表
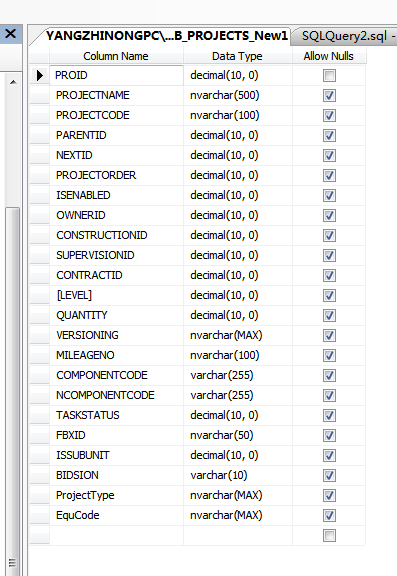
表的创建脚本
CREATE TABLE [dbo].[TB_PROJECTS_New1]( [PROID] [decimal](10, 0) NOT NULL, [PROJECTNAME] [nvarchar](500) NULL, [PROJECTCODE] [nvarchar](100) NULL, [PARENTID] [decimal](10, 0) NULL, [NEXTID] [decimal](10, 0) NULL, [PROJECTORDER] [decimal](10, 0) NULL, [ISENABLED] [decimal](10, 0) NULL, [OWNERID] [decimal](10, 0) NULL, [CONSTRUCTIONID] [decimal](10, 0) NULL, [SUPERVISIONID] [decimal](10, 0) NULL, [CONTRACTID] [decimal](10, 0) NULL, [LEVEL] [decimal](10, 0) NULL, [QUANTITY] [decimal](10, 0) NULL, [VERSIONING] [nvarchar](max) NULL, [MILEAGENO] [nvarchar](100) NULL, [COMPONENTCODE] [varchar](255) NULL, [NCOMPONENTCODE] [varchar](255) NULL, [TASKSTATUS] [decimal](10, 0) NULL, [FBXID] [nvarchar](50) NULL, [ISSUBUNIT] [decimal](10, 0) NULL, [BIDSION] [varchar](10) NULL, [ProjectType] [nvarchar](max) NULL, [EquCode] [nvarchar](max) NULL ) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
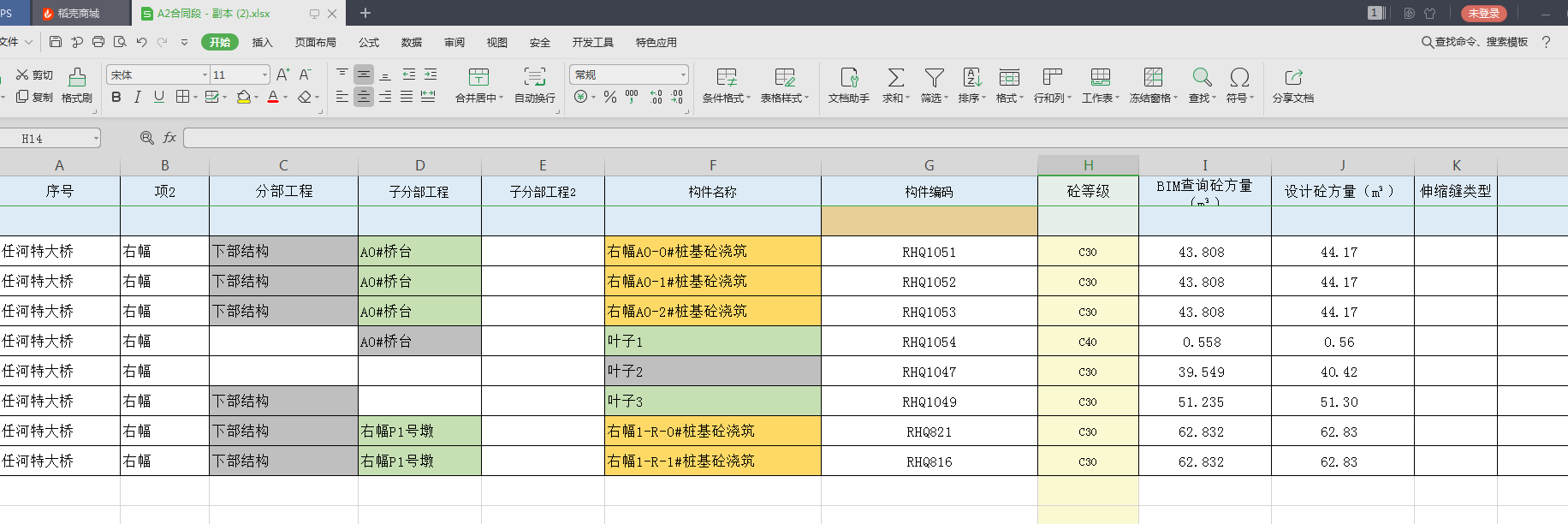
Excel的格式
导入后的样子
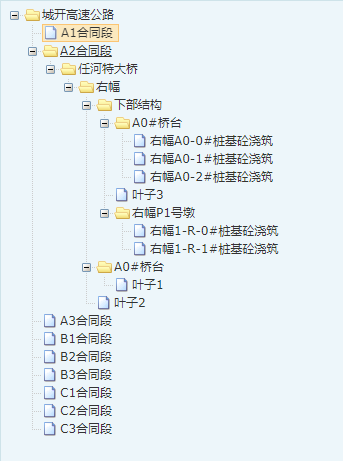
数据库的样子:

导入需求:
节点从左到右,依次导入,树的层级递增。
不导入为空的单元格。
导入的列 从第一列 到 构件名称(包含构件名称)那列,其它列,不作为节点导入到数据库。
构件编码 作为 节点的属性导入。构件编码 做为 构件名称那个节点(或者是构件编码左边的节点,有可能构件名称为空) 的属性 导入。
每个节点 都有一个属性,属性存Excel的列名
砼等级这列(包含砼等级这列),及右边的所有列,不在导入数据的范围内,跟导入数据没有关系。
Excel的列名有时候会不对,或者很乱,但是构件编码这列有,构件名称可能会没有,分部工程可能没有,或者多了几个分部工程(Excel列名肯定不会重复)
Excel需要做一些校验,避免数据源错误
01、隐藏行、隐藏列、
02、行高不足(可配置)
03、列名强制校验(必须包含指定列)
04、单元格为公式(配置项为不支持公式的情况)
05、构件编码为空
06、构件编码包含中文
07、构件编码重复
08、构件编码过少(可配置)
09、同行构件名称重复
10、构件名称重复
导入思路:
把Excel转换为文本,
导入数据的时候,使用格式1的文本,
导入属性 列名的时候,使用格式2的文本。
格式1

格式2

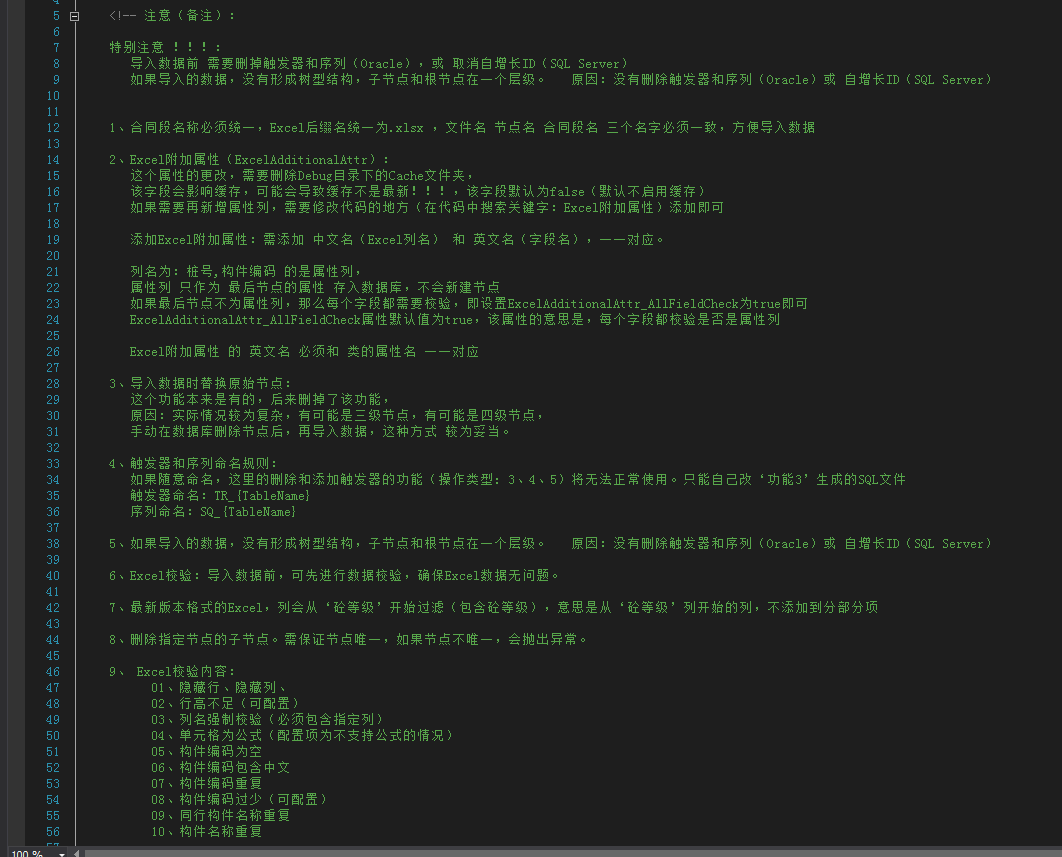
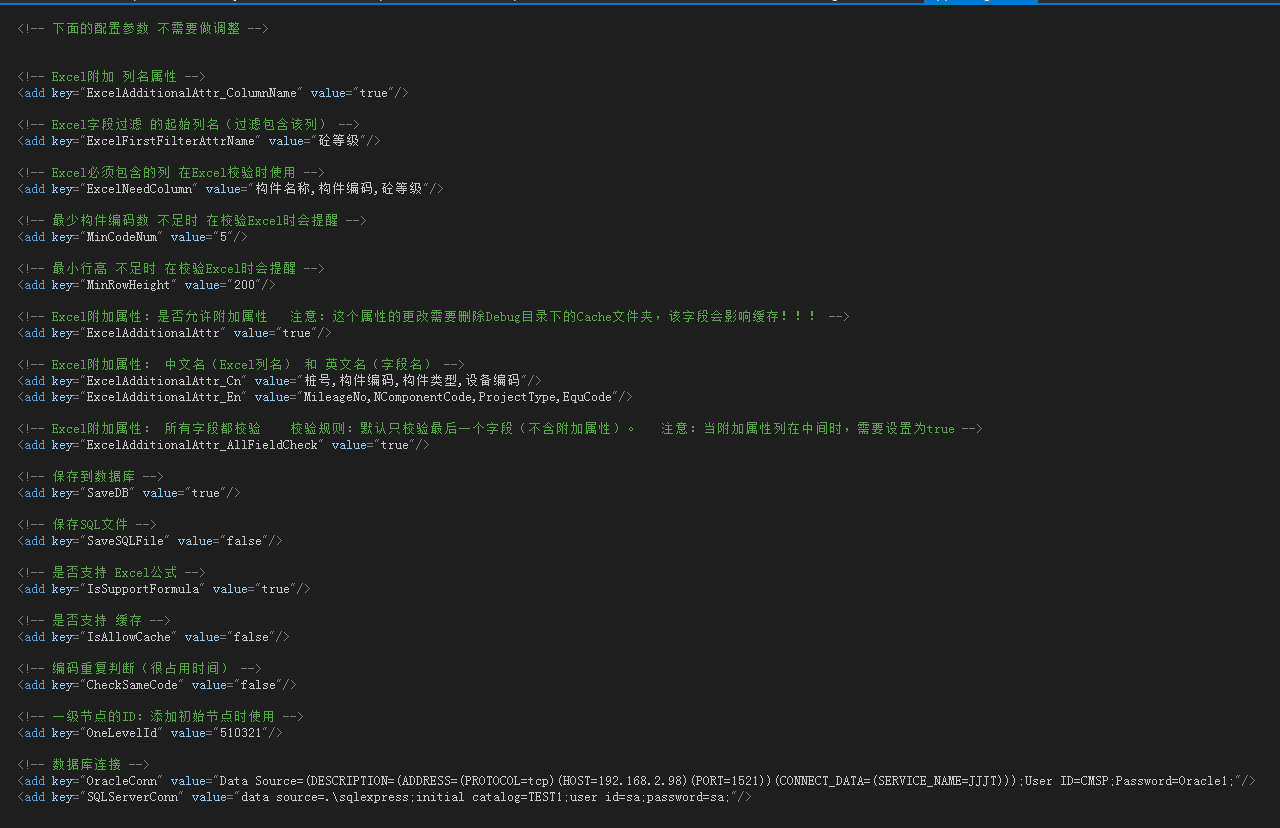
程序的配置参数截图:

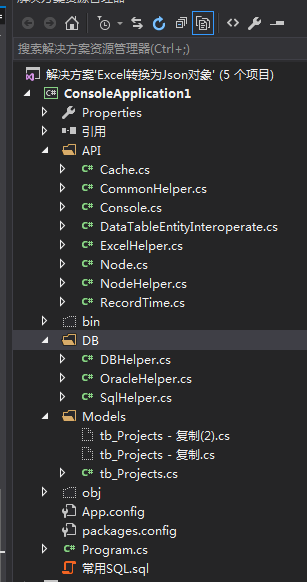
项目的结构:
导入时有一些算法的判断,加快了导入的速度,也做了一些该有的缓存。
对性能影响比较大的一个算法:
比如,导入‘右幅A0-1#桩基砼浇筑’节点的时候,不需要再对‘任河特大桥 右幅 下部结构 A0#桥台’ 这几个节点进行判断了,直接记录与上一行不同的地方,用共用的parentId。
优化思路:
一开始是没有注意性能的,数据一多,那个导入速度慢死,但是数据的正确性确实也是保证了的,后来就监控各个方法的执行效率,看哪些方法执行的次数多,占用的时间多,相应的优化该方法。
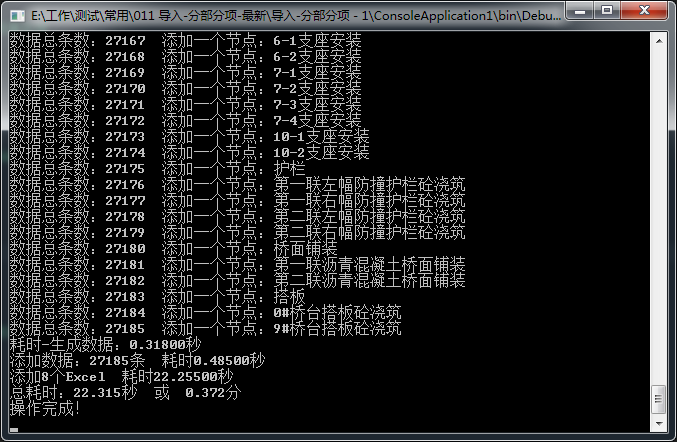
现在导入的数据可能有个10万+吧
导入测试1:
导入的Excel: