看到篇博文,https://blog.csdn.net/young2415/article/details/82795688
需求是需要统计部门礼品数量,自己简单绘制了个表格,如下:
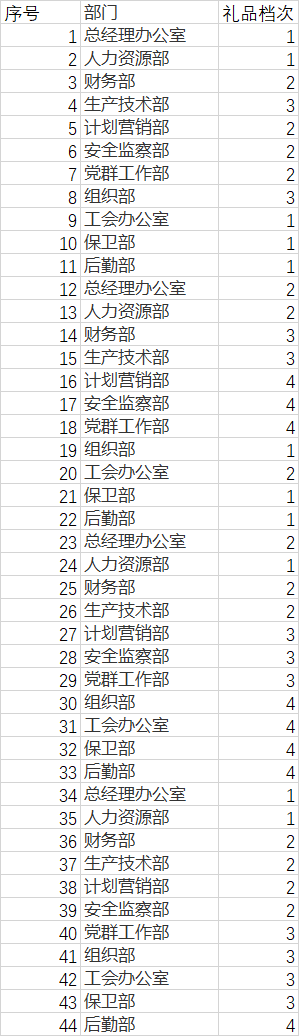

大意是,每个部门的员工发福利,有礼品档次(见表一),每个档次礼品对应不同礼品(见表二)
假设表一在test.xlsx的sheet1中,表二在test.xlsx的sheet2中,运算结果为同级目录下的result.xlsx,用python pandas改写代码如下:
import pandas as pd
df1 = pd.read_excel('test.xlsx', sheet_name=0, index_col='序号') # 读取表1
df2 = pd.read_excel('test.xlsx', sheet_name=1).fillna(method='pad') # 读取表2
df_result = pd.DataFrame(index=set(df1['部门']), columns=set(df2['产品'])).fillna(0) # 运算结果
for each_dept in set(df1['部门']): # 遍历每个部门
df_each_dept = df1[df1['部门'] == each_dept] # 在表1中取出每个部门的礼品情况
for each_dept_welfare in df_each_dept['礼品档次']: # 遍历每个部门的”礼品档次“:
for each_welfare in df2[df2['标准'] == each_dept_welfare]['产品']:
df_result.loc[each_dept, each_welfare] += 1 # 该部门对应的礼品数值+1
writer = pd.ExcelWriter('result.xlsx') # 保存结果
df_result.to_excel(writer, 'result')
writer.save()
改写后,不仅减少代码数量,而且无需事先建立礼品列表。
运算result.xlsx结果如下:
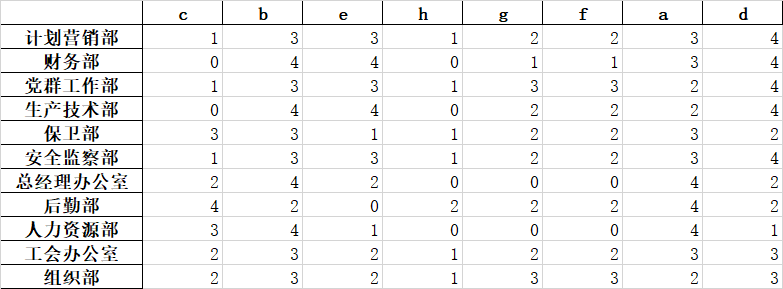
备注:遍历每个部门时,可以用groupby(),这样还可以少写一句代码,
import pandas as pd df1 = pd.read_excel('test.xlsx', sheet_name=0, index_col='序号') df2 = pd.read_excel('test.xlsx', sheet_name=1).fillna(method='pad') df_result = pd.DataFrame(index=set(df1['部门']), columns=set(df2['产品'])).fillna(0) for dept, df_dept in df1.groupby('部门'): for dept_welfare in df_dept['礼品档次']: for welfare in df2[df2['标准'] == dept_welfare]['产品']: df_result.loc[dept, welfare] += 1 writer = pd.ExcelWriter('result.xlsx') df_result.to_excel(writer, 'result') writer.save()