1.Java中常见的数据结构
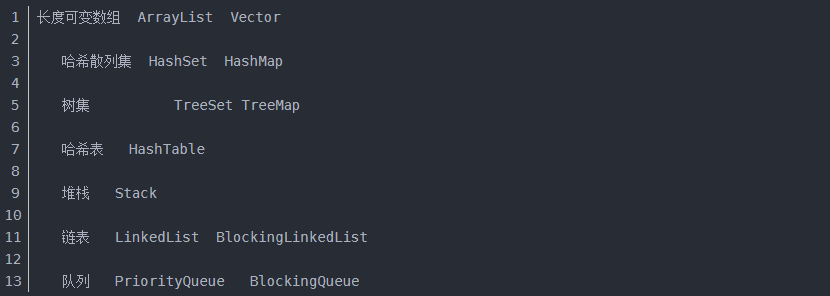
长度可变数组 ArrayList Vector
哈希散列集 HashSet HashMap
树集 TreeSet TreeMap
哈希表 HashTable
堆栈 Stack
链表 LinkedList BlockingLinkedList
队列 PriorityQueue BlockingQueue
2. 数组的排序
特点:
1.所有元素的存放地址是连续的
2.长度是固定不变的
3.可以通过下标操作每一个元素
使用场景:查询操作比较频繁的时候一般使用数组
数组的排序:
冒泡 选择 插入 希尔 堆排序 桶排序 二分排序 快排 归并...
1.冒泡:相邻的两个元素依次比较,小的往前冒[往下标小的方向]
比较一次就交换一次
2.选择:先默认一个下标的值最小,然后依次和该元素比较,记录比较小的元素的下标位置
每一轮都找出一个当前的最小值的下标位置,再进行交换
3.插入:将数组分成左右两部分,左边是一个有序的,右边是等待排序的
第一次左边只有一个元素
依次将右边的元素插入到左边的合适的位置
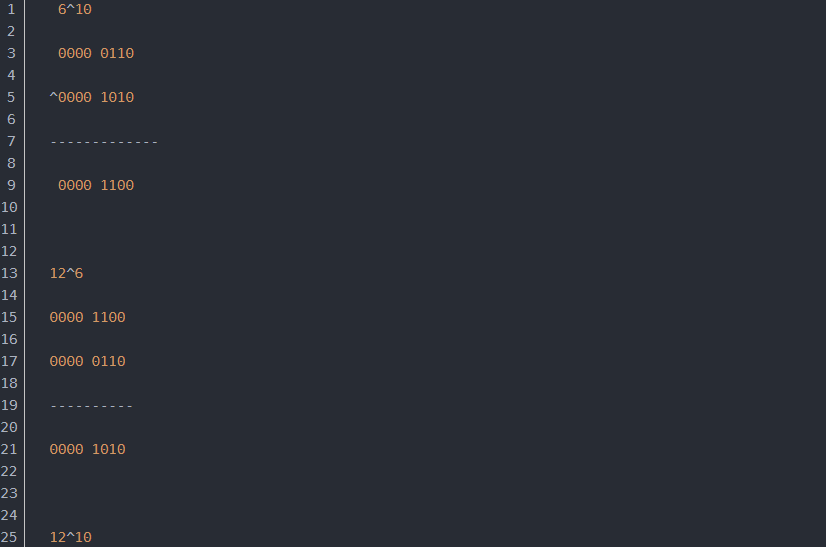
4.^ 异或 按照二进制位进行运算
相同位值相同则为0 ,不相同则为1
5.Java中的数组类 Arrays:
sort(int[]) 快速排序
parallelSort(int[]) 归并排序
binarySearch(int[],int) 使用二分搜索来检索数据,前提要是一个经过了排序的数组
copyOf() 复制数组
//参数1:原数组
//参数2: 要拷贝的起始下标
//参数3:目标数组
//参数4:目标数组中开始存放数据的起始下标
//参数5:拷贝的个数
System.arraycopy(a, 1, b, 1, a.length-1);
3.集合框架中的Collections
sort(List<>) 归并排序
Collection 表示一组对象
List 有序的 可重复的
ArrayList 长度可变数组 异步操作
Vector 长度可变数组 同步操作
Stack 堆栈 [LIFO]
LinkedList 链表
Set 不包含重复元素
HashSet 基于Hash表的实现[实际上是HashMap] 无序
TreeSet 基于红黑树的实现[实际上时TreeMap] 元素按照自然顺序或者指定的比较器排序
Queue 通常但并非一定按照先进先出的方式排列元素
PriorityQueue 优先级队列 元素按照自然顺序或者指定的比较器排序
LinkedBlockingQueue 先进先出[FIFO]的队列
LinkedList是一个特殊的类,它既可以作为一个链表,还可以作为堆栈,队列和双端队列使用
Map 键值对:
HashMap 基于哈希表的实现
TreeMap 基于红黑树[自平衡二叉排序树]的实现
HashTable 哈希表的实现
数据结构可以看做是一个存储数据的容器,不同的数据结构区别在于数据的存储方式以及数据之间的关系不一样
每一种数据结构都要提供增删改查的基本操作
4.自定义栈
public class MyStack<E>{
//将数据压入栈中
public void push(E e){}
//弹出栈顶的数据
public E pop(){}
//查看栈顶的数据
public E look(){}
//判断栈是否为空
public boolean isEmpty(){}
}
自定义长度可变数组[ArrayList]
栈:LIFO 后进先出
最先放进的数据在栈底,最后放的数据在栈顶
5.自定义队列的实现
队列:FIFO 先进先出 队列头 队列尾
public class MyQueue<E>{
//将数据加入到队列的尾部
public void add(E e){}
//移除队列头部的数据
public E pop(){}
//查看队列头部的数据
public E look(){}
public boolean isEmpty(){}
}
6.链式结构
链式结构是由很多个结点对象组成,结点对象中存放了数据和对下一个结点对象的引用
头结点:没有其它结点引用该结点
尾结点:没有引用其它结点
7.哈希结构
1.hashCode方法和equals方法的重写
2.HashMap是如何存储数据的?
HashMap本质上是一个存放链表的数组[1.7及以下]
HashMap本质上是一个存放树形结构的数组[1.8及以上]
HashMap的特点:Key不可以重复,每个key对应一个值,值可以重复的, 遍历的时候不保证键值对的顺序
3.HashSet:其本质上就是一个HashMap
4.Hashtable
8.TreeSet:基于TreeMap的实现
TreeMap:基于红黑树[自平衡二叉查找树]
按照中序遍历的方式是有个有序的
key不能重复
key按照自然顺序升序排序,
如果key是一个对象,按照指定的比较器来排序
对象默认是不能比较大小的,如果要比较对象的大小,该类就必须要实现Comparable接口
1.练习HashSet,HashMap的用法
2.HashSet与HashMap的实现原理
3.TreeSet,TreeMap的用法,比较器的用法
4.TreeSet,TreeMap的实现原理
5.equals方法与hashcode方法的重写