原地址http://timyang.net/data/key-list-pagination/
今天讨论了一个传统的问题,问题本身比较简单,就是针对key-list类型的数据,如何优化方案做到性能与成本的tradeoff。Key-list在用户类型的产品中非常普遍,如一个用户的好友关系 {“uid”:{1,2,3,4,5}},一条微博下面的评论id列表,一个用户发表的微博id列表等。
根据经验,在大部分场景下,单个业务的list数据长度99%在1000条以下,但剩下的1%的数据可能多达100万条,因此在实现方案的时候不能忽视这些超大数据集的问题,这也体现了常说的80%+的时间在优化20%-的功能。
List数据访问模型常见的有两种方式
1. 扶梯方式
扶梯方式在导航上通常只提供上一页/下一页这两种模式,部分产品甚至不提供上一页功能,只提供一种“更多/more”的方式,也有下拉自动加载更多的方式,在技术上都可以归纳成扶梯方式。
扶梯方式在技术实现上比较简单及高效,根据当前页最后一条的偏移往后获取一页即可。写成SQL可能类似
SELECT * FROM LIST_TABLE WHERE id > offset_id LIMIT n;
2. 电梯方式
另外一种数据获取方式在产品上体现成精确的翻页方式,如1,2,3……n,同时在导航上也可以由用户输入直达n页。国内大部分场景采用电梯方式,但电梯方式在技术实现上相对成本较高。
在MySQL中,通常提到的b-tree,在存储引擎实现上,通常都是b+tree,如图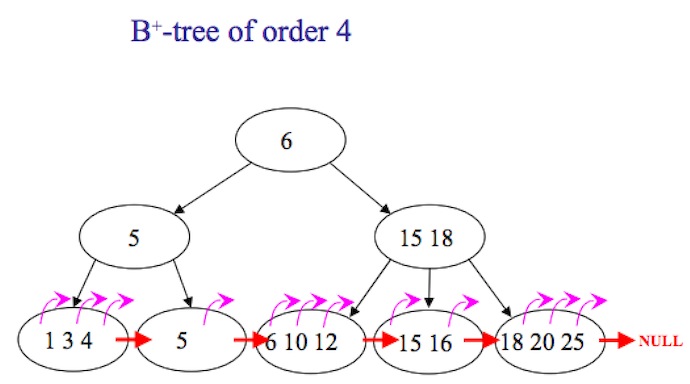
从图中可以看到,使用电梯方式时候,当用户指定翻到第n页时候,并没有直接方法寻址到该位置,而是需要从第一楼逐个count,scan到count*page时候,获取数据才真正开始,所以导致效率不高。而在数据存在新增及删除的情况下,偏移量也不能有效的缓存,一个10万条的list,只要有一条变化,原先的楼层可能会全部发生变化。
以上描述的场景属于单机版本,在数据规模较大时候,互联网系统通常使用分库的方式来保存,实现方法更为复杂。
在面向用户的产品中,数据分片通常会将同一用户的数据存在相同的分区,以便更有效率的获取当前用户的数据。如下图所示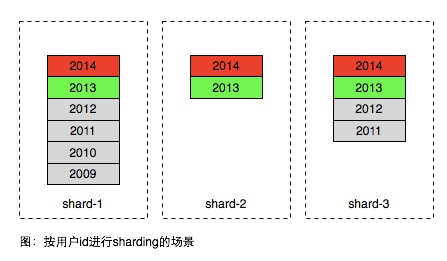
但上述方案在常见的场景中存在很大不足,大部分产品用户只访问最近产生的数据,历史的数据只有极小的概率被访问到,因此同一个区域内部的数据访问是非常不均匀,如图中2014年生成的属于热数据,2012年以前的属于冷数据,只有极低的概率被访问到。因此简单的解决方案是按时间远近将数据进行进一步分区,如图。
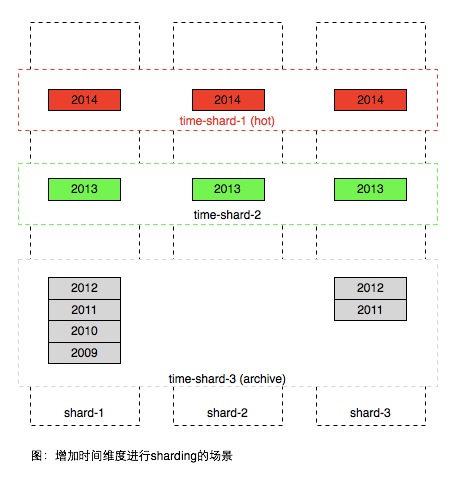
注意在上图中使用时间方式sharding之后,在一个时间分区内,也需要用前一种方案将数据进行sharding,因为一个时间片区通常也无法用一台服务器容纳。
上面的方案较好的解决了具体场景对于key list访问性能及成本的tradeoff,但是它存在以下不足
- 数据按时间进行滚动无法全自动,需要较多人为介入或干预
- 数据时间维度需要根据访问数据及模型进行精巧的设计,无法简单重用
- 为了实现电梯直达功能,需要增加额外的二级索引,比如2013年某用户总共有多少条记录
由于以上问题,尤其是二级索引的引入,显然它不是理想中的key list实现,后文继续介绍适合长尾翻页key list设计的一些思路及尝试。