所有操作在虚拟机下完成,虚拟机软件选用VMware Workstation Pro 12 (后文简称为VM)
关于Linux安装不再阐述
一、网络环境配置
1)Windows界面
首先在VM页面,点击虚拟网络编辑器
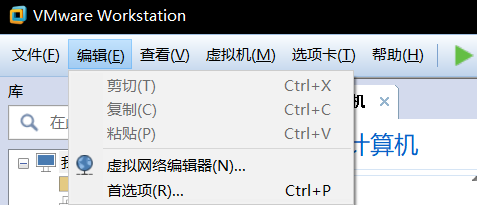
进入后把vmnet8改为nat模式

次之,点击上图红框右边的NAT设置网关,前缀随意,记得数字1结尾
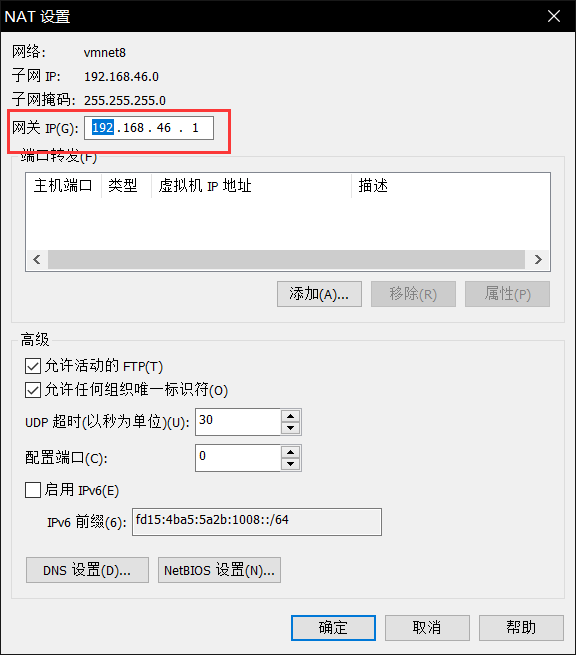
然后修改子网IP,要求在网段内
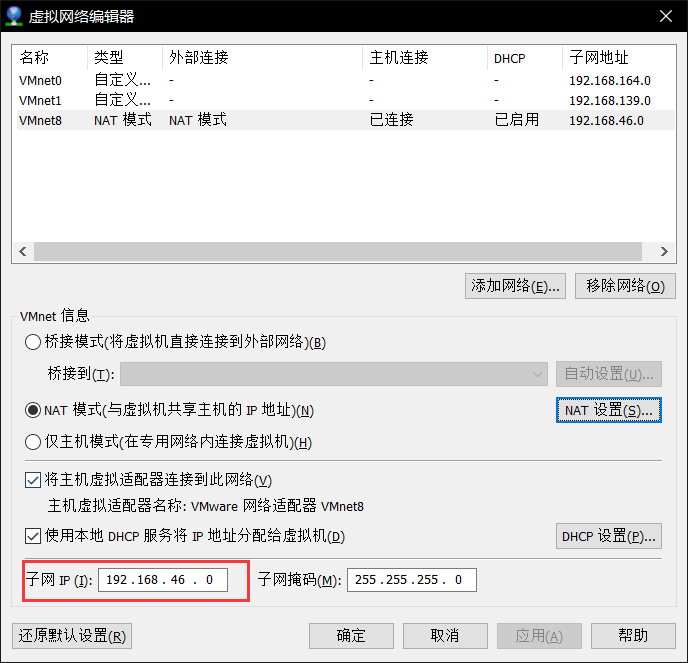
继而设置本机的vmnewt8,博主为windows10
在网络连接设置中
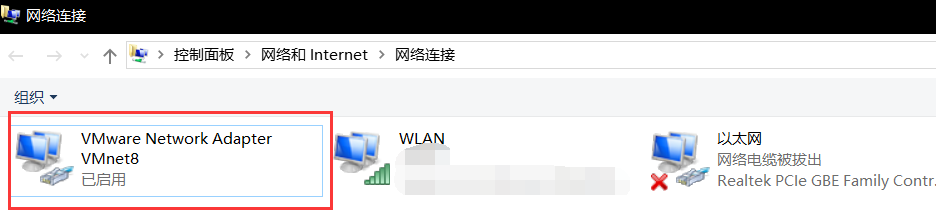
设置ipv4,双击即可
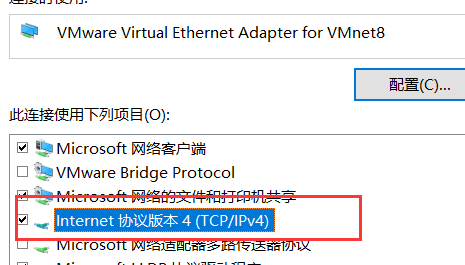
设置与刚才虚拟机设置的ip为统一网段内
2)Linux界面
setup指令,进入设置伪图形界面
选择网络设置


选择当前虚拟网卡(当前我的系统下只有一块虚拟网卡,最多可以有8块)
进入
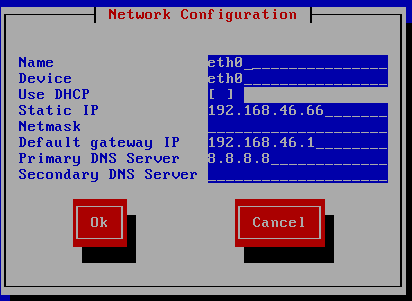
从上至下为
网卡名字、网卡设备、是否自动获取(若自动获取DHCP中为*)、IP地址、子网掩码、默认网关、DNF服务器、备用DNS服务器
设置完毕后退出,然后重启网关
重启指令为 sudo service network restart

然后cmd下测试
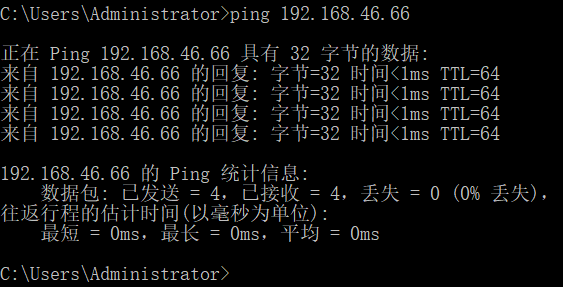 、
、
成功
网络配置到此结束
二、软件环境配置
由此开始不再在linux虚拟机上直接操作,使用SecureCRTPortable进行远程连接
打开软件后点击闪电图标连接
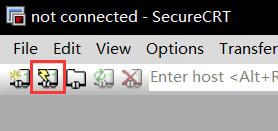
设置
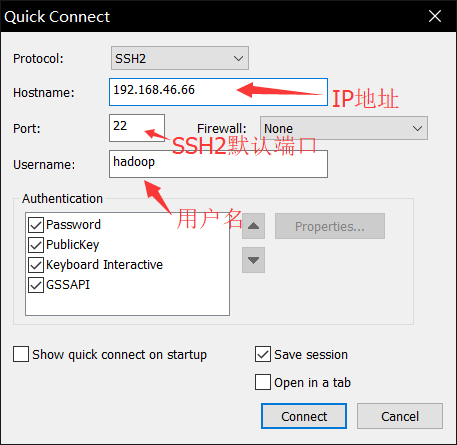
输入密码并保存密码
进入成功后,在界面ALT+P 可进入SFTP界面(SSH)
使用 put 路径(例如:put C:jdk-7u_65-i585.tar.gz)
可将本机软件拷贝至远程主机(linux虚拟机)

传输完毕后删除不需要的文件夹
rm -rf 文件夹名
新建文件夹application
mkdir application
然后把jdk解压至application文件夹
tar -zxvf jdk-7u_65-i585.tar.gz -C application/
接下来配置环境变量(CentOS下 vi与vim没区别) shift+g 到达文章最下一行,gg第一行 shift+$到达行尾
sudo vi /etc/profile
在文件最后添加 SecureCRTPortable左键选中是复制,右键一下就是粘贴
export JAVA_HOME=/home/hadoop/app/jdk-7u_65-i585
export PATH=$PATH:$JAVA_HOME/bin
刷新配置文件
source /etc/profile
检测是否成功
java -version

jdk环境变量搞定
下面进行Hadoop配置
文件传输、解压方法和jdk一样
解压到application后删除 doc 帮助文档(不删也没事,只是节省点存储空间)
接下来修改配置文件,Hadoop的配置文件在/etc/hadoop目录下,需要修改的文件如下所示
|
第一个:hadoop-env.sh vim hadoop-env.sh #这里要写死,原本是自动读取系统变量,但有时候读不到 #echo $JAVA_HOME 可以输出变量值 export JAVA_HOME=/home/hadoop/app/jdk1.7.0_65 |
| 第二个:core-site.xml
<!-- 指定HADOOP所使用的文件系统schema(URI),HDFS的老大(NameNode)的地址 --> 以上配置都在<configuration></configuration>中加入 |
| 第三个:hdfs-site.xml
<!-- 指定HDFS副本的数量 ,因为博主是用虚拟机,所以随便几个副本都是在一台机器上,配多个没啥意义,真实环境应该为3个或以上--> |
| 第四个:mapred-site.xml
mv mapred-site.xml.template mapred-site.xml vim mapred-site.xml |
| 第五个:yarn-site.xml
<!-- 指定YARN的老大(ResourceManager)的地址 --> |
注意:要配置DataNode的节点地址在slaves.xml里面添加
然后先关闭防火墙
sudo service iptables status 查看防火墙状态
sudo service iptables stop 关闭防火墙
因为只是当前关闭防火墙,防火墙是自启的,所以要永久关闭服务
sudo chkconfig iptables --list 看到各级别防火墙自启状态
sudo chkconfig iptables off 关闭自启防火墙
可以一个个端口号往防火墙白名单里添加,但Hadoop一般是在内网跑,干脆直接关闭,懒得麻烦了
现在配置下环境变量
sudo vi /etc/proflie
最下面加2行
export HADOOP_HOME=/home/hadoop/app/hadoop-2.4.1
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
配置完成后格式化Hadoop
记得刷新 source /etc/profile
hadoop namenode -format

搞定
现在准备启动Hadoop,进入Hadoop的sbin文件夹,可以看见很多的启动指(.sh结尾的)
启动
start-dfs.sh
start-yarn.sh
jps查看进程

成功,测试一波
先去Windows的C:WindowsSystem32driversetc 下的hosts加入你的地址(例如: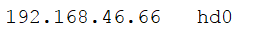 )
)
然后去浏览器输入http://你配置的名称:50070 就可以看见进入的原谅色的页面了,里面可以看到很多信息,这里不详细说明了
另外在右上角

Browse the file system下可以看见你HDFS里面有的文件,/是根目录,点击文件可以下载
我们上传一个文件上去看看,
在linux界面下
hadoop fs -put jdk-7u65-linux-i586.tar.gz hdfs://hd0:9000/
传个jdk到HDFS的根目录,然后再在刚才的页面进行查询

成功,现在把linux根目录下的jdk删掉,试试从HDFS下载
hadoop fs -get hdfs://hd0:9000/jdk-7u65-linux-i586.tar.gz
好了,测试结束
免密配置下一节写出来
暂时告一段落,下一节过几天发