Spark SQL
- Spark SQL里面最重要的就是DataFrame结构,与Spark的RDD结构相比,差别就在于是否已知元素里面的内容结构,举个栗子,RDD比作"{name:'lihua',age:18}",而DataFrame就是{name:'lihua',age:18}。
- 在对DataFrame操作上没有讲很多的内容,毕竟可以利用createOrReplaceTempView语句在创建临时表并且使用sql语句进行操作,所以学会简单的操作就可以了
- Spark SQL是Spark对于Shark(Hive的Spark版)的两种改进方式之一,另外一种是Hive on Spark。目的是可以通过SQL语句使用不同的数据源,然后利用不同数据源的数据方便使用Spark进行数据分析挖掘(机器学习)。
1.为employee.json创建DataFrame,并写出Python语句完成下列操作:
将下列JSON格式数据复制到Linux系统中,并保存命名为employee.json。
{ "id":1 , "name":" Ella" , "age":36 }
{ "id":2, "name":"Bob","age":29 }
{ "id":3 , "name":"Jack","age":29 }
{ "id":4 , "name":"Jim","age":28 }
{ "id":4 , "name":"Jim","age":28 }
{ "id":5 , "name":"Damon" }
{ "id":5 , "name":"Damon" }
(1) 查询所有数据;
emp = spark.read.format('json').load('file:///home/hadoop/Desktop/SparkPractice/sparkSQL/dataset1/employee.json')
emp.show()

(2) 查询所有数据,并去除重复的数据;
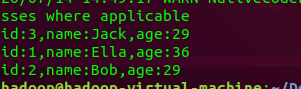
emp.groupBy('name','id','age').count().select('name','id','age').show()

(3) 查询所有数据,打印时去除id字段;
emp.select('name','age').show()

(4) 筛选出age>30的记录;
emp.filter(emp['age']>30).show()
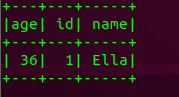
(5) 将数据按age分组;
emp.groupBy('age')
emp.groupBy('age').count().show()
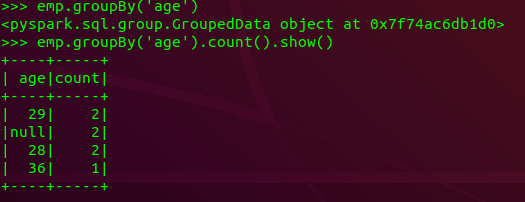
(6) 将数据按name升序排列;
emp.sort(emp['name'].asc()).show()
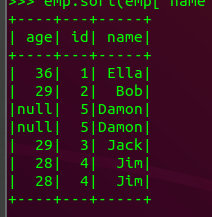
(7) 取出前3行数据;
emp.take(3)

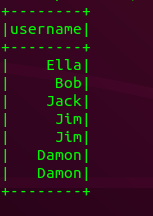
(8) 查询所有记录的name列,并为其取别名为username;
emp.select(emp['name'].alias('username')).show()
(9) 查询年龄age的平均值;
emp.agg({'age':'mean'}).show()

(10) 查询年龄age的最小值。
emp.agg({'age':'min'}).show()

2.编程实现将RDD转换为DataFrame
源文件内容如下(包含id,name,age):
1,Ella,36
2,Bob,29
3,Jack,29
请将数据复制保存到Linux系统中,命名为employee.txt,实现从RDD转换得到DataFrame,并按“id:1,name:Ella,age:36”的格式打印出DataFrame的所有数据。请写出程序代码。
from pyspark.sql.types import *
from pyspark.sql import SparkSession,Row
from pyspark import SparkConf,SparkContext
spark = SparkSession.builder.config(conf = SparkConf()).getOrCreate()
data = spark.sparkContext.textFile('file:///home/hadoop/Desktop/SparkPractice/sparkSQL/dataset2/employee.txt').map(lambda x:x.split(',')).map(lambda x:Row(int(x[0].strip()),x[1].strip(),int(x[2].strip())))
schema = StructType([StructField('id',IntegerType(),True),StructField('name',StringType(),True),StructField('age',IntegerType(),True)])
df = spark.createDataFrame(data,schema)
lateRdd = df.rdd.map(lambda x:'id:{},name:{},age:{}'.format(x.id,x.name,x.age))
lateRdd.foreach(print)
3. 编程实现利用DataFrame读写MySQL的数据
(1)在MySQL数据库中新建数据库sparktest,再创建表employee,包含如表5-2所示的两行数据。
表5-2 employee表原有数据
| id | name | gender | Age |
|---|---|---|---|
| 1 | Alice | F | 22 |
| 2 | John | M | 25 |
create database sparktest;
use sparktest;
create table employee (id int(4),name char(10),gender char(4),age int(4));
insert employee values(1,'Alice','F',22);
insert employee values(2,'John','M',25);
(2)配置Spark通过JDBC连接数据库MySQL,编程实现利用DataFrame插入如表5-3所示的两行数据到MySQL中,最后打印出age的最大值和age的总和。
表5-3 employee表新增数据
| id | name | gender | age |
|---|---|---|---|
| 3 | Mary | F | 26 |
| 4 | Tom | M | 23 |
from pyspark.sql.types import *
from pyspark.sql import SparkSession,Row
from pyspark import SparkConf,SparkContext
spark = SparkSession.builder.config(conf = SparkConf()).getOrCreate()
# 插入数据
schema = StructType([StructField('id',IntegerType(),True),
StructField('name',StringType(),True),
StructField('gender',StringType(),True),
StructField('age',IntegerType(),True)])
data = spark.sparkContext.parallelize(['3,Mary,F,26','4,Tom,M,23']).
map(lambda x:x.split(',')).
map(lambda x:Row(int(x[0]),x[1],x[2],int(x[3])))
df = spark.createDataFrame(data,schema)
prop = {'user':'root','password':'root','driver':'com.mysql.jdbc.Driver'}
df.write.jdbc('jdbc:mysql://localhost:3306/sparktest?useSSL=False','employee','append',prop)
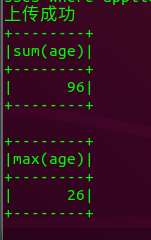
print('上传成功')
# 读入数据
newDf = spark.read.
format('jdbc').
option('driver','com.mysql.jdbc.Driver').
option('url','jdbc:mysql://localhost:3306/sparktest?useSSL=False').
option('dbtable','employee').
option('user','root').
option('password','root').
load()
newDf.agg({'age':'sum'}).show()
newDf.agg({'age':'max'}).show()