背景
周末闲来无事,想做一个财报分析软件,然后就想从同花顺获取数据,主要是想下载三大报表,下载地址是http://basic.10jqka.com.cn/api/stock/export.php?export=debt&type=year&code=600519,然后问题来了,这个访问是不需要登录的,在浏览器直接点击就能下载,但是使用HttpURLConnection来获取的时候就报401,经过分析是缺少cookie,然后去网站上copy了一个cookie,放上去可以获取数据了,然后过几分钟,cookie就失效了。
查找原因
把地址拿到postman中访问,返回了一段js,可以看到把地址又重新访问了一下,说明这段js对cookie做了修改
<html>
<body>
<script type="text/javascript" src="//s.thsi.cn/js/chameleon/chameleon.min.1621682.js"></script>
<script src="//s.thsi.cn/js/chameleon/chameleon.min.1621682.js" type="text/javascript"></script>
<script language="javascript" type="text/javascript">
window.location.href="//basic.10jqka.com.cn/api/stock/export.php?export=debt&type=year&code=000895";
</script>
</body>
</html>
然后我纳闷了,为什么浏览器里面可以直接下载呢?原因是我事先已经访问了该页面,cookie已经生成好了,于是把浏览器的缓存清空,再去下载,就没反应了,也就是说首次直接访问上面的地址其实是无法下载的,
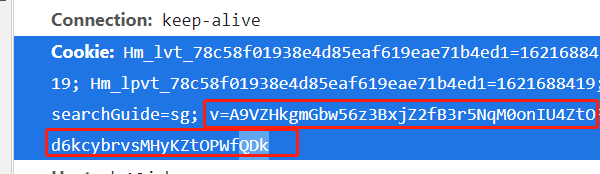
然后清空cookie,在chameleon.min.1621682.js这个js中的setCookie的几个地方打断点,可以发现每隔几秒setCookie就会执行一次,v对应的值就会改变,cookie如下,
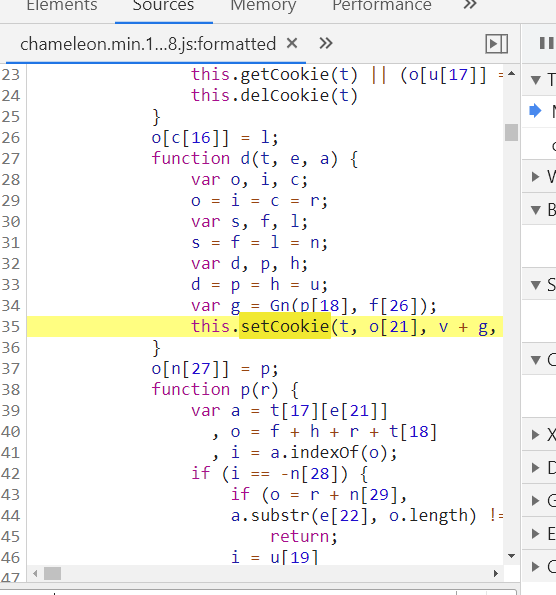
由于代码比较复杂,想去分析js是如何操作的不太现实。所以就想到了使用selenium之类的解决方法。最后无意间找到了htmlunit。
解决方案
由于上面的原因,想要仅仅通过HttpURLConnection来实现是不可能的了,最终发现htmlunit可以执行js,并且能实现跳转,正好满足要求,使用方式如下:
1、引入maven
<dependency>
<groupId>net.sourceforge.htmlunit</groupId>
<artifactId>htmlunit</artifactId>
<version>2.50.0</version>
</dependency>
2、编写代码
private InputStream downloadSheet(String urlStr) {
try {
WebClient webclient = new WebClient(BrowserVersion.CHROME); // 设置浏览器版本
webclient.getOptions().setTimeout(10 * 1000);//设置超时时间
webclient.getOptions().setRedirectEnabled(true);//启用跳转
webclient.getOptions().setThrowExceptionOnFailingStatusCode(false);
webclient.getOptions().setUseInsecureSSL(true);
webclient.getOptions().setJavaScriptEnabled(true); // 启用javascript
webclient.getOptions().setThrowExceptionOnScriptError(false); // 关闭js的异常抛出
webclient.getOptions().setCssEnabled(false); // 不加载CSS文件
webclient.getCookieManager().setCookiesEnabled(true);
webclient.setJavaScriptTimeout(600 * 1000);
webclient.waitForBackgroundJavaScript(60 * 1000);
webclient.setAjaxController(new NicelyResynchronizingAjaxController());
webclient.setRefreshHandler(new ImmediateRefreshHandler());
Page page = webclient.getPage(urlStr);
InputStream is = page.getWebResponse().getContentAsStream();
return is;
}catch (Exception e){
}
return null;
}
由于第一次使用,对这个框架不熟,由于没有setThrowExceptionOnFailingStatusCode,最开始也是报401,最终一路摸索,终于可以拿到流了,由于是下载excel,只需要拿到流丢给easyExcel读取就行了,到这里就结束了。