1)等待数据准备 (Waiting for the data to be ready)
2)将数据从内核拷贝到进程中(Copying the data from the kernel to the process)
记住这两点很重要,因为这些IO模型的区别就是在两个阶段上各有不同的情况。
我们这里研究的IO模型都是针对网络IO的
Stevens在文章中一共比较了五种IO Model:
* blocking IO 阻塞IO
* nonblocking IO 非阻塞IO
* IO multiplexing IO多路复用
* signal driven IO 信号驱动IO
* asynchronous IO 异步IO
由于signal driven IO(信号驱动IO)在实际中并不常用,所以主要介绍其余四种IO Model。
阻塞IO(blocking IO)
在linux中,默认情况下所有的socket都是blocking,一个典型的读操作流程大概是这样:
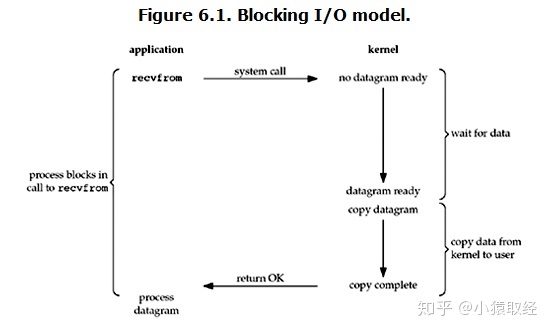
常见的网络阻塞状态:
accept
recv
recvfrom
send虽然它也有io行为 但是不在我们的考虑范围
案例:
服务端:
import socket
server = socket.socket()
server.bind(('127.0.0.1',8080))
server.listen(5)
while True:
conn, addr = server.accept()
while True:
try:
data = conn.recv(1024)
if len(data) == 0:break
print(data)
conn.send(data.upper())
except ConnectionResetError as e:
break
conn.close()
在服务端开设多进程或者多线程 进程池线程池 其实还是没有解决IO问题
该等的地方还是得等 没有规避,只不过多个人等待的彼此互不干扰
客户端:
import socket
client = socket.socket()
client.connect(('127.0.0.1', 8080))
while True:
client.send(b'hello world')
data = client.recv(1024)
print(data)
总之,多线程模型可以方便高效的解决小规模的服务请求,但面对大规模的服务请求,多线程模型也会遇到瓶颈,可以用非阻塞接口来尝试解决这个问题。
非阻塞IO(non-blocking IO)
Linux下,可以通过设置socket使其变为non-blocking。当对一个non-blocking socket执行读操作时,流程是这个样子:
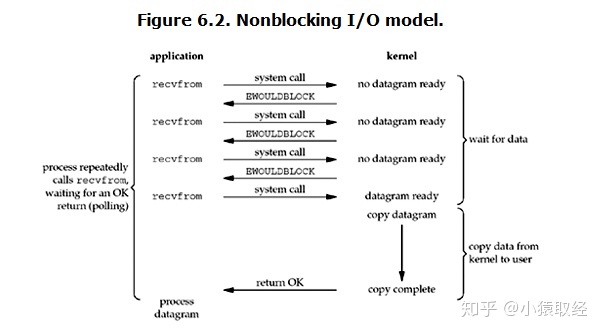
从图中可以看出,当用户进程发出read操作时,如果kernel中的数据还没有准备好,那么它并不会block用户进程,而是立刻返回一个error。从用户进程角度讲 ,它发起一个read操作后,并不需要等待,而是马上就得到了一个结果。用户进程判断结果是一个error时,它就知道数据还没有准备好,于是用户就可以在本次到下次再发起read询问的时间间隔内做其他事情,或者直接再次发送read操作。一旦kernel中的数据准备好了,并且又再次收到了用户进程的system call,那么它马上就将数据拷贝到了用户内存(这一阶段仍然是阻塞的),然后返回。
也就是说非阻塞的recvform系统调用调用之后,进程并没有被阻塞,内核马上返回给进程,如果数据还没准备好,此时会返回一个error。进程在返回之后,可以干点别的事情,然后再发起recvform系统调用。重复上面的过程,循环往复的进行recvform系统调用。这个过程通常被称之为轮询。轮询检查内核数据,直到数据准备好,再拷贝数据到进程,进行数据处理。需要注意,拷贝数据整个过程,进程仍然是属于阻塞的状态。
案例:
服务端
import socket
import time
server = socket.socket()
server.bind(('127.0.0.1', 8081))
server.listen(5)
server.setblocking(False)
# 将所有的网络阻塞变为非阻塞
r_list = []
del_list = []
while True:
try:
conn, addr = server.accept()
r_list.append(conn)
except BlockingIOError:
# time.sleep(0.1)
# print('列表的长度:',len(r_list))
# print('做其他事')
for conn in r_list:
try:
data = conn.recv(1024) # 没有消息 报错
if len(data) == 0: # 客户端断开链接
conn.close() # 关闭conn
# 将无用的conn从r_list删除
del_list.append(conn)
continue
conn.send(data.upper())
except BlockingIOError:
continue
except ConnectionResetError:
conn.close()
del_list.append(conn)
# 挥手无用的链接
for conn in del_list:
r_list.remove(conn)
del_list.clear()
客户端:
import socket
client = socket.socket()
client.connect(('127.0.0.1', 8081))
while True:
client.send(b'hello world')
data = client.recv(1024)
print(data)
但是非阻塞IO模型绝不被推荐。
我们不能否则其优点:能够在等待任务完成的时间里干其他活了(包括提交其他任务,也就是 “后台” 可以有多个任务在“”同时“”执行)。
但是也难掩其缺点:
1. 循环调用recv()将大幅度推高CPU占用率;这也是我们在代码中留一句time.sleep(2)的原因,否则在低配主机下极容易出现卡机情况
2. 任务完成的响应延迟增大了,因为每过一段时间才去轮询一次read操作,而任务可能在两次轮询之间的任意时间完成。这会导致整体数据吞吐量的降低。虽然非阻塞IO给你的感觉非常的牛逼
但是该模型会 长时间占用着CPU并且不干活 让CPU不停的空转
我们实际应用中也不会考虑使用非阻塞IO模型
多路复用IO(IO multiplexing)
IO multiplexing这个词可能有点陌生,但是如果我说select/epoll,大概就都能明白了。有些地方也称这种IO方式为事件驱动IO(event driven IO)。
我们都知道,select/epoll的好处就在于单个process就可以同时处理多个网络连接的IO。
它的基本原理就是select/epoll这个function会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程。它的流程如图:
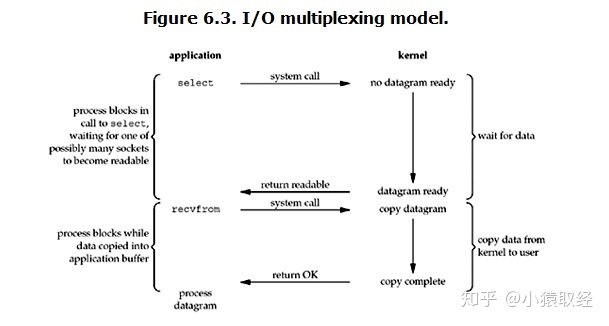
当监管的对象只有一个的时候 其实IO多路复用连阻塞IO都比比不上!!!
但是IO多路复用可以一次性监管很多个对象
server = socket.socket()
conn,addr = server.accept()
监管机制是操作系统本身就有的 如果你想要用该监管机制(select)
需要你导入对应的select模块
案例:
服务端
import socket
import select
server = socket.socket()
server.bind(('127.0.0.1',8080))
server.listen(5)
server.setblocking(False)
read_list = [server]
while True:
r_list, w_list, x_list = select.select(read_list, [], [])
"""
帮你监管
一旦有人来了 立刻给你返回对应的监管对象
"""
# print(res) # ([<socket.socket fd=3, family=AddressFamily.AF_INET, type=SocketKind.SOCK_STREAM, proto=0, laddr=('127.0.0.1', 8080)>], [], [])
# print(server)
# print(r_list)
for i in r_list: #
"""针对不同的对象做不同的处理"""
if i is server:
conn, addr = i.accept()
# 也应该添加到监管的队列中
read_list.append(conn)
else:
res = i.recv(1024)
if len(res) == 0:
i.close()
# 将无效的监管对象 移除
read_list.remove(i)
continue
print(res)
i.send(b'heiheiheiheihei')
客户端
import socket
client = socket.socket()
client.connect(('127.0.0.1',8080))
while True:
client.send(b'hello world')
data = client.recv(1024)
print(data)
监管机制其实有很多
select机制 windows linux都有
poll机制 只在linux有 poll和select都可以监管多个对象 但是poll监管的数量更多
上述select和poll机制其实都不是很完美 当监管的对象特别多的时候
可能会出现 极其大的延时响应
epoll机制 只在linux有
它给每一个监管对象都绑定一个回调机制
一旦有响应 回调机制立刻发起提醒
针对不同的操作系统还需要考虑不同检测机制 书写代码太多繁琐
有一个人能够根据你跑的平台的不同自动帮你选择对应的监管机制
这三种IO多路复用模型在不同的平台有着不同的支持,而epoll在windows下就不支持,好在我们有selectors模块,帮我们默认选择当前平台下最合适的
selectors服务端:
from socket import *
import selectors
sel=selectors.DefaultSelector()
def accept(server_fileobj,mask):
conn,addr=server_fileobj.accept()
sel.register(conn,selectors.EVENT_READ,read)
def read(conn,mask):
try:
data=conn.recv(1024)
if not data:
print('closing',conn)
sel.unregister(conn)
conn.close()
return
conn.send(data.upper()+b'_SB')
except Exception:
print('closing', conn)
sel.unregister(conn)
conn.close()
server_fileobj=socket(AF_INET,SOCK_STREAM)
server_fileobj.setsockopt(SOL_SOCKET,SO_REUSEADDR,1)
server_fileobj.bind(('127.0.0.1',8088))
server_fileobj.listen(5)
server_fileobj.setblocking(False) #设置socket的接口为非阻塞
sel.register(server_fileobj,selectors.EVENT_READ,accept) #相当于网select的读列表里append了一个文件句柄server_fileobj,并且绑定了一个回调函数accept
while True:
events=sel.select() #检测所有的fileobj,是否有完成wait data的
for sel_obj,mask in events:
callback=sel_obj.data #callback=accpet
callback(sel_obj.fileobj,mask) #accpet(server_fileobj,1)
#客户端
from socket import *
c=socket(AF_INET,SOCK_STREAM)
c.connect(('127.0.0.1',8088))
while True:
msg=input('>>: ')
if not msg:continue
c.send(msg.encode('utf-8'))
data=c.recv(