记录对《基于深度学习的自然语言处理》书籍的总结。
常见的文本处理技术:
- 小写/大写转换
- 去噪
- 文本规范化
- 词干提取
- 词形还原
- 标记化
- 删除停用词
1:使用lower进行大写转小写,upper转为大写
s = "I am a boy" s = s.lower() print(s) list = ["I", "am","IIU","HHH"] words = [word.lower() for word in list] print(words)
2:去噪处理,去除句子里面多余的字符
import re def clean_words(text): text = re.sub("(<.*?>)","",text) text = re.sub("(W|d+)","",text) text = text.strip() return text print(clean_words("<hahah>123boy "))
3:文本规范化是指文本输入在被分析,处理和操作之前保证一致,将缩写映射到完整形式,将同一个单词的多个拼写转为单词的一个拼写。如UK变为unitedkingdom
4:词干提取
在语料库上执行词干提取将赐予减少到词干或词根的形式。如过去式,进行时,第三人称单数变为根形式。nltk的stem的PorterStemmer实现了对词干的提取功能
import pandas import nltk from nltk.stem import PorterStemmer as ps stemmer = ps() words = ["annoying","annoys","annoyed","","annoy"] stems = [stemmer.stem(word=word) for word in words] sdf = pandas.DataFrame({'raw word':words,'stem':stems}) print(sdf)
5:词形还原
类似于词干提取,不过是将词转为根的形式,如good变为better,进行词性还原后变为better,best变为good
from nltk.stem import WordNetLemmatizer as wnl nltk.download('wordnet')#英语语言数据库 lemmatizer = wnl() lemmatized = [lemmatizer.lemmatize(word = word,pos = "v") for word in ["troubing","troubled","troubles","trouble"]] print(pandas.DataFrame({"raw word":words,"lemmatized":lemmatized}))
6:标记化
执行标记化使单个单词和单个句子作为标记,自然语言处理中是把处理后的标记作为输入的
import nltk nltk.download("punkt") from nltk import word_tokenize s = "hi! i am very happy to see every one" tokens = word_tokenize(s) print(tokens)
7去停用词
从语料库中删除嘈杂的单词,如:the,this,IT,等
nltk.download("stopwords") s = "the feather is very beautiful" from nltk.corpus import stopwords stop_words = set(stopwords.words('english')) tokens = word_tokenize(s) tokens = [word for word in tokens if not word in stop_words] print(tokens)
自然语言处理(NLP)之词嵌入(word embedding)
词嵌入(word embedding) 是在自然语言处理中广泛使用的一个手段,在概念上而言,是指把一个维数为所有词的数量的高维空间嵌入到一个维数低得多的连续向量空间中(降维思想),每个单词或词组(甚至更粗粒度,如文档)被映射为实数域上的向量。(将词转化为计算机能够处理的数值向量)
即:f(x)–>y [其中x为非数值的词,y为实数域上的一个向量]
一.NLP的几种词的表示方式
1.one-hot representation(独热表示):思想比较简单,即对于有n个不同词的集合,建立一个长度为n的一维向量,对每个词,其向量都只有一个1且位置唯一不共享,其余均为0。
例如:语料库中词为:我,你,他;则词的总数量为n=3
则建立一维向量:我=[1,0,0],你=[0,1,0],他=[0,0,1]
其实现较为简单方便,但存在一些处理时的缺点:
(1)向量的维度会随着词的数量类型增大而增大,对于一个庞大的语料库,这可能是内存无法承受的。
(2)任意两个词之间都是相互孤立的,无法表示在语义层面上词之间的相关信息。这对于一些NLP的处理任务来说是极大的缺点。
2.distributed representation(分布式表示):这里面又有很多种表示方法,包括人工神经网络、对词语同现矩阵降维、概率模型以及单词所在上下文的显式表示等,核心是通过上下文的表示以及上下文与目标词之间的关系的建模,过矩阵降维或神经网络降维将语义分散存储到向量的各个维度中,这两类方法得到的向量空间是低维的一般都可以称作分布式表示,又称为词嵌入(word embedding)或词向量)。分布式表示的一个解释
二.word embedding
词向量,或词嵌入,一般来说主要讲基于神经网络得到的分布表示。
其主要优点为:
(1)在维度较小的实数域上的词表示弥补了one-hot编码的巨大维度问题,实现了数据降维;
(2)可以通过相似的向量表示得到词之间存在的相似关系。
三.词嵌入的几种实现
词嵌入的提出已经有一段历史了,随着时间的推移不断有新的模型出现。
有CBOW( Continuous Bagof-Words,连续词袋模型),其通过上下文来预测当前词;
Skip-gram 模型,功能恰恰相反,其从当前词得到上下文。

之后,google的托马斯·米科洛维借助类似的思想得到的著名的Word2vec、Stanford University的GloVe和Deeplearning4j模型都具有很好的词嵌入效果。
在word2vec出现之前,已经有用神经网络DNN来用训练词向量进而处理词与词之间的关系了。采用的方法一般是一个三层的神经网络结构(当然也可以多层),分为输入层,隐藏层和输出层(softmax层)。word2vec也使用了CBOW与Skip-Gram来训练模型与得到词向量,但是并没有使用传统的DNN模型。最先优化使用的数据结构是用霍夫曼树来代替隐藏层和输出层的神经元,霍夫曼树的叶子节点起到输出层神经元的作用,叶子节点的个数即为词汇表的小大。 而内部节点则起到隐藏层神经元的作用。来提高速度,但是霍夫曼树对于罕见词的编码太长因此又引入了负采样的方法,关于这部分的介绍可以看下这三篇博客:
word2vec原理(一) CBOW与Skip-Gram模型基础
word2vec原理(二) 基于Hierarchical Softmax的模型
word2vec原理(三) 基于Negative Sampling的模型
word2ec缺点是使用窗口内的值做预测,因此无法从全局进行预测,glove则是通过查看语料库中的全部词进行共线计数矩阵来进行降维学习。
共线计数矩阵的定义如下
1.概论
语言的语义向量空间模型用实值向量表示每个单词。这些向量可以用作各种应用中的特征,例如信息检索(Manning等,2008),文档分类(Sebastiani,2002),问题回答(Tellex等,2003),名称识别(Turianetal。, 2010)和解析(Socher等,2013)。大多数单词矢量方法依赖于单词矢量对之间的距离或角度,作为评估这样一组单词表示的内在质量的主要方法。最近,Mikolov等人。 (2013c)引入了一种基于词类比探测的新评估方案单词矢量空间的细胞结构通过检查两个矢量之间的差异,而不是它们各种各样的差异维度。例如,类比“国王是女王,男人是女人”,应该在矢量空间中通过矢量方程式王 - 女王=男女来编码。该评估方案倾向于产生意义维度的模型,从而捕获分布式表示的多聚类思想(Bengio,009)。
学习词向量有两大方法:1)全局矩阵分解方法,比如LSA,2)本地文本窗口,比如skip-gram模型。这些方法都有缺点,LSA可以很好获得统计信息,但对于词的相似度任务比较差,skip-gram对于相似度任务很好,但对于使用语料的统计信息比较差,这是因为他们训练在局部上下文窗口而不是全局共现对。
Glove模型表示的语义词向量相似度尽可能接近在统计共现矩阵中统计相似度,并且不同共现的词有不同权值。
。式子左边是向量相似度函数,右边是全局的共现统计值。
from gensim.models import Word2Vec as wtv from nltk import word_tokenize s1 = "hello, i am a boy love swimming" s2 ="what a pity." s3= "i like to swim" sentences = [word_tokenize(s1),word_tokenize(s2),word_tokenize(s3)] model = wtv(sentences,min_count = 1) print(model) print(list(model.wv.vocab)) a = model.wv.most_similar(positive=["like"],topn=6) print(a)
2.Glove模型
2.1 共现矩阵
无监督学习从语料中习得词向量(word vector)的一个比较通用的方式是首先从语料中统计词的共现(word occurrences)率。统计共现率时需先设定一个窗口大小(window size)。窗口中心在语料中从左向右滑动。窗口的中心对应的词叫中心词(center word),中心左右两边的窗口内的词叫语境词(context word)。
例如window size为5,语料为how to travel from singapore to johor的center word与context word的统计:

上面统计可知:X(to|from) = 2 ,X(from|to) = 2。
2.2相关记号
:表示单词
中心词,单词
出现的次数。例如
表示单词
中心词的次数。例如
表示单词
作为中心词时,单词
出现的概率。例如:
。
通过大量统计, ,
存在如下关系:
假如 都和
相关,或者和
不相关,则
的值接近于1。如果k和i相关,k与j不相关,则
。如果k和i的关系不相关,k与j的关系相关,则
接近于0。
一个具体的例子如下:
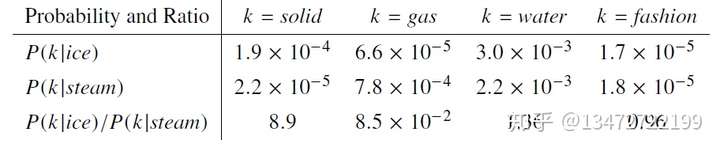
ice和solid相关,steam与gas相关,ice和steam与water都相关,ice和steam与fashion都不相关。
更多详细的推导可以看:https://zhuanlan.zhihu.com/p/80335195
import itertools from gensim.models.word2vec import Text8Corpus from glove import Corpus,Glove sentences = list(itertools.islice(Text8Corpus('text8'),None)) corpus = Corpus() corpus.fit(sentences,window = 10) glove = Glove(no_components = 100,learning_rate=0.05) glove.fit(corpus.matrix,epochs=30,no_threads=4,verbose=True) glove.add_dictionary(corpus.dictionary) glove.most_similar("man",number=2)