python3下urllib.request库高级应用之Handle处理器和自定义Opener
经过前面对urllib.request库的频繁使用,都知道我们使用urllib库请求是都是使用urlopen()方法实现的。实际上它的底层是使用HTTPHandler个Opener来实现的。查看urllib.request库里的urlopen()方法的源码。
def urlopen(url, data=None, timeout=socket._GLOBAL_DEFAULT_TIMEOUT,
*, cafile=None, capath=None, cadefault=False, context=None):
global _opener
if cafile or capath or cadefault:
if context is not None:
raise ValueError(
"You can't pass both context and any of cafile, capath, and "
"cadefault"
)
if not _have_ssl:
raise ValueError('SSL support not available')
context = ssl.create_default_context(ssl.Purpose.SERVER_AUTH,
cafile=cafile,
capath=capath)
https_handler = HTTPSHandler(context=context)
opener = build_opener(https_handler)
elif context:
https_handler = HTTPSHandler(context=context)
opener = build_opener(https_handler)
elif _opener is None:
_opener = opener = build_opener()
else:
opener = _opener
return opener.open(url, data, timeout)
def install_opener(opener):
global _opener
_opener = opener_url_tempfiles = []
opener是 urllib.request.OpenerDirector 的实例,我们之前一直都在使用的urlopen,它是一个特殊的opener(也就是模块帮我们构建好的)。
我们采用urlopen()的方式去请求,其实是有些局限性的,比如我们需要打开debug模式,或通过代理模式去请求,就不行了。如果要实现debug模式或代理请求的话,我们需要自己定义Handler和opener。
可以使用相关的 Handler处理器 来创建特定功能的处理器对象;
然后通过 urllib.request.build_opener()方法使用这些处理器对象,创建自定义opener对象;
使用自定义的opener对象,调用open()方法发送请求。
如果程序里所有的请求都使用自定义的opener,可以使用urllib.request.install_opener() 将自定义的 opener 对象 定义为 全局opener,表示如果之后凡是调用urlopen,都将使用这个opener(根据自己的需求来选择)
在urllib库中,给我们提供了一些Handler,如:HTTPHandler,HTTPSHandler,ProxyHandler,BaseHandler,AbstractHTTPHandler,FileHandler,FTPHandler,分别用于处理HTTP,HTTPS,Proxy代理等。
例子一: 简单的自定义opener()
import urllib.request
# 第一步:构建一个HTTPHandler 处理器对象,支持处理HTTP请求
http_handler = urllib.request.HTTPHandler()
# 第二步:调用urllib2.build_opener()方法,创建支持处理HTTP请求的opener对象
opener = urllib.request.build_opener(http_handler)
# 第三步:构建 Request请求
request = urllib.request.Request("http://www.baidu.com/")
# 第四步:调用自定义opener对象的open()方法,发送request请求
response = opener.open(request)
# 第五步:获取服务器响应内容
print(response.read())
程序运行的结果:
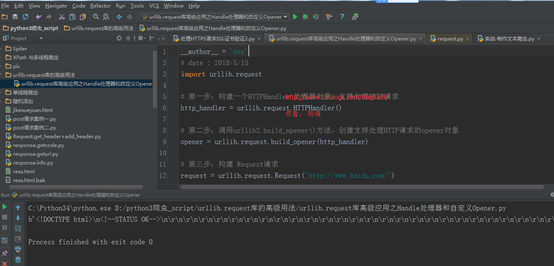
这种方式发送请求得到的结果,和使用urllib.request.urlopen()发送HTTP/HTTPS请求得到的结果是一样的。
HTTPHandler的debug模式
HTTPHandler的debug模式,是通过在HTTPHandler的参数中传入debuglevel=1,1表示打开debug模式。0表示关闭,默认是0。:
例子二:HTTPHandler的debug模式
import urllib.request
# 第一步:构建一个HTTPHandler 处理器对象,支持处理HTTP请求,同时开启Debug Log
http_handler = urllib.request.HTTPHandler(debuglevel=1)
# 第二步:调用urllib2.build_opener()方法,创建支持处理HTTP请求的opener对象
opener = urllib.request.build_opener(http_handler)
# 第三步:构建 Request请求
request = urllib.request.Request("http://www.baidu.com/")
# 第四步:调用自定义opener对象的open()方法,发送request请求
response = opener.open(request)
# 第五步:获取服务器响应内容
print(response.read().decode('utf-8'))
运行结果:
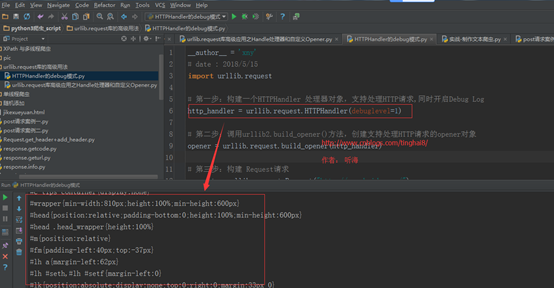
如果在 HTTPHandler()增加 debuglevel=1参数,就会将 Debug Log 打开,这样程序在执行的时候,会把收包和发包的报头在屏幕上自动打印出来,方便调试,有时可以省去抓包的工作。
---------------------
个人今日头条账号: 听海8 (上面上传了很多相关学习的视频以及我书里的文章,大家想看视频,可以关注我的今日头条)
