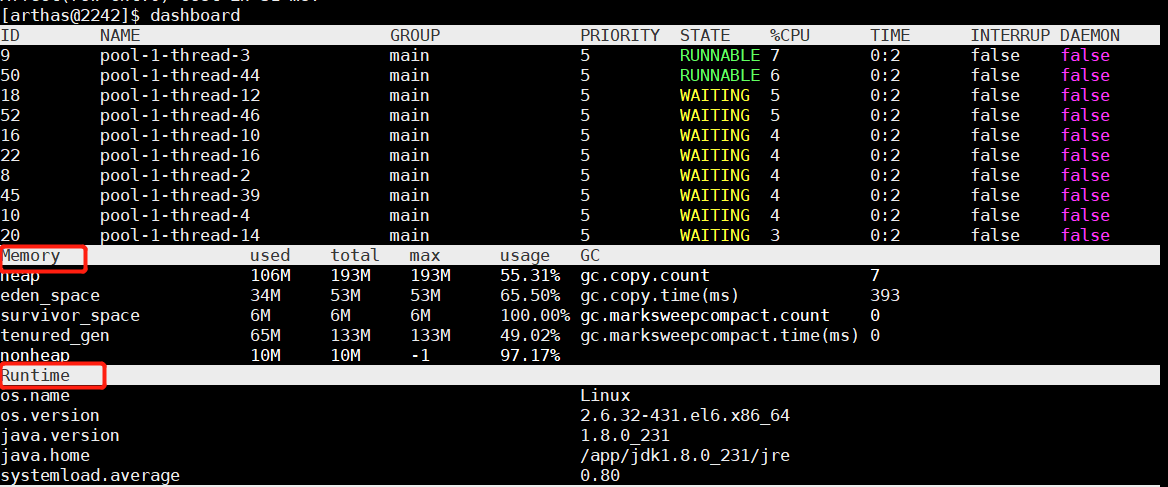
heapdump + jhat分析 完成之后ip+7000端口访问
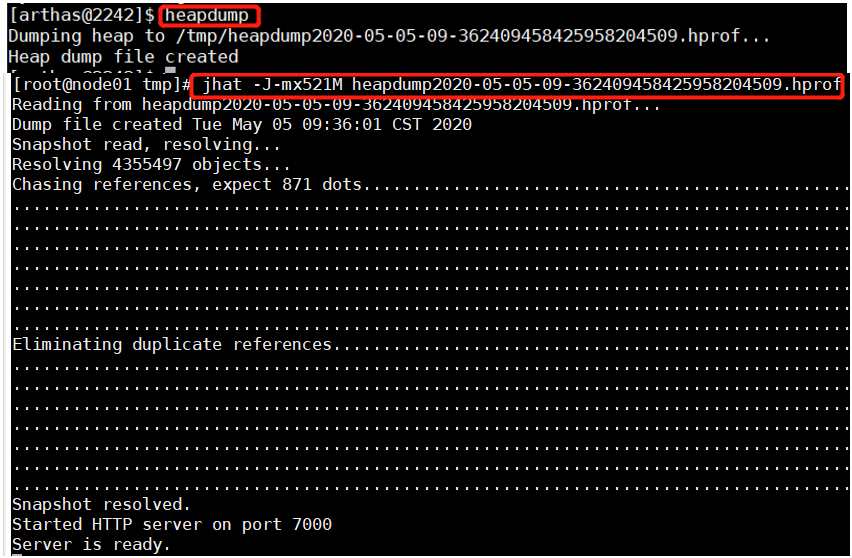
jad反编译
动态代理生成类的问题定位
第三方的类(观察代码)
版本问题(确定自己最新提交的版本是不是被使用)
redefine 热替换
目前有些限制条件:只能改方法实现(方法已经运行完成),不能改方法名, 不能改属性 m() -> mm() 直接线上修改源文件方法内容,完成后重新编译,最后redefine重新替换

sc - search class
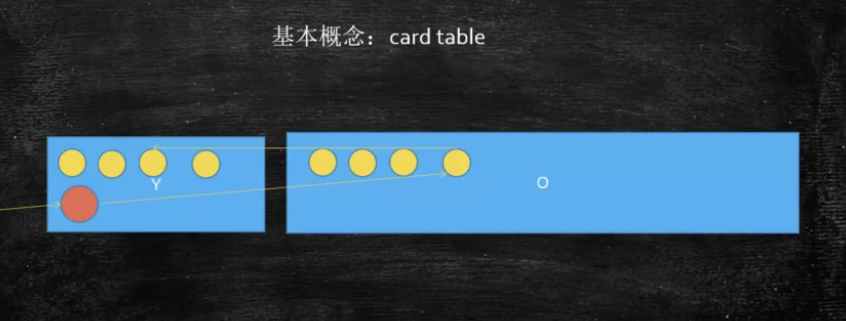
watch - watch method 没有包含的功能:jmap 案例汇总 OOM产生的原因多种多样,有些程序未必产生OOM,不断FGC(CPU飙高,但内存回收特别少) (上面案例) 1. 硬件升级系统反而卡顿的问题(见上) 2. 线程池不当运用产生OOM问题(见上) 不断的往List里加对象(实在太LOW) 3. smile jira问题 实际系统不断重启 解决问题 加内存 + 更换垃圾回收器 G1 真正问题在哪儿?不知道 4. tomcat http-header-size过大问题(Hector) 5. lambda表达式导致方法区溢出问题(MethodArea / Perm Metaspace) LambdaGC.java -XX:MaxMetaspaceSize=9M -XX:+PrintGCDetails 6. 直接内存溢出问题(少见) 《深入理解Java虚拟机》P59,使用Unsafe分配直接内存,或者使用NIO的问题 7. 栈溢出问题 -Xss设定太小 8. 比较一下这两段程序的异同,分析哪一个是更优的写法: Object o = null; for(int i=0; i<100; i++) { o = new Object(); //业务处理 } for(int i=0; i<100; i++) { Object o = new Object(); } 9. 重写finalize引发频繁GC 小米云,HBase同步系统,系统通过nginx访问超时报警,最后排查,C++程序员重写finalize引发频繁GC问题 为什么C++程序员会重写finalize?(new 析构函数 delete) finalize耗时比较长(200ms) 10. 如果有一个系统,内存一直消耗不超过10%,但是观察GC日志,发现FGC总是频繁产生,会是什么引起的? System.gc() (这个比较Low) 11. Distuptor有个可以设置链的长度,如果过大,然后对象大,消费完不主动释放,会溢出 (来自 死物风情) 12. 用jvm都会溢出,mycat用崩过,1.6.5某个临时版本解析sql子查询算法有问题,9个exists的联合sql就导致生成几百万的对象(来自 死物风情) 13. new 大量线程,会产生 native thread OOM,(low)应该用线程池, 解决方案:减少堆空间(太TMlow了),预留更多内存产生native thread JVM内存占物理内存比例 50% - 80% G1详解 特点: 并发收集 压缩空闲空间不会延长GC的暂停时间; 更易预测的GC暂停时间; 适用不需要实现很高的吞吐量的场景 分区: ○ 每个分区都可能是年轻代也可能是老年代,但是在同一时刻只能属于某个代。 ○ 年轻代、幸存区、老年代这些概念还存在,成为逻辑上的概念,这样方便复用之前分代框架的逻辑。在物理上不需要连续,则带来了额外的好处一有 的分区内垃圾对象特别多,有的分区内垃圾对象很少,G1会优先回收垃圾对象特别多的分区,这样可以花费较少的时间来回收这些分区的垃圾,这也就是G1名字的由来,即首先收集垃圾最多的分区。 ○ 新生代其实并不是适用于这种算法的,依然是在新生代满了的时候,对整个新生代进行回收一整个新生代中的对象,要么被回收、要么晋升,至于新生代也采取分区机制的原因,则是因为这样跟老年代的策略统一, 方便调整代的大小. ○ G1还是一种带 压缩的收集器,在回收老年代的分区时, 是将存活的对象从一个分区拷贝到另一个可用分区,这个拷贝的过程就实现了局部的压缩。每个分区的大小从1M到,32M不等,但是都是2的冥次方。 ○ G1的内存区域不是固定的E或者O,肯在这个阶段是E,在另一个阶段又是O Card Table 由于做YGC时,需要扫描整个OLD区,效率非常低,所以JVM设计了CardTable, 如果一个OLD区CardTable中有对象指向Y区,就将它设为Dirty,下次扫描时, 只需要扫描Dirty Card 在结构上,Card Table用BitMap来实现
CSet(Collection Set)
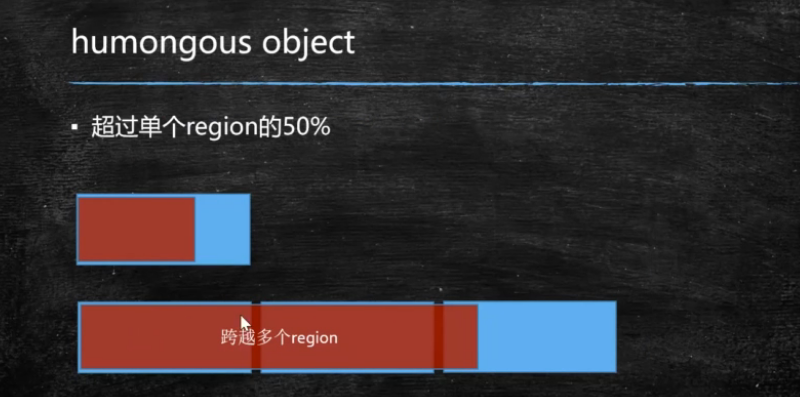
一组可被回收的分区的集合。 在CSet中存活的数据会在GC过程中被移动到另一个可用分区, CSet中的分区可以来自Eden空间、survivor空间、 或者老年代。 CSet会占用不到整个堆空间的1%大小。 RSet (RememberedSet) 记录了其他Region中的对象到本Region的引用 RSet的价值在于 使得垃圾收集器不需要扫描整个堆找到谁引用了当前分区中的对象,只需要扫描RSet即可。 每个region有多大 取值范围: 1 2 4 8 16 32 humongous object 超过单个region的50% 跨越多个region
G1 GC何时触发
YGC Eden空间不足 多线程并行执行 FGC Old空间不足 System.gc() MixedGC(类似CMS) XX:InitiatingHeapOccupacyPercent 默认值45% 当0超过这个值时,启动MixedGC MixedGC的过程 初始标记STW 并发标记 最终标记STW (重新标记) 筛选回收STW (并行) 三色标记算法 并发阶段标记算法 (三色标记,颜色指针) 并发标记算法难点:在标记过程中,对象引用关系正在发生改变(浮动垃圾) 三色标记法 定义: 白色:未被标记的对象 灰色:自身被标记,成员变量未被标记 黑色:自身和成员变量均已标记完成 漏标 在remark过程中,黑色指向了白色,如果不对黑色重新扫描,则会漏标 会把白色D对象当做没有新引用指向从而回收掉并发标记过程中,Mutator删除 了 所有从灰色到白色的引用,会产生漏标此时白色对象应该被回收 漏标案例: A(黑):自己已经标记,fields 都标记完成 B(灰):自己标记完成,还没来得及标记fields C(灰):自己标记完成,还没来得及标记fields D(白):没有遍历到的节点 产生漏标: 1.标记进行时增加了一个黑到白的引用,如果不重新对黑色进行处理,则会漏标 2.标记进行时删除了灰对象到白对象的引用,那么这个白对象有可能被漏标 解决漏标: 打破以下两个条件之一即可 1. incremental update增量更新,关注引用的增加, 把黑色重新标记为灰色,下次重新扫描属性 2. SATB (snapshot at the beginning)-关注引用的删除 当B->D消失时,要把这个引用推到GC的堆栈,保证D还能被GC描到 CMS用第一种,G1用第二种 为什么G1用SATB? □ 灰色-->白色引用消失时,如果没有黑色指向白色引用会被push到堆栈 □ 下次扫描时拿到这个引用,由于有RSet的存在,不需要扫描整个堆去查找指向白色的引用,效率比较高 □ SATB配合RSet,浑然天成 为什么选择G1 ○ 追求吞吐量 § 100 cpu § 99 app 1 GC § 吞吐量= 99% ○ 追求响应时间 § - XX:MaxGCPauseMillis 200 § 对STW进行控制 ○ 灵活 § 分Region回收 § 优先回收花费时间少、垃圾比例高的Region GC常用参数 • -Xmn -Xms -Xmx -Xss ○ 年轻代 初始堆 最大堆 栈空间 • -XX:+UseTLAB ○ 使用TLAB,默认打开 • -XX:+PrintTLAB ○ 打印TLAB的使用情况 • -XX:TLABSize ○ 设置TLAB大小 • -XX:+DisableExplictGC ○ System.gc()不管用 ,FGC • -XX:+PrintGC • -XX:+PrintGCDetails • -XX:+PrintHeapAtGC • -XX:+PrintGCTimeStamps • -XX:+PrintGCApplicationConcurrentTime (低) ○ 打印应用程序时间 • -XX:+PrintGCApplicationStoppedTime (低) ○ 打印暂停时长 • -XX:+PrintReferenceGC (重要性低) ○ 记录回收了多少种不同引用类型的引用 • -verbose:class ○ 类加载详细过程 • -XX:+PrintVMOptions • -XX:+PrintFlagsFinal -XX:+PrintFlagsInitial ○ 必须会用 • -Xloggc:opt/log/gc.log • -XX:MaxTenuringThreshold ○ 升代年龄,最大值15 • 锁自旋次数 -XX:PreBlockSpin 热点代码检测参数-XX:CompileThreshold 逃逸分析 标量替换 ... ○ 这些不建议设置 Parallel常用参数 • -XX:SurvivorRatio • -XX:PreTenureSizeThreshold ○ 大对象到底多大 • -XX:MaxTenuringThreshold • -XX:+ParallelGCThreads ○ 并行收集器的线程数,同样适用于CMS,一般设为和CPU核数相同 • -XX:+UseAdaptiveSizePolicy ○ 自动选择各区大小比例 CMS常用参数 • -XX:+UseConcMarkSweepGC • -XX:ParallelCMSThreads ○ CMS线程数量 • -XX:CMSInitiatingOccupancyFraction ○ 使用多少比例的老年代后开始CMS收集,默认是68%(近似值),如果频繁发生SerialOld卡顿,应该调小,(频繁CMS回收) • -XX:+UseCMSCompactAtFullCollection ○ 在FGC时进行压缩 • -XX:CMSFullGCsBeforeCompaction ○ 多少次FGC之后进行压缩 • -XX:+CMSClassUnloadingEnabled • -XX:CMSInitiatingPermOccupancyFraction ○ 达到什么比例时进行Perm回收 • GCTimeRatio ○ 设置GC时间占用程序运行时间的百分比 • -XX:MaxGCPauseMillis ○ 停顿时间,是一个建议时间,GC会尝试用各种手段达到这个时间,比如减小年轻代 G1常用参数 • -XX:+UseG1GC • -XX:MaxGCPauseMillis ○ 建议值,G1会尝试调整Young区的块数来达到这个值 • -XX:GCPauseIntervalMillis ○ GC的间隔时间 • -XX:+G1HeapRegionSize ○ 分区大小,建议逐渐增大该值,1 2 4 8 16 32。 随着size增加,垃圾的存活时间更长,GC间隔更长,但每次GC的时间也会更长 ZGC做了改进(动态区块大小) • G1NewSizePercent ○ 新生代最小比例,默认为5% • G1MaxNewSizePercent ○ 新生代最大比例,默认为60% • GCTimeRatio ○ GC时间建议比例,G1会根据这个值调整堆空间 • ConcGCThreads ○ 线程数量 • InitiatingHeapOccupancyPercent ○ 启动G1的堆空间占用比例 练习题 1. -XX:MaxTenuringThreshold控制的是什么? A: 对象升入老年代的年龄 B: 老年代触发FGC时的内存垃圾比例 2. 生产环境中,倾向于将最大堆内存和最小堆内存设置为:(为什么?) A: 相同 B:不同 3. JDK1.8默认的垃圾回收器是: A: ParNew + CMS B: G1 C: PS + ParallelOld D: 以上都不是 4. 什么是响应时间优先? 5. 什么是吞吐量优先? 6. ParNew和PS的区别是什么? 7. ParNew和ParallelOld的区别是什么?(年代不同,算法不同) 8. 长时间计算的场景应该选择:A:停顿时间 B: 吞吐量 9. 大规模电商网站应该选择:A:停顿时间 B: 吞吐量 10. HotSpot的垃圾收集器最常用有哪些? 11. 常见的HotSpot垃圾收集器组合有哪些? 12. JDK1.7 1.8 1.9的默认垃圾回收器是什么?如何查看? 13. 所谓调优,到底是在调什么? 14. 如果采用PS + ParrallelOld组合,怎么做才能让系统基本不产生FGC 15. 如果采用ParNew + CMS组合,怎样做才能够让系统基本不产生FGC 1.加大JVM内存 2.加大Young的比例 3.提高Y-O的年龄 4.提高S区比例 5.避免代码内存泄漏 16. G1是否分代?G1垃圾回收器会产生FGC吗? 17. 如果G1产生FGC,你应该做什么? 1. 扩内存 2. 提高CPU性能(回收的快,业务逻辑产生对象的速度固定,垃圾回收越快,内存空间越大) 3. 降低MixedGC触发的阈值,让MixedGC提早发生(默认是45%) 18. 问:生产环境中能够随随便便的dump吗? 1. 小堆影响不大,大堆会有服务暂停或卡顿(加live可以缓解),dump前会有FGC 19. 问:常见的OOM问题有哪些? 1. 栈 堆 MethodArea 直接内存 参考资料: 1. https://blogs.oracle.com/jonthecollector/our-collectors 2. https://docs.oracle.com/javase/8/docs/technotes/tools/unix/java.html 3. http://java.sun.com/javase/technologies/hotspot/vmoptions.jsp 4. JVM调优参考文档:https://docs.oracle.com/en/java/javase/13/gctuning/introduction-garbage-collection-tuning.html#GUID-8A443184-7E07-4B71-9777-4F12947C8184 5. https://www.cnblogs.com/nxlhero/p/11660854.html 在线排查工具 6. https://www.jianshu.com/p/507f7e0cc3a3 arthas常用命令 7. Arthas手册: 1. 启动arthas java -jar arthas-boot.jar 2. 绑定java进程 3. dashboard命令观察系统整体情况 4. help 查看帮助 5. help xx 查看具体命令帮助 8. jmap命令参考: https://www.jianshu.com/p/507f7e0cc3a3 1. jmap -heap pid 2. jmap -histo pid 3. jmap -clstats pid
CMS日志分析
执行命令:java -Xms20M -Xmx20M -XX:+PrintGCDetails -XX:+UseConcMarkSweepGC T15_FullGC_Problem01
[GC (Allocation Failure) [ParNew: 6144K->640K(6144K), 0.0265885 secs] 6585K->2770K(19840K), 0.0268035 secs] [Times: user=0.02 sys=0.00, real=0.02 secs]
ParNew:年轻代收集器
6144->640:收集前后的对比
(6144):整个年轻代容量
6585 -> 2770:整个堆的情况
(19840):整个堆大小
[GC (CMS Initial Mark) [1 CMS-initial-mark: 7350K(13696K)] 9033K(19840K), 0.0018277 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
//7350K(13696K) : 老年代使用(最大)
//9033K(19840K) : 整个堆使用(最大)
[CMS-concurrent-mark-start]
[CMS-concurrent-mark: 0.012/0.012 secs] [Times: user=0.01 sys=0.00, real=0.01 secs]
//这里的时间意义不大,因为是并发执行
[CMS-concurrent-preclean-start]
[CMS-concurrent-preclean: 0.004/0.004 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
//标记Card为Dirty,也称为Card Marking
[GC (CMS Final Remark) [YG occupancy: 1682 K (6144 K)][Rescan (parallel) , 0.0015702 secs][weak refs processing, 0.0000247 secs][class unloading, 0.0004549 secs][scrub symbol table, 0.0006202 secs][scrub string table, 0.0000321 secs][1 CMS-remark: 7350K(13696K)] 9033K(19840K), 0.0028101 secs] [Times: user=0.01 sys=0.00, real=0.01 secs]
//STW阶段,YG occupancy:年轻代占用及容量
//[Rescan (parallel):STW下的存活对象标记
//weak refs processing: 弱引用处理
//class unloading: 卸载用不到的class
//scrub symbol(string) table:
//cleaning up symbol and string tables which hold class-level metadata and
//internalized string respectively
//CMS-remark: 8511K(13696K): 阶段过后的老年代占用及容量
//10108K(19840K): 阶段过后的堆占用及容量
[CMS-concurrent-sweep-start]
[CMS-concurrent-sweep: 0.004/0.004 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
//标记已经完成,进行并发清理
[CMS-concurrent-reset-start]
[CMS-concurrent-reset: 0.000/0.000 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
//重置内部结构,为下次GC做准备
G1日志详解
执行命令:java -Xms20M -Xmx20M -XX:+PrintGCDetails -XX:+UseG1GC T15_FullGC_Problem01
[GC pause (G1 Evacuation Pause) (young), 0.0016743 secs]
//young -> 年轻代 Evacuation-> 复制存活对象
//initial-mark 混合回收的阶段,这里是YGC混合老年代回收
[Parallel Time: 1.6 ms, GC Workers: 1]//一个GC线程
[GC Worker Start (ms): 105.0]
[Ext Root Scanning (ms): 0.6]
[Update RS (ms): 0.0]
[Processed Buffers: 0]
[Scan RS (ms): 0.0]
[Code Root Scanning (ms): 0.0]
[Object Copy (ms): 0.7]
[Termination (ms): 0.0]
[Termination Attempts: 1]
[GC Worker Other (ms): 0.0]
[GC Worker Total (ms): 1.4]
[GC Worker End (ms): 106.4]
[Code Root Fixup: 0.0 ms]
[Code Root Purge: 0.0 ms]
[Clear CT: 0.0 ms]
[Other: 0.1 ms]
[Choose CSet: 0.0 ms]
[Ref Proc: 0.0 ms]
[Ref Enq: 0.0 ms]
[Redirty Cards: 0.0 ms]
[Humongous Register: 0.0 ms]
[Humongous Reclaim: 0.0 ms]
[Free CSet: 0.0 ms]
[Eden: 3072.0K(3072.0K)->0.0B(3072.0K) Survivors: 0.0B->1024.0K Heap: 3072.0K(20.0M)->496.1K(20.0M)]
[Times: user=0.00 sys=0.00, real=0.00 secs]
//以下是混合回收其他阶段
[GC concurrent-root-region-scan-start]
[GC concurrent-root-region-scan-end, 0.0000062 secs]
[GC concurrent-mark-start]
//无法evacuation,进行FGC
[Full GC (Allocation Failure) 18M->18M(20M), 0.0591118 secs]
[Eden: 0.0B(1024.0K)->0.0B(1024.0K) Survivors: 0.0B->0.0B Heap: 18.8M(20.0M)->18.8M(20.0M)], [Metaspace: 2456K->2456K(4400K)]
[Times: user=0.06 sys=0.00, real=0.06 secs]