花了四小时,看完Flink的内容,基本了解了原理。 挖个坑,待总结后填一下。
2019-06-02 01:22:57等欧冠决赛中,填坑。
一、概述
storm最大的特点是快,它的实时性非常好(毫秒级延迟)。为了低延迟它牺牲了高吞吐,并且不能保证exactly once语义。
在低延迟和高吞吐的流处理中,维持良好的容错是非常困难的,但为了得到有保障的准确状态,人们想到一种替代方法:将连续时间中的流数据分割成一系列微小的批量作业(微批次处理)。如果分割得足够小,计算几乎可以实现真正的流处理。因为存在延迟,所以不可能做到完全实时,但是每个简单的应用程序都可以实现仅有几秒甚至几亚秒的延迟。这就是Spark Streaming所使用的方法。
为了实现高吞吐和exactly once语义,storm推出了storm trident,也是使用了微批次处理的方法。
微批次处理缺点:
-
数据只能按固定时间分割,没有办法根据实际数据情况,进行不同批次或每个批次不同大小的分割
-
满足不了对数据实时性要求非常高的数据
初识flink
flink与storm,spark streaming的比较
Apache flink主页在其顶部展示了该项目的理念:“Apache Flink是为分布式,高性能,随时可用以及准确的流处理应用程序打造的开源流处理框架”
流处理与批处理:
批处理的特点是有界、持久(数据已经落地)、大量,批处理非常适合需要访问全套记录才能完成的计算工作,一般用于离线统计。典型的是Hadoop,它只能用于批处理。
流处理的特点是无界、实时,流处理方式无需针对整个数据集执行操作,而是对通过系统传输的每个数据项执行操作,一般用于实时统计。典型的是storm,它只能进行流处理。
有没有即能实现批处理,也能实现流处理?
spark即能进行流处理,也能实现批处理,但它并不是在同一架构体系下,spark的批处理是通过spark core和spark sql实现,流处理是通过spark streaming实现。
flink什么特点呢?不管是批处理还是流处理,它能够同时进行处理,因为它底层是不区分流批的。flink将批处理(即处理有限的静态数据)视作一种特殊的流处理。
二、flink基本架构
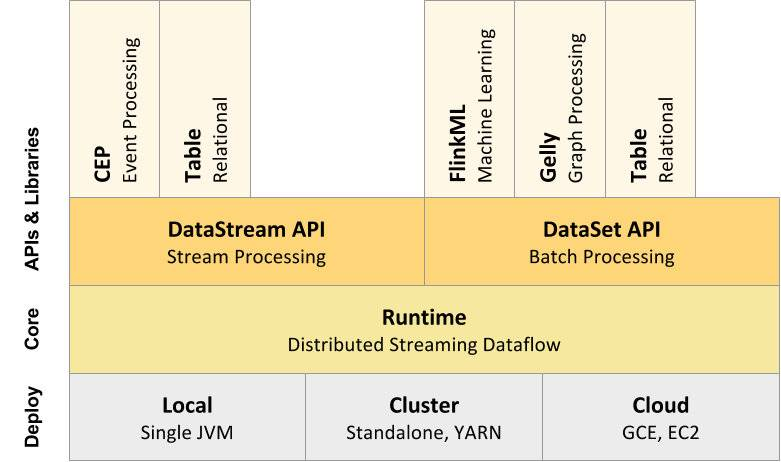
JobManager与TaskManager
如果粗化一点看的话,flink就是由2部分组成,即JobManager和TaskManager,是两个JVM进程。
JobManager:也称为master(对应spark里的driver),用于协调分布式执行,它们用来调度task,协调检查点,协调失败回复等。flink运行时至少存在一个master处理器,如果配置高可用模式则会存在多个master,它们其中一个是leader,而其它都是standby.
TaskManager:也称为worker(对应spark里面的executor),用于执行一个dataflow的task,数据缓冲和datastream的交换,flink运行时至少会存在一个worker处理器。
flink的编程模型

Stateful Stream Processing,是数据接入,计算,输出都是自己来实现,是最灵活也是最麻烦的编程接口。
DataStream/DataSet API是针对流和批处理的封装API,绝大多数的编程是在这一层。
Table API,是将数据抽像成一张表,提供select, group_by等API接口供调用。
SQL是最高级的接口,支持直接写SQL查询数据。
三、flink运行架构
任务提交流程
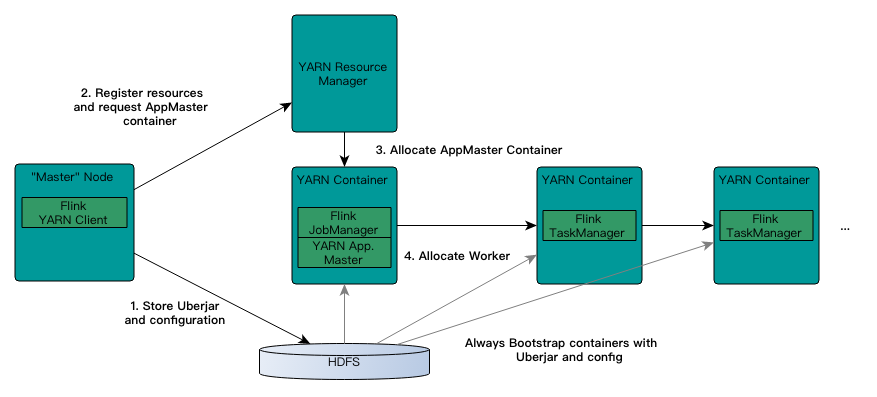
当启动新的Flink YARN会话时,客户端首先检查请求的资源(容器和内存)是否可用。之后,它将包含flink的jar和配置上传到HDFS(步骤1)。
客户端的下一步是请求(步骤2)YARN容器以启动ApplicationMaster(步骤3)。由于客户端将配置和jar文件注册为容器的资源,因此在该特定机器上运行的YARN的NodeManager将负责准备容器(例如,下载文件)。一旦完成,ApplicationMaster(AM)就会启动。
该JobManager和AM在同一容器中运行。成功启动后,AM就很容易知道JobManager的地址(它自己的主机)。它为TaskManagers生成一个新的Flink配置文件(以便它们可以连接到JobManager)。该文件也被上传到HDFS。此外,AM容器还提供Flink的Web界面。YARN代码分配的所有端口都是临时端口。这允许用户并行执行多个Flink YARN会话。
之后,AM开始为Flink的TaskManagers分配容器,它将从HDFS下载jar文件和修改后的配置。完成这些步骤后,Flink即会设置并准备接受作业。
这个提交Yarn Session的整个过程,Yarn Session提交完成后,JobManager和TaskManager就启动完毕,等待用户任务的提交(jar包)
任务调度原理

Task Slot只平均分配内存,不分CPU!Slot指的是TaskManager能够并行执行的task最大数。
客户端将程序抽像成Datafow Graph,并能过Actor System通信,将程序提交到JobManager,JobManager根据Dataflow Graph(类似Spark中的DAG),两个相临任务间的并行度变化,来划分任务,并将任务提交到TaskManager的Task Slot去执行。
TaskManager是一个独立的JVM进程,TaskManager和Slot可以看作worker pool模型,Slot是一个Worker,如果TaskManager里有Slot,才能被分配任务。
一个Slot里的Task,可能包含多个算子。Task按distributed进行划分,也就算子是否产生shuffle(spark里shuffle==flink的distributed).
如果有3个TaskManager,第个TaskManager中有3个Slot,那么最高支持的并行度是9,parallelism.default=9.
程序与数据流
flink程序的基础构架模块是流(streams)和转换(transformation)
fink通过source将流接进来,通过transformation算子对流进行转换,再通过sink将数据输出,这是一个flink程序的完整过程。

并行数据流
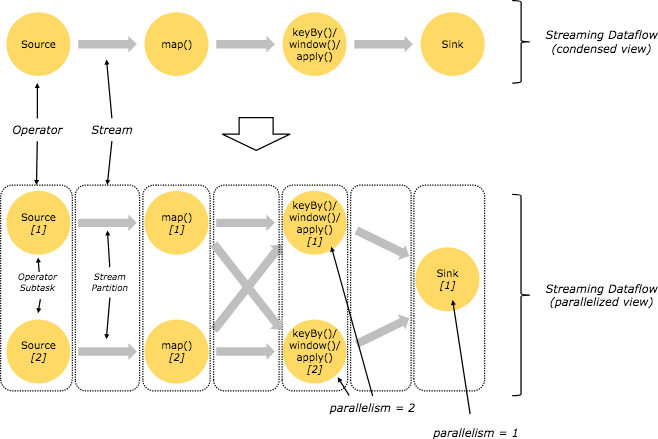
flink程序的执行具有并行、分布式的特性。在执行过程中,一个stream包含一个或多个stream partition,而每个operator包含一个或多个operator subtask,这些operator subtask在不同的线程、不同的物理机或不同的容器中彼此互不依赖的执行。
一个特定的operator的subtask的个数被称之为其parallelism(并行度)。一个程序中,不同的operator可能具有不同的并行度。
stream在operator之间的传输数据的形式可以是one-to-one(forwarding)的模式,也可以是redistributing的模式,具体哪种形式取决于operator的种类。
如上图map是one-to-one模式,而keyBy,window,apply是redistributing模式
one-to-one的算子,会被组合在一起成为operator-chain,一个operator-chain被分成一个task去执行。
四、DataStream API
flink程序结构
每个flink程序都包含以下的若干个流程:
-
获取一个执行环境:execution enviroment
-
加载/创建初始数据:source
-
指定转换这些数据:transformation
-
指定放置计算结果的位置:sink
-
触发程序执行
Transformation
-
Map操作
遍历一个集合的所有元素,并对每个元素做转换
输入一个参数,产生一个输出。
steam.map(item => item * 2)
-
FlatMap操作
输入一个参数,产生0个、1个或多个输出。
stream.flatMap(item => item.split(“ ”))
-
Filter操作
结算每个元素的布尔值,并返回布尔值为true的元素。
stream.filter(item => item == 1)
-
Connect操作
DataStream1, DataStream2 -> ConnectedStreams
在ConnectedStream的内部,stream还是分开的,也就是说,想对ConnectedStream执行一个Map/Filter等操作,要传入2个函数。第1个对DataStream1操作,第2个对DataStream2操作。
streamConnect = stream1.connect(stream2)
streamConnect.map(item => item * 2, item => (item, 1L))
-
coMap, coFlatMap操作
ConnectedStreams -> DataStream
stream = streamConnect.map(item => item * 2, item => (item, 1L))
输入是一个ConnectedStream,输出是一个普通的DataStream
-
Split + Select操作
DataStream -> SplitStream
val streamSplit = stream.split(word => (“haddoop”.equals(word)) match {
case true => List(“hadoop”)
case false => List(“other”)
}
)
上面split将流划分成2个流
val streamSelect001 = streamSplit.select(“hadoop”)
select 将指定的一个流取出来。
-
union操作
对两个或者两个以上的DataStream进行union操作,产生一个包含所有DataStream元素的新的DataStream。
-
KeyBy
DataStream -> KeyedStream,输入必须是Tuple类型,逻辑地将一个流拆分成不相交的分区,每个分区包含具有相同Key的元素,在内部以Hash的形式实现。
val env = StreamExecutionEnvironment.getExecutionEnvironment
var stream = env.readTextFile(“test.txt”)
val streamMap = stream.flaMap(item => item.split(“ “)).map(item => (item, 1L))
val streamKeyBy = streamMap.keyBy(0) //keyBy可以根据Tuple中的第一个元素,也可以根据第二个元素,进行partition。0代表第一个元素。
-
Reduce操作
KeyedStream -> DataStream:一个分组数据流的聚合操作,合并当前元素和上次聚合的结果,产生一个新的值,返回的流中包含每一次聚合的结果,而不是只返回最后一次聚合的最终结果。
val streamReduce = streamKeyBy.reduce(
(item1, item2) => (item1._1, item1._2 + item2._2)
)
-
Fold操作
KeyedStream -> DataStream:一个有初始值的分组数据流的滚动折叠操作。给窗口赋一个fold功能的函数,并返回一个fold后结果
-
Aggregation操作
五、Time与Window
时间

flink中有3个时间,
EventTime:事件生成的时间
IngestionTime:事件进入flink的时间
WindowProcessingTime:事件被处理的系统时间(默认使用)
窗口

不能直接对无界的流进行聚合,要先将流划分为window,再对window进行聚合。
window分为两类:
CountWindow:按照指定的数据条数,生成一个window,与时间无关
TimeWindow:按照时间生成window
对于TimeWindow,可以根据窗口实现原理的不同分成三类:
滚动窗口(Tumbing Window)—— 没有重叠
滑动窗口(Sliding Window)—— 重叠,有窗口长度和滑动步长两个属性
会话窗口(Sessionn Window)—— 如果相临的两条数据,间隔时间超过会话窗口时间大小,则前面的数据生成一个窗口。
每满足滑动步长,会针对window执行一次计算
val streanWindow = streamKeyBy.timeWindow(Time.Seconds(10), Time.Seconds(2)).reduce(
(item1, item2) => (item1._1, item1._2 + item2._2)
)
六、EventTime和Window
引入EventTime
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
WaterMark
如果用EventTime来决定窗口的运行,一旦出现乱序,我们不能明确数据是否已经全部到位,但又不能无限期的等下去,此时必须有个机制来保证一个特定的时间后,必须触发window的计了,这个特别的机制就是watermark.
WaterMark是一种衡量EventTime进展的机制,它是数据本身的一个隐藏属性,数据本身携带着对应的WaterMark。
WaterMark是用于处理乱序事件的,而正确的处理乱序事件,通常用WaterMark机制结合window来实现。
数据流中的WaterMark用于表示eventTime小于watermark的数据,都已经到达了,因此,window的执行也是由WaterMark触发的。
WaterMark可以理解成一个延迟触发机制,我们可以设置WaterMark的延时时长为t,每次系统会校验已经到达的数据中最大的maxEventTime,然后认定eventTime小于maxEventTime-t的所有数据都已经到达,如果有窗口的停止时间等于maxEventTime-t,那么这个窗口被触发。
当Flink接收到每一条数据时,都会计算产生一条watermark,watermark = 当前所有到达数据中的maxEventTime - 延迟时长,也就是说,watermark是由数据携带的,一量数据携带的watermark比当前未触发的窗口的停止时间要晚,那么就会触发相应的窗口的执行。由于watermark是由数据携带的,因此,如果运行过程中无法获取新的数据,那么没有被触发的窗口将永远不被触发。
EventTime的窗口与Time里的窗口区别:
窗口大小设置为5s,Time窗口每5秒执行一次,不管有没有数据。
EventTime每5s生成一个窗口,但不执行。当触发条件满足后,才会执行窗口。
附录
https://ci.apache.org/projects/flink/flink-docs-release-1.8/concepts/programming-model.html