P1 机器学习介绍
本笔记主要是参加DataWhale组织的8月李宏毅《深度学习》入门,本人有一定的基础,参加的目的是夯实基础,跟各位大佬交流学习,也是敦促自己学习。少说废话直入正题。
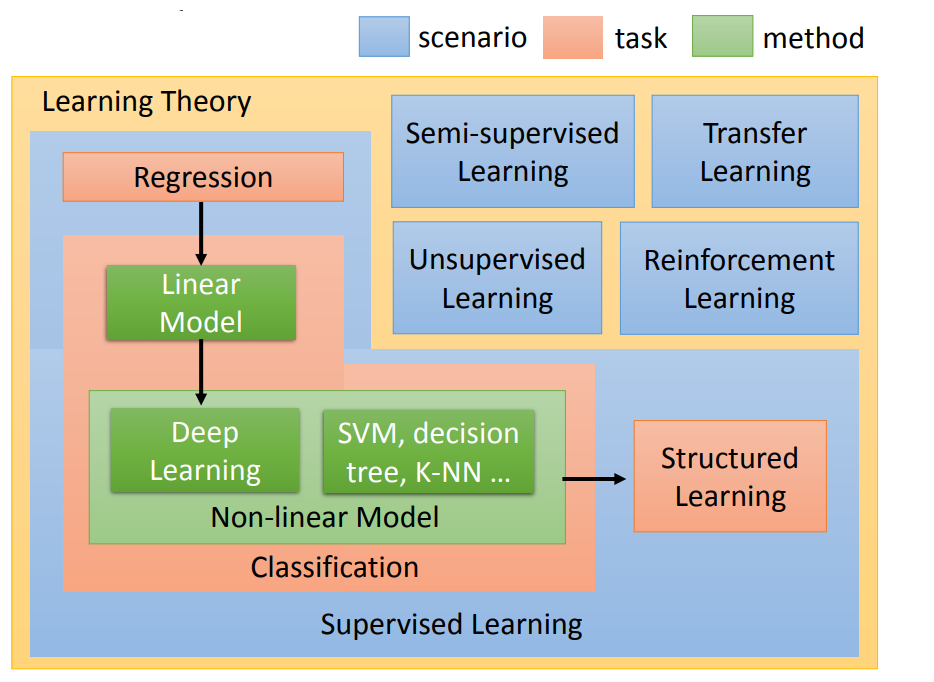
第一小节主要是介绍性内容,重点讲解了有监督学习、无监督学习、半监督学习、迁移学习、强化学习基本概念,以及在各领域的运用和面临的挑战。如图所示:
基本概念
有监督学习:已知数据和其一一对应的标签,用这些带有标签的数据训练一个模型,通过该模型将输入数据映射到标签的过程。比如:一些图片是猫,一些图片不是猫,先训练一个算法(模型),当输入新输入一张图片时模型告诉我们这张图片是不是猫。
无监督学习:一直的数据没有标签,设计一个模型,让模型自己寻找彼此间的联系,最终将所有数据映射到多个不同标签的过程。相对于有监督学习,无监督学习是一类比较困难的问题,但却是现实中最常见的问题,也是AI未来趋势。
半监督学习:已知数据和部分一一对应的标签,有一部分数据的标签未知,训练一个模型,学习已知标签和未知标签的数据,将输入数据映射到标签的过程。半监督相当于有监督学习与无监督学习的折衷方法。
迁移学习:神经网络需要用数据来训练,它从数据中获得信息,进而把它们转换成相应的权重。这些权重能够被提取出来,迁移到其他的神经网络中,我们“迁移”了这些学来的特征,就不需要从零开始训练一个神经网络了 。针对训练数据集小,防止过拟合使用。运用迁移学习需要注意如下几个场景:
1)新数据集比较小且和原数据集相似。因为新数据集比较小,如果fine-tune可能会过拟合;又因为新旧数据集类似,我们期望他们高层特征类似,可以使用预训练网络当做特征提取器,用提取的特征训练线性分类器。
2)新数据集大且和原数据集相似。因为新数据集足够大,可以fine-tune整个网络。
3)新数据集小且和原数据集不相似。新数据集小,最好不要fine-tune,和原数据集不类似,最好也不使用高层特征。这时可是使用前面层的特征来训练SVM分类器。
4)新数据集大且和原数据集不相似。因为新数据集足够大,可以重新训练。但是实践中fine-tune预训练模型还是有益的。新数据集足够大,可以fine-tine整个网络。
强化学习:强调如何基于环境而行动,以取得最大化的预期利益。其灵感来源于心理学中的行为主义理论,即有机体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的预期,产生能获得最大利益的习惯性行为。