为什么要学这门课?应用场景有哪些?
1、上班族与自媒体人:采集各类数据用于工作/运营实战;
3、电商老板:采集竞品数据,帮助分析决策;
3、找个副业:学会数据采集技能,网上接单赚钱。
常见数据采集方式
(1)人工采集:费时费力,出错率高,工作效率非常低下。
(2)写爬虫采集:门槛略高,需会写编程,写完爬虫再调试,门槛高耗时长。
一小时教你学会数据采集,无需编程知识,轻松采集所需数据,提高工作效率,解放生产力,多个副业多赚钱。
讲师介绍
微博ID:@码代码的三哥
10+年互联网从业经验,科技公司技术副总监,精通数据处理、软件开发。
它能采集什么样的数据?
只要是电脑浏览器能打开的网站,它都可以采集。
它不能采集什么样数据?
只有手机App没有网站,这样的数据不能采集。
学习本课所需工具
1、安装谷歌浏览器
首先下载谷歌浏览器并安装,https://www.google.cn/chrome/
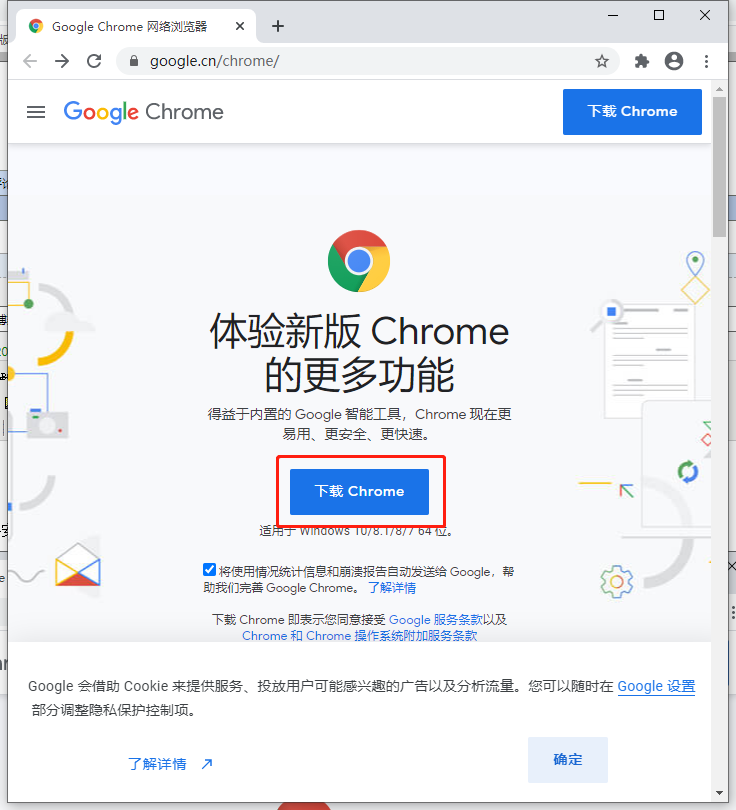
2、下载、安装爬虫插件
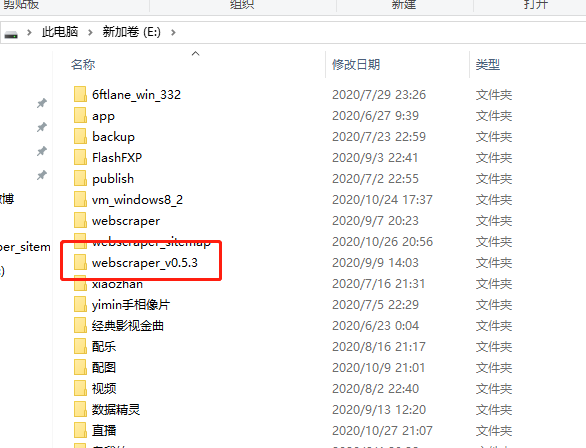
1)下载插件: https://pan.baidu.com/s/15StxxtZOihb2zlsDnIS2Vw 提取码:86tn
2)把下载的压缩包,复制到E盘根目录,解压,解压后名称为 webscraper_v0.5.3,如下图:
3)下载并安装谷歌插件,如下视频
https://www.bilibili.com/video/BV1W54y1r7nt/
课程内容
数据采集的思路(从大到小,从整体到局部)
https://www.bilibili.com/video/BV1rT4y1F7cQ/
1、手把手教你采集微博数据(帖子内容、转、评、赞 次数)
1)新建一个爬虫;
https://www.bilibili.com/video/BV1Vv411r7j1/
2)设置帖子数据框;
https://www.bilibili.com/video/BV1kA411j7CG/
3)设置发帖时间;
https://www.bilibili.com/video/BV1Py4y1z7Co/
4)设置帖子内容;
https://www.bilibili.com/video/BV1Ra411A7Fu/
5)设置 转评赞数据框;
https://www.bilibili.com/video/BV1FZ4y157vy/
6)设置 转评赞数据;
https://www.bilibili.com/video/BV1Ua4y1s743/
7)采集并核对数据;
https://www.bilibili.com/video/BV1iV41127yD/
8)如何让帖子按时间排序,采集隐藏的完整发帖时间;
https://www.bilibili.com/video/BV1Br4y1w72x/
9)如何采集多个页面的帖子数据
https://www.bilibili.com/video/BV1Ra411c7jL/
2、数据采集思路详解(采集数据就是找规律)
1)分析规律,先整体后局部,整体--》整个数据框,局部 —》某一个数据项
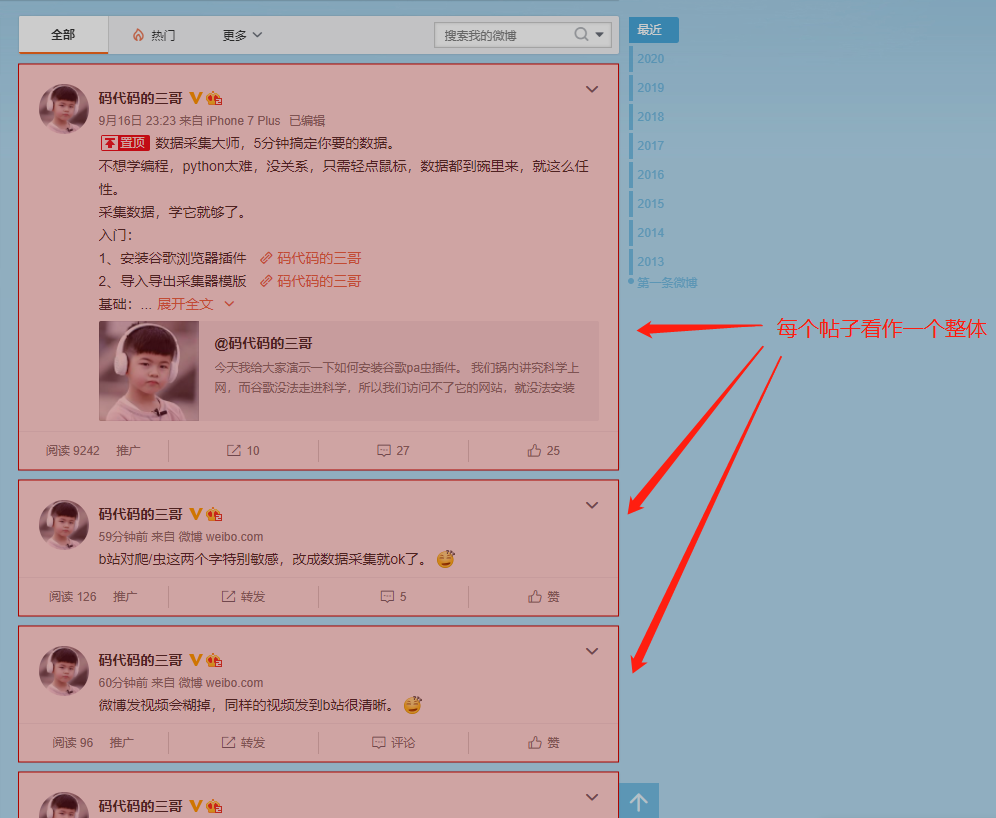
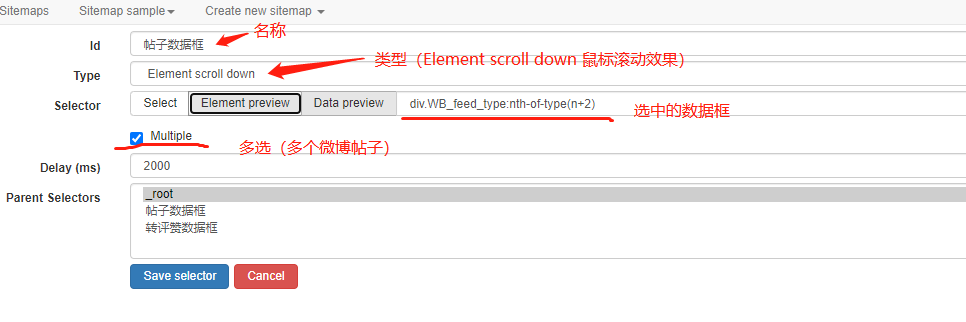
2)数据框类型介绍,常用的3种类型:
普通类型 Element
鼠标滚动类型 Element scroll down
鼠标点击类型 Element click
本节课用到了 Element 和 Element scroll down。
怎么选择类型,根据是否有特效来决定,无特效选Element,鼠标滚动选 Element scroll down,需要点击鼠标选Element click ,后面课程会对每一种类型做讲解和演示。
3)数据项类型介绍:
text 普通文本
image 图片
link 连接
Element attribute 某个元素的属性(高级用法)
本课程用到了text和Element attribute。
怎么选择数据类型,普通文本选text,图片选image,链接选link,Element attribute需要一点网页知识。
------------------
text 类型的使用
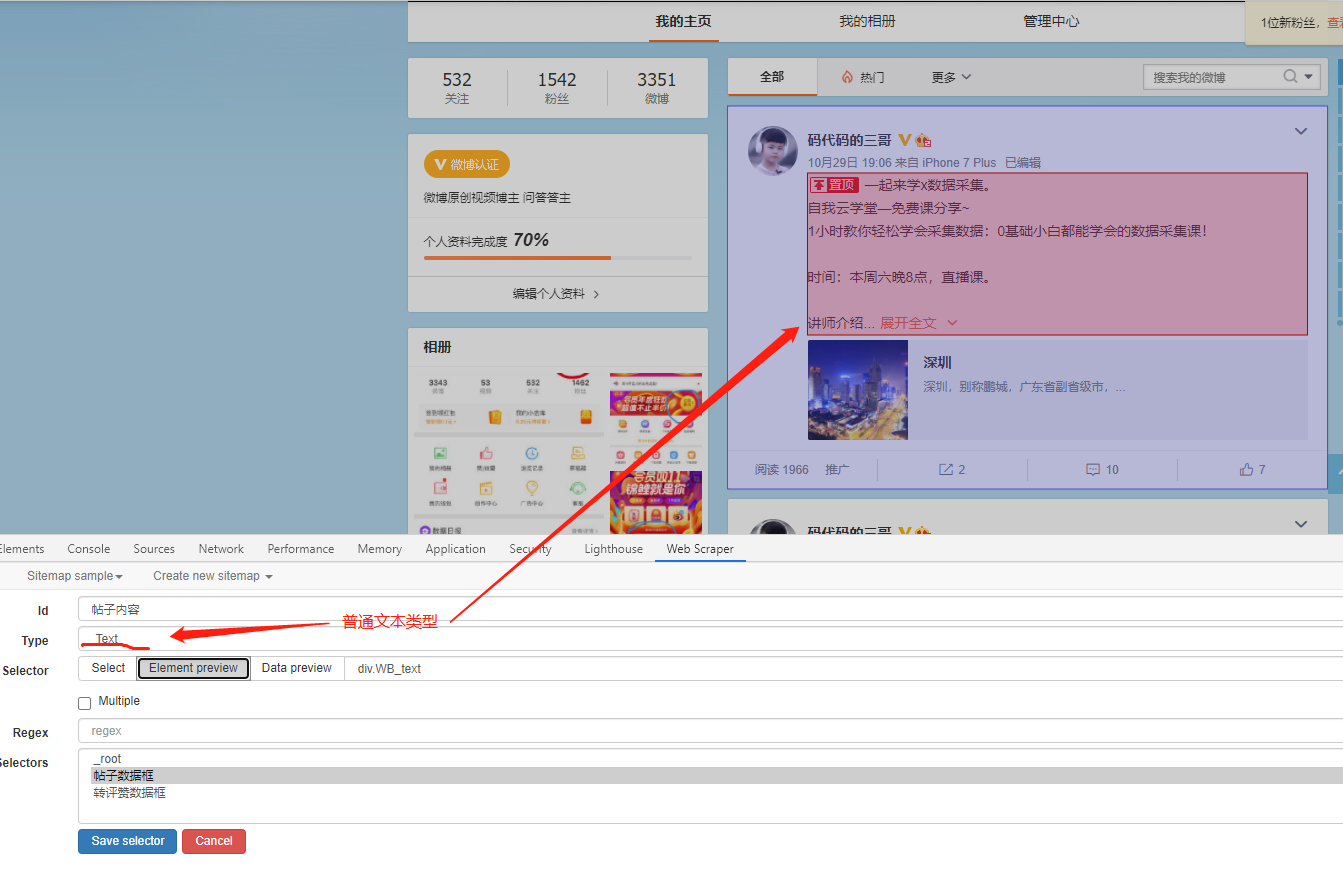
------------------
Element attribute 类型的使用

4)如何采集多页数据:用3个页面的url来分析分页的规律;
研究采集网址的规律,找出分页参数,然后设置参数,比如采集1到10页,设置为[1-10]。
第一页:https://weibo.com/2644160831/profile?topnav=1&wvr=6&is_all=1
第二页:https://weibo.com/2644160831/profile?is_search=0&visible=0&is_all=1&is_tag=0&profile_ftype=1&page=2#feedtop
第三页:https://weibo.com/2644160831/profile?is_search=0&visible=0&is_all=1&is_tag=0&profile_ftype=1&page=3#feedtop
第四页:https://weibo.com/2644160831/profile?is_search=0&visible=0&is_all=1&is_tag=0&profile_ftype=1&page=4#feedtop
总结规律得出 page=x 是页面参数
所以采集1到10页面我们设置url为
https://weibo.com/2644160831/profile?is_search=0&visible=0&is_all=1&is_tag=0&profile_ftype=1&page=[1-10]#feedtop
最后是互动问答时间