本文仅供学习与交流,切勿用于非法用途!!!
该项目的实现,主要基于视频 https://www.bilibili.com/video/BV1qt411H7ox?t=633 的基础上来实现的(当然也有找其他的视频等资料),这里对阳光问政发起数据请求,让其将本机ip禁掉:
这是可以正常打开阳光问政的网页:

这是对阳光问政发起数据请求,让其将本机ip禁掉:

使用免费的代码ip的对阳光问政发起数据请求:
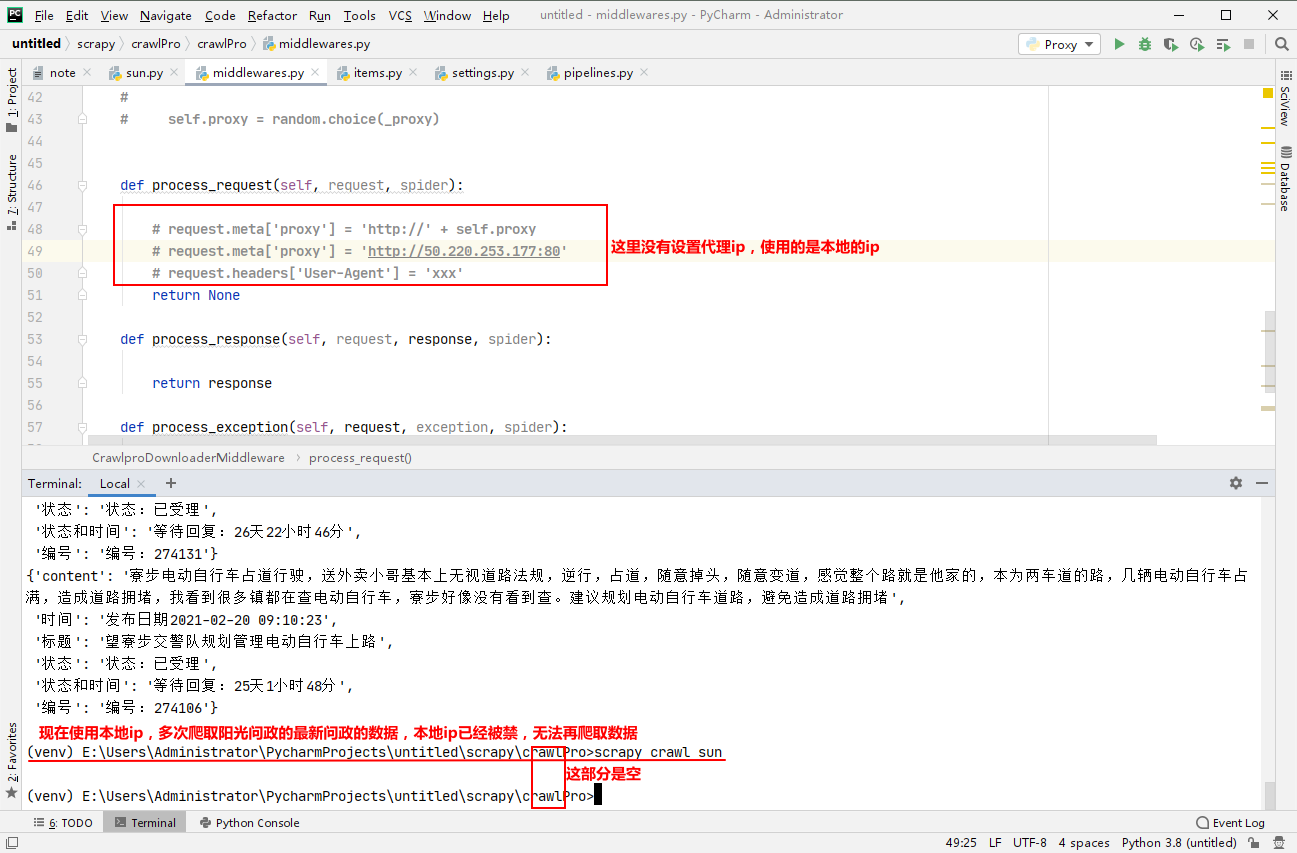
打开scrapy项目里面的中间件middlewares.py,只保留下面的类里面的3个函数其他的删除掉
class '自己工程项目的名字'DownloaderMiddleware:
def process_request(self, request, spider):
return None
def process_response(self, request, response, spider):
return response
def process_exception(self, request, exception, spider):
return request
实现在scrapy框架中使用免费的代理ip,解决ip被封禁的问题代码:
这里使用requests请求解析免费代理ip网站的ip来使用,
import random
import requests
from lxml import etree
class '自己工程项目的名字'DownloaderMiddleware:
headers = {
"Connection": 'close',
"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36 Edg/87.0.664.52',
} #ua伪装
def __init__(self):#初始化函数
self.url = '免费代理ip的网站url'
self.proxy = '' #把proxy 定义为空,来保存免费的代理ip
self._get_proxy()
def _get_proxy(self): #获取免费的代理ip
response = requests.get(self.url,headers=self.headers)
response.encoding = 'utf-8'
page_text = response.text
tbody = etree.HTML(page_text) #这里是基于我的免费代理ip网站做的代理ip数据解析,这个要按照自己的免费代理ip网站来,这里仅供参考
tbody_tr = tbody.xpath('//div[@class="item"]//p/text()')
_proxy = []#存放免费代理ip
for proxy in tbody_tr:
ip_port = proxy.split("@")[0].replace(' ', '') #对免费代理ip的网站进行数据解析处理,提取出代理ip
_proxy.append(ip_port)#把解析抓取到的免费代理ip都放在_proxy列表里面
self.proxy = random.choice(_proxy) #使用random.choice(_proxy)把_proxy列表里面的免费代理随机抽取赋给self.proxy
def process_request(self, request, spider):
#request.meta['proxy'] = 'http://ip:prot' 这个是设置代理ip的形式
request.meta['proxy'] = 'http://' + self.proxy #因为_proxy列表里面的免费代理只有ip和prot没有'http://',所以要在这里要加上
return None
def process_response(self, request, response, spider):
return response
def process_exception(self, request, exception, spider):
return request
写好上面这部分的代码后,在配置文件settings.py里面开启中间件:
DOWNLOADER_MIDDLEWARES = {
''自己工程项目的名字'.middlewares.'自己工程项目的名字'DownloaderMiddleware': 543,
}

本文可以借鉴学习,切勿照搬,根据自己分析的实际情况实现项目!!!