1、倒排索引
ES使用倒排索引的结构做快速的全文搜索。倒排索引为文档中的出现唯一的单词列表以及每个单词所在文档中的位置。
2、分析
首先, 标记化一个文本块为适用于倒排索引单独的词(term)
然后标准化这些词为标准形式, 提高它们的“可搜索性”或“查全率”
这个工作是分析器(analyzer)完成的。 一个分析器(analyzer)只是一个包装用于将三个功能放到一个包里:
字符过滤器:首先字符串经过字符过滤器(character filter), 它们的工作是在标记化前处理字符串。 字符过滤器能够去除HTML标记, 或者转换 "&" 为 "and"
分词器:分词器(tokenizer)被标记化成独立的词。 一个简单的分词器(tokenizer)可以根据空格或逗号将单词分开( 译者注: 这个在中文中不适用)
标记过滤:每个词都通过所有标记过滤(token filters), 它可以修改词( 例如将 "Quick" 转为小写) , 去掉词( 例如停用词像 "a" 、 "and" 、 "the" 等等) , 或者增加词( 例如同义词像 "jump" 和 "leap" )
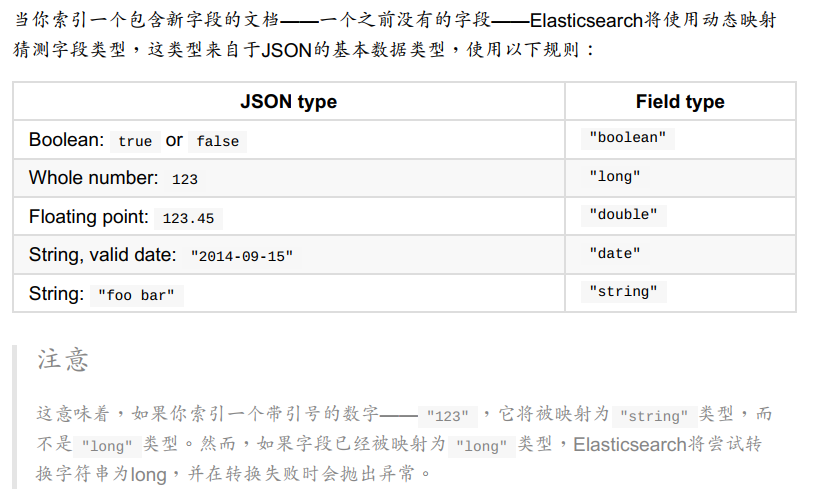
3、映射
为了能够把日期字段处理成日期, 把数字字段处理成数字, 把字符串字段处理成全文本( Full-text) 或精确的字符串值, Elasticsearch需要知道每个字段里面都包含了什么类型。
这些类型和字段的信息存储( 包含) 在映射( mapping) 中 。