https://zhuanlan.zhihu.com/p/144059763
Yolo V3
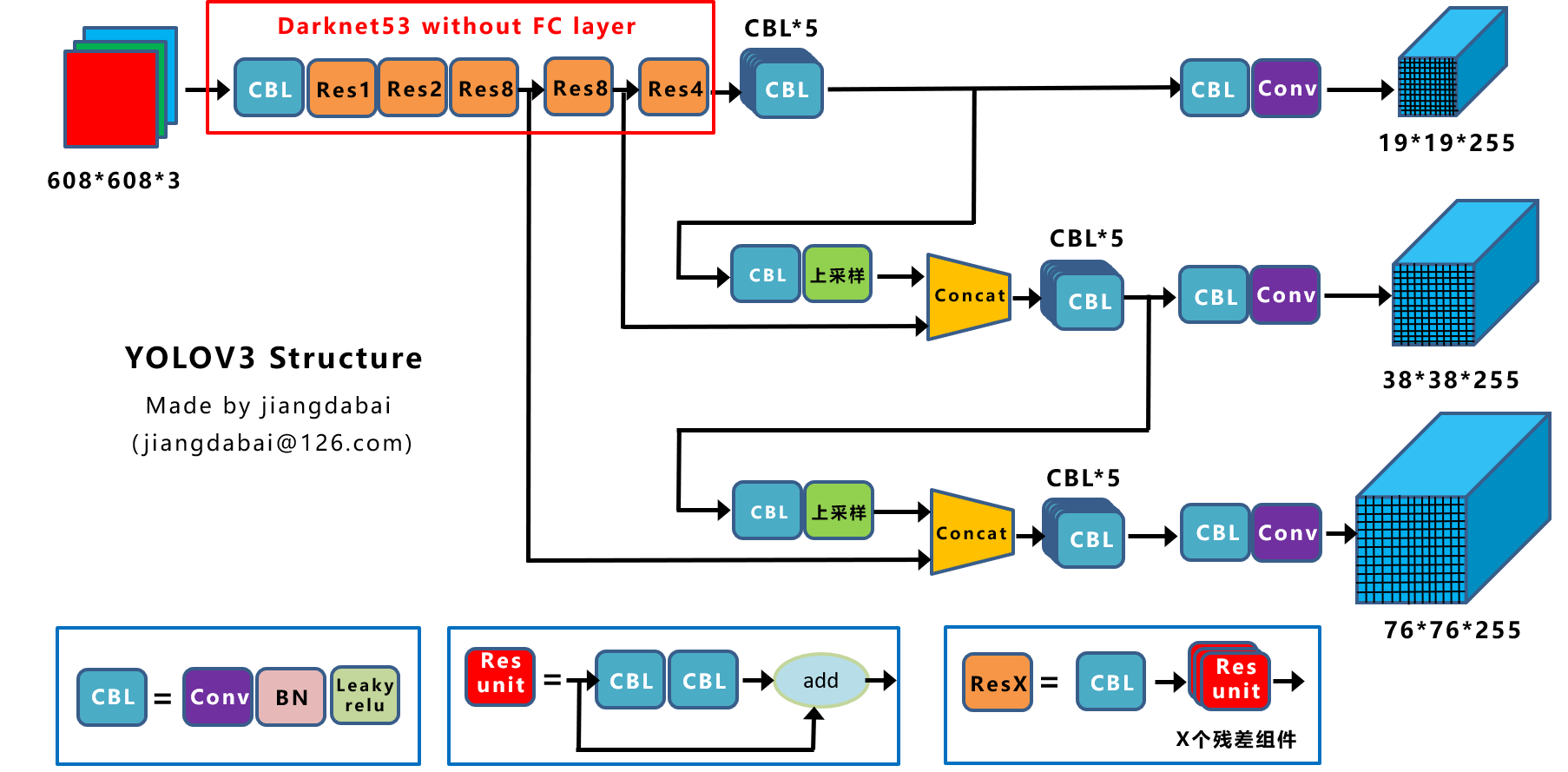
上图三个蓝色方框内表示Yolov3的三个基本组件:
- CBL:Yolov3网络结构中的最小组件,由Conv+Bn+Leaky_relu激活函数三者组成。
- Res unit:借鉴Resnet网络中的残差结构,让网络可以构建的更深。
- ResX:由一个CBL和X个残差组件构成,是Yolov3中的大组件。每个Res模块前面的CBL都起到下采样的作用,因此经过5次Res模块后,得到的特征图是608->304->152->76->38->19大小。
Backbone
卷积层的数量:
每个ResX中包含1+2*X个卷积层,因此整个主干网络Backbone中一共包含1+(1+2*1)+(1+2*2)+(1+2*8)+(1+2*8)+(1+2*4)=52,再加上一个FC全连接层,即可以组成一个Darknet53分类网络。不过在目标检测Yolov3中,去掉FC层,不过为了方便称呼,仍然把Yolov3的主干网络叫做Darknet53结构。
yolo v3输出了3个不同尺度的feature map,这也是v3论文中提到的为数不多的改进点:predictions across scales,这个借鉴了FPN(feature pyramid networks),采用多尺度来对不同size的目标进行检测,越精细的grid cell就可以检测出越精细的物体,y1,y2和y3的深度都是255,边长的规律是13:26:52
Anchor相关
yolo v3设定的是每个网格单元预测3个box,所以每个box需要有(x, y, w, h, confidence)五个基本参数,然后还要有80个类别的概率。所以3*(5 + 80) = 255。
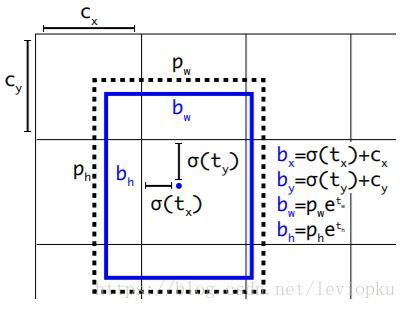
对于v3而言,在prior这里的处理有明确解释:选用的b-box priors 的k=9(3*3),对于tiny-yolo的话,k=6(2*3)。priors都是在数据集上聚类得来的,有确定的数值,如下:
10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
每个anchor prior(名字叫anchor prior,但并不是用anchor机制)就是两个数字组成的,一个代表高度另一个代表宽度。
对于训练图片中的ground truth,若其中心点落在某个cell内,那么该cell内的3个anchor box负责预测它,具体是哪个anchor box预测它,需要在训练中确定,即由那个与ground truth的IOU最大的anchor box预测它,而剩余的2个anchor box不与该ground truth匹配。YOLOv3需要假定每个cell至多含有一个grounth truth,而在实际上基本不会出现多于1个的情况。可见每个ground truth只分配一个anchor prior,以减小计算量。同时作者使用了logistic回归来对每个anchor包围的内容进行了一个目标性评分(objectness score),根据目标性评分来选择anchor prior进行predict(不是所有anchor prior都会有输出),但如果模板框不是最佳的,即使它超过我们设定的阈值,我们还是不会对它进行predict。
Yolo V4
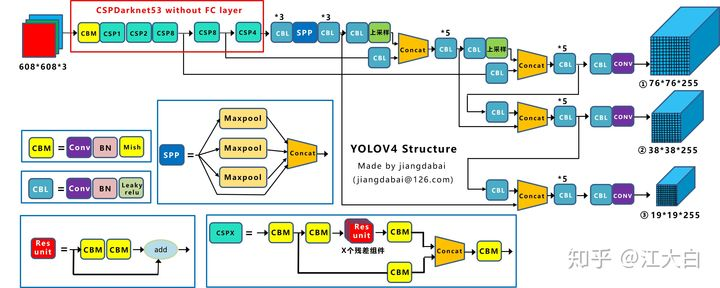
多了CSP结构,PAN结构
先整理下Yolov4的五个基本组件:
- CBM:Yolov4网络结构中的最小组件,由Conv+Bn+Mish激活函数三者组成。
- CBL:由Conv+Bn+Leaky_relu激活函数三者组成。
- Res unit:借鉴Resnet网络中的残差结构,让网络可以构建的更深。
- CSPX:借鉴CSPNet网络结构,由卷积层和X个Res unint模块Concate组成。
- SPP:采用1×1,5×5,9×9,13×13的最大池化的方式,进行多尺度融合。
Backbone卷积层的数量:
每个CSPX中包含5+2*X个卷积层,因此整个主干网络Backbone中一共包含1+(5+2*1)+(5+2*2)+(5+2*8)+(5+2*8)+(5+2*4)=72。
创新点
Mosaic数据增强:参考2019年的Cutouthttps://arxiv.org/abs/1905.04899v2
CSPDarknet:参考2019年的CSPNethttps://arxiv.org/pdf/1911.11929.pdf
Mish激活函数:参考2019年的https://arxiv.org/abs/1908.08681
Dropblock:参考2018年的https://arxiv.org/pdf/1810.12890.pdf
SPP:参考2019年的《DC-SPP-Yolo》https://arxiv.org/ftp/arxiv/papers/1903/1903.08589.pdf
PAN:参考2018年的PANethttps://arxiv.org/abs/1803.01534
CIOU_loss:参考2020年的https://arxiv.org/pdf/1911.0828
算法创新分为三种方式:
- 第一种:面目一新的创新,比如Yolov1、Faster-RCNN、Centernet等,开创出新的算法领域,不过这种也是最难的
- 第二种:守正出奇的创新,比如将图像金字塔改进为特征金字塔
- 第三种:各种先进算法集成的创新,比如不同领域发表的最新论文的tricks,集成到自己的算法中,却发现有出乎意料的改进
Yolov4既有第二种也有第三种创新,组合尝试了大量深度学习领域最新论文的20多项研究成果,
Yolov4的整体结构拆分成四大板块:

大白主要从以上4个部分对YoloV4的创新之处进行讲解,让大家一目了然。
- 输入端:这里指的创新主要是训练时对输入端的改进,主要包括Mosaic数据增强、cmBN、SAT自对抗训练
- BackBone主干网络:将各种新的方式结合起来,包括:CSPDarknet53、Mish激活函数、Dropblock
- Neck:目标检测网络在BackBone和最后的输出层之间往往会插入一些层,比如Yolov4中的SPP模块、FPN+PAN结构
- Prediction:输出层的锚框机制和Yolov3相同,主要改进的是训练时的损失函数CIOU_Loss,以及预测框筛选的nms变为DIOU_nms
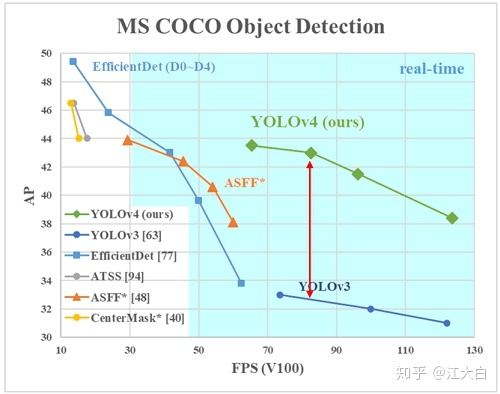
总体来说,Yolov4对Yolov3的各个部分都进行了改进优化,下面丢上作者的算法对比图。
1)Mosaic数据增强
Yolov4中使用的Mosaic是参考2019年底提出的CutMix数据增强的方式,但CutMix只使用了两张图片进行拼接,而Mosaic数据增强则采用了4张图片,随机缩放、随机裁剪、随机排布的方式进行拼接。

这里首先要了解为什么要进行Mosaic数据增强呢?
在平时项目训练时,小目标的AP一般比中目标和大目标低很多。而Coco数据集中也包含大量的小目标,但比较麻烦的是小目标的分布并不均匀。
首先看下小、中、大目标的定义: 2019年发布的论文《Augmentation for small object detection》对此进行了区分:
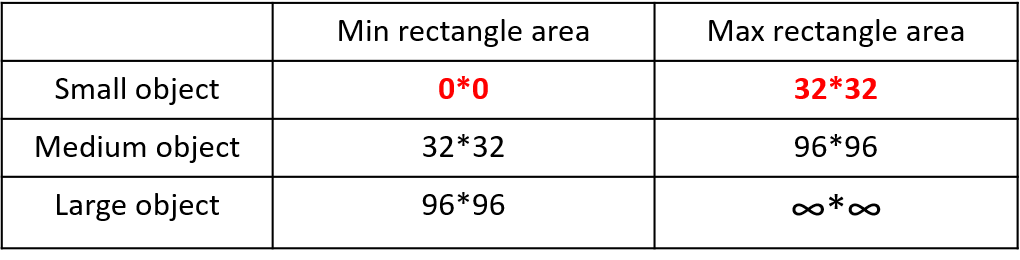
可以看到小目标的定义是目标框的长宽0×0~32×32之间的物体。
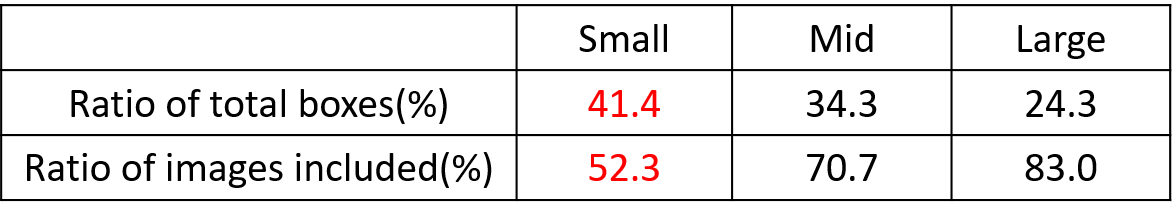
但在整体的数据集中,小、中、大目标的占比并不均衡。 如上表所示,Coco数据集中小目标占比达到41.4%,数量比中目标和大目标都要多。
但在所有的训练集图片中,只有52.3%的图片有小目标,而中目标和大目标的分布相对来说更加均匀一些。
针对这种状况,Yolov4的作者采用了Mosaic数据增强的方式。
主要有几个优点:
- 丰富数据集:随机使用4张图片,随机缩放,再随机分布进行拼接,大大丰富了检测数据集,特别是随机缩放增加了很多小目标,让网络的鲁棒性更好。
- 减少GPU:可能会有人说,随机缩放,普通的数据增强也可以做,但作者考虑到很多人可能只有一个GPU,因此Mosaic增强训练时,可以直接计算4张图片的数据,使得Mini-batch大小并不需要很大,一个GPU就可以达到比较好的效果。
此外,发现另一研究者的训练方式也值得借鉴,采用的数据增强和Mosaic比较类似,也是使用4张图片(不是随机分布),但训练计算loss时,采用“缺啥补啥”的思路:
如果上一个iteration中,小物体产生的loss不足(比如小于某一个阈值),则下一个iteration就用拼接图;否则就用正常图片训练,也很有意思。