1.开启慢查询
在mysql的配置文件my.ini最后增加如下命令
[mysqld]
port=3306
slow_query_log =1
long_query_time = 1
2.查看慢查询记录
默认是放在mysql的data目录,并且文件名为host_name-slow.log即 主机名-slow.log
3.mysql查询缓存
在每次mysql重启后,保存的缓存都会丢失,关于缓存的设置也会丢失,所以每次使用缓存前要设置:
set session query_cache_type = ON; --开启查询缓存
set global query_cache_size = 600000; --设置缓存内存大小
set global query_cache_limit = 100000; 设置当搜索结果大于1M时不保存
查询缓存相关设置
mysql> show variables like '%query_cache%';
查看缓存的状态
mysql> show status like '%Qcache%';
--Qcache_hits表示sql查询在缓存中命中的累计次数,是累加值。
mysql> SHOW STATUS LIKE 'Qcache_hits';
4.索引类型
4.1 主键索引(primary)
在创建表的时候,把主键设置为递增,那么这个就是主键索引
添加:后期添加主键索引 : alter table 表名 add primary key (字段名)
创建表的时候指定主键
4.2 唯一索引(unique)
唯一索引可以作用在任何字段上,unique,字段内容可以为空null,如果有内容,那么就不能重复
创建: create unique index 索引名 on 表名 (字段名)
4.3 普通索引(normal)
一般来说,普通索引的创建是先创建表,然后再创建普通索引
create index 索引名 on 表名 (字段名)
4.4 全文索引(fulltext)
主要是针对文件,文本的检索;全文索引只针对Myisam引擎,InnoDB不支持
sql语句中不能使用 %like% ,这种用法不会用到全文索引,可以使用explain来分析查看sql语句中是否使用到了全文索引
例子:explain select * from articles where boby like '%kang%';
其中的possible_keys 为null,表示没用用到
正确的用法是
select * from articles where match(title,body) againist(kang);
在title,boby字段中搜索kang这个词,可以使用到全文索引
注:1.mysql中fulltext全文索引只支持英文,针对中文索引使用sphinx
2.只在myisam引擎下生效
3.使用方法match(字段名....) against(关键词)
4.5 针对索引的其他问题
搜索:show index from 表名
索引的代价:
1.磁盘的占用
2.对update,delete,insert操作变慢
索引的使用环境
1.较频繁的作为查询条件字段
2.唯一性太差的字段不适用使用索引,类似 sex='男'、sex='女'这种字段
3.更新比较频繁的字段不适用使用,类似登陆次数
4,sql中有 like 查询以%开头不会使用索引
5.sql中条件里有or,除非用到的条件都添加了索引,否则不会使用索引
6.如果列类型是字符串,那么一定要在条件中将数据用引号括起来
4.6 联合索引
作用非常大,当where 中有多个条件时,并且order by 字段,把这几个字段添加到联合索引中,可以快速提高
优化order by使用联合索引是一个很大的优化,具体参考http://www.jb51.net/article/38953.htm
4.7 索引sql语句
/*创建索引*/
CREATE index nameIndex on demo(name)
/*删除索引*/
ALTER TABLE demo DROP INDEX nameIndex
/*删除主键索引,先去除自动增加,再删除索引*/
alter table demo modify id int unsigned not null;
alter table demo drop primary key;
/*修改为自动增加*/
alter table demo modify id int unsigned not null auto_increment
5.sql优化技巧
1. group by 分组查询,默认情况下,还会对其他字段的值进行排序,可以取消,后面加上 order by null
select * from user group by name order by null;
2. 在有些情况下,使用join来代替子查询
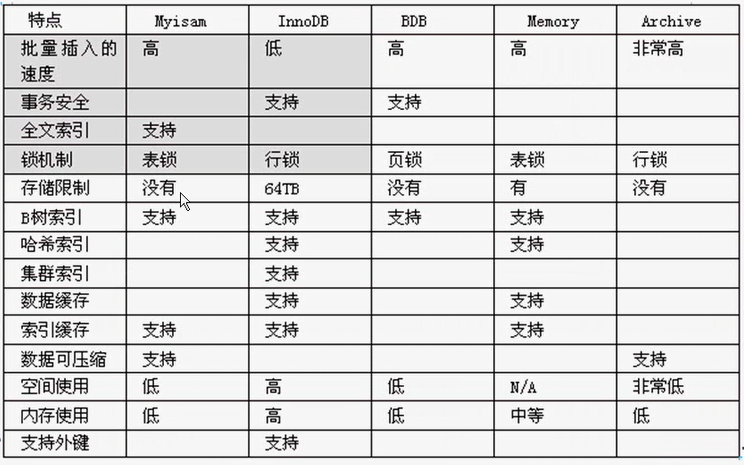
3.选择合适的存储引擎(myisam,InnoDB)
myisam : 如果表对事务要求不高,而且是以查询和添加为主的 , 多用myisam;比如一些bbs的发帖,回复表
InnoDB : 对事务要求高,保存的数据都是重要数据,建议使用InnoDB,比如订单表,账户表等等
Memory : 数据变化频繁,不需要入库,同时又频繁的查询和修改,建议用Memory(和redis理念差不多)
4.碎片整理: 在使用myisam的存储引擎后,删除数据后,存储数据的文件并没有减少,这说明说句并没有被真 实的删除,所以如果使用myisam引擎后,要定时对myisam进行整理清理垃圾数据;
optimize table 表名;
6.数据库备份
6.1 手动备份数据库
cmd控制台:mysqldump -u root -p 密码 数据库名 > 文件路径
mysqldump -u -proot demo > d:/demo.sql //备份整个demo数据库
mysqldump -u -proot demo table1 table2 table3 > d:/demo.sql //备份demo数据库下的表table1,table2,table3
恢复 :
mysql 控制台:source d:demo.sql
7.分表
假设要分3个表,把数据分布写到3个表中,user_0,user_1,user_2,现在又1,2,3,4,5,6,7,8,9个用户
则 user_1表中是:1 4 7
user_2表中是:2 5 8
user_3表中是:3 6 9
写入的时候,可以建一个附加表uid来记录最后的一个uid,下次插入数据的时候取uid表中的值,判断接下来要插入到哪一个表中