一、字符编码
1.1 了解字符编码的知识储备
1. 文本编辑器存取文件的原理(nodepad++,pycharm,word)
打开编辑器就打开了启动了一个进程,是在内存中的,所以在编辑器编写的内容也都是存放与内存中的,断电后数据丢失
因而需要保存到硬盘上,点击保存按钮,就从内存中把数据刷到了硬盘上。
在这一点上,我们编写一个py文件(没有执行),跟编写其他文件没有任何区别,都只是在编写一堆字符而已。
2. python解释器执行py文件的原理 ,例如python test.py
第一阶段:python解释器启动,此时就相当于启动了一个文本编辑器
第二阶段:python解释器相当于文本编辑器,去打开test.py文件,从硬盘上将test.py的文件内容读入到内存中
第三阶段:python解释器解释执行刚刚加载到内存中test.py的代码
总结:
- python解释器是解释执行文件内容的,因而python解释器具备读py文件的功能,这一点与文本编辑器一样
- 与文本编辑器不一样的地方在于,python解释器不仅可以读文件内容,还可以执行文件内容
1.2 什么是字符编码
计算机要想工作必须通电,也就是说‘电’驱使计算机干活,而‘电’的特性,就是高低电平(高低平即二进制数1,低电平即二进制数0),也就是说计算机只认识数字
编程的目的是让计算机干活,而编程的结果说白了只是一堆字符,也就是说我们编程最终要实现的是:一堆字符驱动计算机干活
所以必须经过一个过程:
字符--------(翻译过程)------->数字
这个过程实际就是一个字符如何对应一个特定数字的标准,这个标准称之为字符编码。
1.3 字符编码的发展史
阶段一:现代计算机起源于美国,最早诞生也是基于英文考虑的ASCII
ASCII:一个Bytes代表一个字符(英文字符/键盘上的所有其他字符),1Bytes=8bit,8bit可以表示0-2**8-1种变化,即可以表示256个字符
ASCII最初只用了后七位,127个数字,已经完全能够代表键盘上所有的字符了(英文字符/键盘的所有其他字符)
后来为了将拉丁文也编码进了ASCII表,将最高位也占用了
阶段二:为了满足中文,中国人定制了GBK
GBK:2Bytes代表一个字符
为了满足其他国家,各个国家纷纷定制了自己的编码
日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里
阶段三:各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。
于是产生了unicode, 统一用2Bytes代表一个字符, 2**16-1=65535,可代表6万多个字符,因而兼容万国语言
但对于通篇都是英文的文本来说,这种编码方式无疑是多了一倍的存储空间(二进制最终都是以电或者磁的方式存储到存储介质中的)
于是产生了UTF-8,对英文字符只用1Bytes表示,对中文字符用3Bytes
需要强调的一点是:
unicode:简单粗暴,所有字符都是2Bytes,优点是字符->数字的转换速度快,缺点是占用空间大
utf-8:精准,对不同的字符用不同的长度表示,优点是节省空间,缺点是:字符->数字的转换速度慢,因为每次都需要计算出字符需要多长的Bytes才能够准确表示
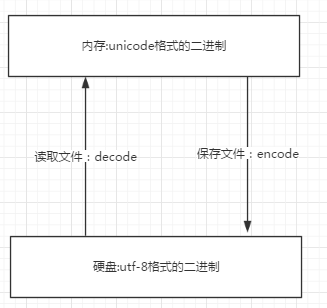
- 内存中使用的编码是unicode,用空间换时间(程序都需要加载到内存才能运行,因而内存应该是尽可能的保证快)
- 硬盘中或者网络传输用utf-8,网络I/O延迟或磁盘I/O延迟要远大与utf-8的转换延迟,而且I/O应该是尽可能地节省带宽,保证数据传输的稳定性。
1.4 文本编辑器一锅端
1.4.1 文本编辑器nodpad++




1.4.2 文本编辑器pycharm
以gbk格式保存

以utf-8格式打开

总结:
无论是何种编辑器,要防止文件出现乱码(请一定注意,存放一段代码的文件也仅仅只是一个普通文件而已,此处指的是文件没有执行前,我们打开文件时出现的乱码)
核心法则就是,文件以什么编码保存的,就以什么编码方式打开
1.4.3 程序的执行
python test.py (我再强调一遍,执行test.py的第一步,一定是先将文件内容读入到内存中)
阶段一:启动python解释器
阶段二:python解释器此时就是一个文本编辑器,负责打开文件test.py,即从硬盘中读取test.py的内容到内存中
此时,python解释器会读取test.py的第一行内容,#coding:utf-8,来决定以什么编码格式来读入内存,这一行就是来设定python解释器这个软件的编码使用的编码格式这个编码,
可以用sys.getdefaultencoding()查看,如果不在python文件指定头信息#-*-coding:utf-8-*-,那就使用默认的
python2中默认使用ascii,python3中默认使用utf-8


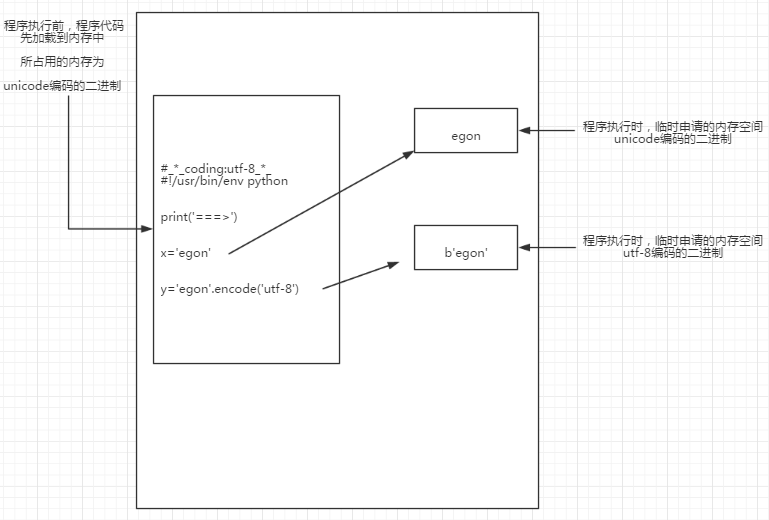
阶段三:读取已经加载到内存的代码(unicode编码的二进制),然后执行,执行过程中可能会开辟新的内存空间,比如x="egon"
内存的编码使用unicode,不代表内存中全都是unicode编码的二进制,
在程序执行之前,内存中确实都是unicode编码的二进制,比如从文件中读取了一行x="egon",其中的x,等号,引号,地位都一样,都是普通字符而已,都是以unicode编码的二进制形式存放与内存中的
但是程序在执行过程中,会申请内存(与程序代码所存在的内存是俩个空间),可以存放任意编码格式的数据,比如x="egon",会被python解释器识别为字符串,会申请内存空间来存放"hello",然后让x指向该内存地址,此时新申请的该内存地址保存也是unicode编码的egon,如果代码换成x="egon".encode('utf-8'),那么新申请的内存空间里存放的就是utf-8编码的字符串egon了
针对python3如下图
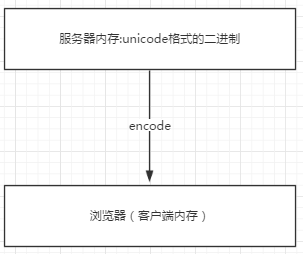
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器
如果服务端encode的编码格式是utf-8, 客户端内存中收到的也是utf-8编码的二进制。
1.4.4 python2与python3的区别
1.4.4.1 在python2中有两种字符串类型str和unicode
str类型
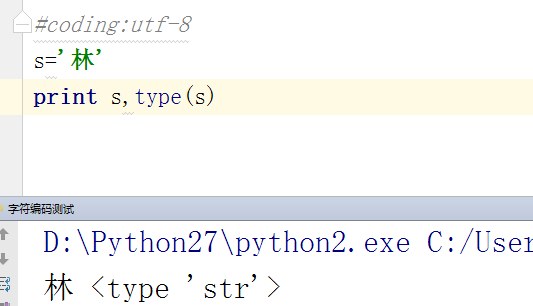
当python解释器执行到产生字符串的代码时(例如s='林'),会申请新的内存地址,然后将'林'encode成文件开头指定的编码格式,这已经是encode之后的结果了,所以s只能decode
1 #_*_coding:gbk_*_
2 #!/usr/bin/env python
3
4 x='林'
5 # print x.encode('gbk') #报错
6 print x.decode('gbk') #结果:林
所以很重要的一点是:
在python2中,str就是编码后的结果bytes,str=bytes,所以在python2中,unicode字符编码的结果是str/bytes


#coding:utf-8
s='林' #在执行时,'林'会被以conding:utf-8的形式保存到新的内存空间中
print repr(s) #'xe6x9ex97' 三个Bytes,证明确实是utf-8
print type(s) #<type 'str'>
s.decode('utf-8')
# s.encode('utf-8') #报错,s为编码后的结果bytes,所以只能decode
unicode类型
当python解释器执行到产生字符串的代码时(例如s=u'林'),会申请新的内存地址,然后将'林'以unicode的格式存放到新的内存空间中,所以s只能encode,不能decode
s=u'林'
print repr(s) #u'u6797'
print type(s) #<type 'unicode'>
# s.decode('utf-8') #报错,s为unicode,所以只能encode
s.encode('utf-8')
打印到终端
对于print需要特别说明的是:
当程序执行时,比如
x='林'
print(x) #这一步是将x指向的那块新的内存空间(非代码所在的内存空间)中的内存,打印到终端,而终端仍然是运行于内存中的,所以这打印可以理解为从内存打印到内存,即内存->内存,unicode->unicode
对于unicode格式的数据来说,无论怎么打印,都不会乱码
python3中的字符串与python2中的u'字符串',都是unicode,所以无论如何打印都不会乱码
在pycharm中

在windows终端

但是在python2中存在另外一种非unicode的字符串,此时,print x,会按照终端的编码执行x.decode('终端编码'),变成unicode后,再打印,此时终端编码若与文件开头指定的编码不一致,乱码就产生了
在pycharm中(终端编码为utf-8,文件编码为utf-8,不会乱码)
在windows终端(终端编码为gbk,文件编码为utf-8,乱码产生)
1.4.4.2 在python三种也有两种字符串类型str和bytes
str是unicode
#coding:utf-8
s='林' #当程序执行时,无需加u,'林'也会被以unicode形式保存新的内存空间中,
#s可以直接encode成任意编码格式
s.encode('utf-8')
s.encode('gbk')
print(type(s)) #<class 'str'>
bytes是bytes
#coding:utf-8
s='林' #当程序执行时,无需加u,'林'也会被以unicode形式保存新的内存空间中,
#s可以直接encode成任意编码格式
s1=s.encode('utf-8')
s2=s.encode('gbk')
print(s) #林
print(s1) #b'xe6x9ex97' 在python3中,是什么就打印什么
print(s2) #b'xc1xd6' 同上
print(type(s)) #<class 'str'>
print(type(s1)) #<class 'bytes'>
print(type(s2)) #<class 'bytes'>
二、函数
1 数学定义的函数与python中的函数
初中数学函数定义:一般的,在一个变化过程中,如果有两个变量x和y,并且对于x的每一个确定的值,y都有唯一确定的值与其对应,那么我们就把x称为自变量,把y称为因变量,y是x的函数。自变量x的取值范围叫做这个函数的定义域
例如y=2*x
python中函数定义:函数是逻辑结构化和过程化的一种编程方法。
1 python中函数定义方法: 2 3 def test(x): 4 "The function definitions" 5 x+=1 6 return x 7 8 def:定义函数的关键字 9 test:函数名 10 ():内可定义形参 11 "":文档描述(非必要,但是强烈建议为你的函数添加描述信息) 12 x+=1:泛指代码块或程序处理逻辑 13 return:定义返回值
调用运行:可以带参数也可以不带
函数名()
补充:
1.编程语言中的函数与数学意义的函数是截然不同的俩个概念,编程语言中的函数是通过一个函数名封装好一串用来完成某一特定功能的逻辑,数学定义的函数就是一个等式,等式在传入因变量值x不同会得到一个结果y,这一点与编程语言中类似(也是传入一个参数,得到一个返回值),不同的是数学意义的函数,传入值相同,得到的结果必然相同且没有任何变量的修改(不修改状态),而编程语言中的函数传入的参数相同返回值可不一定相同且可以修改其他的全局变量值(因为一个函数a的执行可能依赖于另外一个函数b的结果,b可能得到不同结果,那即便是你给a传入相同的参数,那么a得到的结果也肯定不同)
2.函数式编程就是:先定义一个数学函数(数学建模),然后按照这个数学模型用编程语言去实现它。至于具体如何实现和这么做的好处,且看后续的函数式编程。
2 为何使用函数
背景提要
写一个监控程序,监控服务器的系统状况,当cpu\memory\disk等指标的使用量超过阀值时即发邮件报警,掏空了所有的知识量,写出了以下代码
1 while True: 2 if cpu利用率 > 90%: 3 #发送邮件提醒 4 连接邮箱服务器 5 发送邮件 6 关闭连接 7 8 if 硬盘使用空间 > 90%: 9 #发送邮件提醒 10 连接邮箱服务器 11 发送邮件 12 关闭连接 13 14 if 内存占用 > 80%: 15 #发送邮件提醒 16 连接邮箱服务器 17 发送邮件 18 关闭连接
上面的代码实现了功能,但即使是邻居老王也看出了端倪,老王亲切的摸了下你家儿子的脸蛋,说,你这个重复代码太多了,每次报警都要重写一段发邮件的代码,太low了,这样干存在2个问题:
- 代码重复过多,一个劲的copy and paste不符合高端程序员的气质
- 如果日后需要修改发邮件的这段代码,比如加入群发功能,那你就需要在所有用到这段代码的地方都修改一遍
你觉得老王说的对,你也不想写重复代码,但又不知道怎么搞,老王好像看出了你的心思,此时他抱起你儿子,笑着说,其实很简单,只需要把重复的代码提取出来,放在一个公共的地方,起个名字,以后谁想用这段代码,就通过这个名字调用就行了,如下
def 发送邮件(内容)
#发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接
while True:
if cpu利用率 > 90%:
发送邮件('CPU报警')
if 硬盘使用空间 > 90%:
发送邮件('硬盘报警')
if 内存占用 > 80%:
发送邮件('内存报警')
你看着老王写的代码,气势恢宏、磅礴大气,代码里透露着一股内敛的傲气,心想,老王这个人真是不一般,突然对他的背景更感兴趣了,问老王,这些花式玩法你都是怎么知道的? 老王亲了一口你儿子,捋了捋不存在的胡子,淡淡的讲,“老夫,年少时,师从京西沙河淫魔银角大王 ”, 你一听“银角大王”这几个字,不由的娇躯一震,心想,真nb,怪不得代码写的这么6, 这“银角大王”当年在江湖上可是数得着的响当当的名字,只可惜后期纵欲过度,卒于公元2016年, 真是可惜了,只留下其哥哥孤守当年兄弟俩一起打下来的江山。 此时你看着的老王离开的身影,感觉你儿子跟他越来越像了。。。
总结使用函数的好处:
1.代码重用
2.保持一致性,易维护
3.可扩展性
3 函数和过程
过程定义:过程就是简单特殊没有返回值的函数
这么看来我们在讨论为何使用函数的的时候引入的函数,都没有返回值,没有返回值就是过程,没错,但是在python中有比较神奇的事情
1 def test01(): 2 msg='hello The little green frog' 3 print msg 4 5 def test02(): 6 msg='hello WuDaLang' 7 print msg 8 return msg 9 10 11 t1=test01() 12 13 t2=test02() 14 15 16 print 'from test01 return is [%s]' %t1 17 print 'from test02 return is [%s]' %t2
总结:当一个函数/过程没有使用return显示的定义返回值时,python解释器会隐式的返回None,
所以在python中即便是过程也可以算作函数。
1 def test01():
2 pass
3
4 def test02():
5 return 0
6
7 def test03():
8 return 0,10,'hello',['alex','lb'],{'WuDaLang':'lb'}
9
10 t1=test01()
11 t2=test02()
12 t3=test03()
13
14
15 print 'from test01 return is [%s]: ' %type(t1),t1
16 print 'from test02 return is [%s]: ' %type(t2),t2
17 print 'from test03 return is [%s]: ' %type(t3),t3
总结:
返回值数=0:返回None
返回值数=1:返回object
返回值数>1:返回tuple
4 函数参数
1.形参变量只有在被调用时才分配内存单元,在调用结束时,即刻释放所分配的内存单元。因此,形参只在函数内部有效。函数调用结束返回主调用函数后则不能再使用该形参变量
2.实参可以是常量、变量、表达式、函数等,无论实参是何种类型的量,在进行函数调用时,它们都必须有确定的值,以便把这些值传送给形参。因此应预先用赋值,输入等办法使参数获得确定值

3.位置参数和关键字(标准调用:实参与形参位置一一对应;关键字调用:位置无需固定)
4.默认参数
5.参数组
三、Python基础之文件处理
1 文件处理流程
- 打开文件,得到文件句柄并赋值给一个变量
- 通过句柄对文件进行操作
- 关闭文件
正趣果上果 Interesting fruit fruit 词:郭婞 曲:陈粒 编曲/混音/和声:燕池 萧:吗子 Words: Guo 婞 Song: Chen tablets Arrange / Mix / Harmony: Yan Chi Xiao: Well 你佩桃木降妖剑 他会一招不要脸 哇呀呀呀 输在没有钱 输在没有钱 You wear peach down demon sword He will shamelessly Wow yeah Lost in the absence of money Lost in the absence of money 你愿终老不羡仙 谁料温柔终老空了长生殿 哎唏唏唏 败给好容颜 败给好容颜 You would like to end the old do not envy cents Mummy gentle death of the empty palace Hey Xi Xi Lost to good appearance Lost to good appearance 人生在世三万天 趣果有间 孤独无解 苦练含笑半步癫 呐我去给你煮碗面 Life is thirty thousand days Fun fruit there is no solution between solitude Hard practicing smiling half-step epilepsy I'll go and cook your bowl 心怀啮雪大志愿 被人称作小可怜 呜呼呼呼 突样未成年 突样未成年 Heart of the snow big volunteer Was called a small pitiful Alas Sudden sample of minor Sudden sample of minor 本欲歃血定风月 乌飞兔走光阴只负尾生约 噫嘘嘘嘘 真心怕火炼 真心也怕火炼 The desire to set the wind blood months Wu Flying Rabbit only time to bear the tail about 噫 boo boo Really afraid of fire refining Really afraid of fire 人生在世三万天 趣果有间 孤独无解 苦练含笑半步癫 呐我去给你煮碗面 Life is thirty thousand days Fun fruit there is no solution between solitude Hard practicing smiling half-step epilepsy I'll go and cook your bowl 是非对错二十念 十方观遍 庸人恋阙 自学睡梦罗汉拳 吓 冇知酱紫好危险 Right and wrong twenty read square view over the Yong love Que Self - study sleep Lohan boxing Scare know that a good risk of Jiang Xi 示范文件内容
2 基本操作
2.1 文件操作基本流程初探
f = open('chenli.txt') #打开文件
first_line = f.readline()
print('first line:',first_line) #读一行
print('我是分隔线'.center(50,'-'))
data = f.read()# 读取剩下的所有内容,文件大时不要用
print(data) #打印读取内容
f.close() #关闭文件
2.2 文件编码
文件保存编码如下:
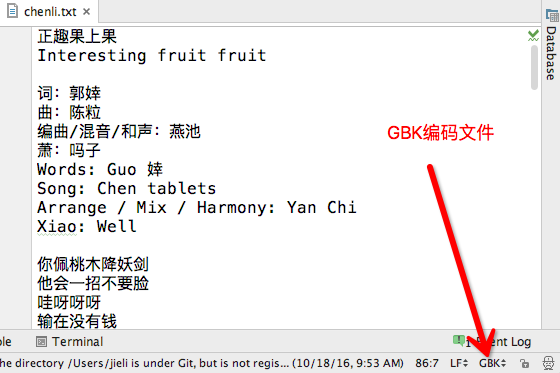
此刻错误的打开方式:
f=open('chenli.txt',encoding='utf-8')
f.read()
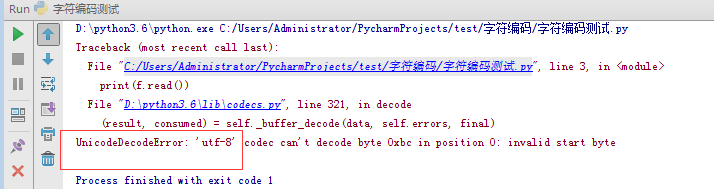
正确的打开方式:
#不指定打开编码,默认使用操作系统的编码,windows为gbk,linux为utf-8,与解释器编码无关
f=open('chenli.txt',encoding='gbk') #在windows中默认使用的也是gbk编码,此时不指定编码也行
f.read()
2.3 文件打开模式
1 文件句柄 = open('文件路径', '模式')
打开文件时,需要指定文件路径和以何等方式打开文件,打开后,即可获取该文件句柄,日后通过此文件句柄对该文件操作。
打开文件的模式有:
- r ,只读模式【默认模式,文件必须存在,不存在则抛出异常】
- w,只写模式【不可读;不存在则创建;存在则清空内容】
- x, 只写模式【不可读;不存在则创建,存在则报错】
- a, 追加模式【可读; 不存在则创建;存在则只追加内容】
"+" 表示可以同时读写某个文件
- r+, 读写【可读,可写】
- w+,写读【可读,可写】
- x+ ,写读【可读,可写】
- a+, 写读【可读,可写】
"b"表示以字节的方式操作
- rb 或 r+b
- wb 或 w+b
- xb 或 w+b
- ab 或 a+b
注:以b方式打开时,读取到的内容是字节类型,写入时也需要提供字节类型,不能指定编码
2.4 文件内置函数flush
flush原理:
- 文件操作是通过软件将文件从硬盘读到内存
- 写入文件的操作也都是存入内存缓冲区buffer(内存速度快于硬盘,如果写入文件的数据都从内存刷到硬盘,内存与硬盘的速度延迟会被无限放大,效率变低,所以要刷到硬盘的数据我们统一往内存的一小块空间即buffer中放,一段时间后操作系统会将buffer中数据一次性刷到硬盘)
- flush即,强制将写入的数据刷到硬盘
滚动条:
import sys,time
for i in range(10):
sys.stdout.write('#')
sys.stdout.flush()
time.sleep(0.2)
2.5 文件内光标移动
注意:read(3)代表读取3个字符,其余的文件内光标移动都是以字节为单位如seek,tell,read,truncate
整理中
2.6 open函数详解
1. open()语法
open(file[, mode[, buffering[, encoding[, errors[, newline[, closefd=True]]]]]])
open函数有很多的参数,常用的是file,mode和encoding
file文件位置,需要加引号
mode文件打开模式,见下面3
buffering的可取值有0,1,>1三个,0代表buffer关闭(只适用于二进制模式),1代表line buffer(只适用于文本模式),>1表示初始化的buffer大小;
encoding表示的是返回的数据采用何种编码,一般采用utf8或者gbk;
errors的取值一般有strict,ignore,当取strict的时候,字符编码出现问题的时候,会报错,当取ignore的时候,编码出现问题,程序会忽略而过,继续执行下面的程序。
newline可以取的值有None,
,
, ”, ‘
',用于区分换行符,但是这个参数只对文本模式有效;
closefd的取值,是与传入的文件参数有关,默认情况下为True,传入的file参数为文件的文件名,取值为False的时候,file只能是文件描述符,什么是文件描述符,就是一个非负整数,在Unix内核的系统中,打开一个文件,便会返回一个文件描述符。
2. Python中file()与open()区别
两者都能够打开文件,对文件进行操作,也具有相似的用法和参数,但是,这两种文件打开方式有本质的区别,file为文件类,用file()来打开文件,相当于这是在构造文件类,而用open()打开文件,是用python的内建函数来操作,建议使用open
3. 参数mode的基本取值
| Character | Meaning |
| ‘r' | open for reading (default) |
| ‘w' | open for writing, truncating the file first |
| ‘a' | open for writing, appending to the end of the file if it exists |
| ‘b' | binary mode |
| ‘t' | text mode (default) |
| ‘+' | open a disk file for updating (reading and writing) |
| ‘U' | universal newline mode (for backwards compatibility; should not be used in new code) |
r、w、a为打开文件的基本模式,对应着只读、只写、追加模式;
b、t、+、U这四个字符,与以上的文件打开模式组合使用,二进制模式,文本模式,读写模式、通用换行符,根据实际情况组合使用、
常见的mode取值组合
1 r或rt 默认模式,文本模式读
2 rb 二进制文件
3
4 w或wt 文本模式写,打开前文件存储被清空
5 wb 二进制写,文件存储同样被清空
6
7 a 追加模式,只能写在文件末尾
8 a+ 可读写模式,写只能写在文件末尾
9
10 w+ 可读写,与a+的区别是要清空文件内容
11 r+ 可读写,与a+的区别是可以写到文件任何位置
2.7 上下文管理
with open('a.txt','w') as f:
pass
with open('a.txt','r') as read_f,open('b.txt','w') as write_f:
data=read_f.read()
write_f.write(data)
2.8 文件的修改
import os
with open('a.txt','r',encoding='utf-8') as read_f,
open('.a.txt.swap','w',encoding='utf-8') as write_f:
for line in read_f:
if line.startswith('hello'):
line='哈哈哈
'
write_f.write(line)
os.remove('a.txt')
os.rename('.a.txt.swap','a.txt')