线性回归预测的是一个连续值,逻辑回归给出的“是”和“否”的答案一个二元分类的问题。
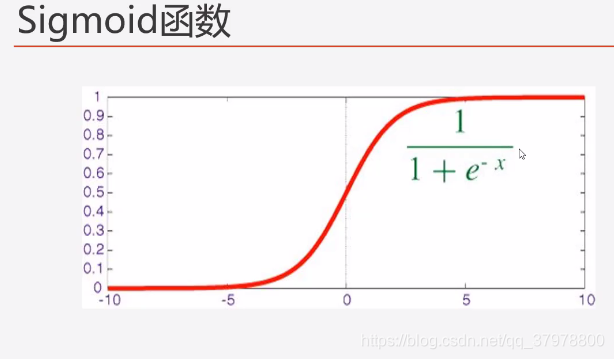
sigmoid函数是一个概率分布函数,给定某个输入,它将输出为一个概率值。
逻辑回归损失函数

交叉熵损失函数




# -*- coding: utf-8 -*-
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # 修改警告级别,不显示警告
import tensorflow as tf
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
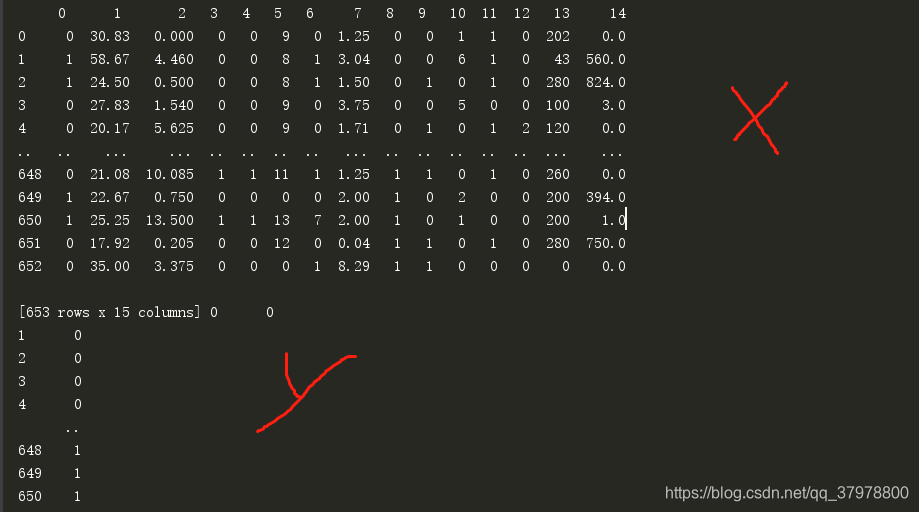
data = pd.read_csv("credit-a.csv",header=None)
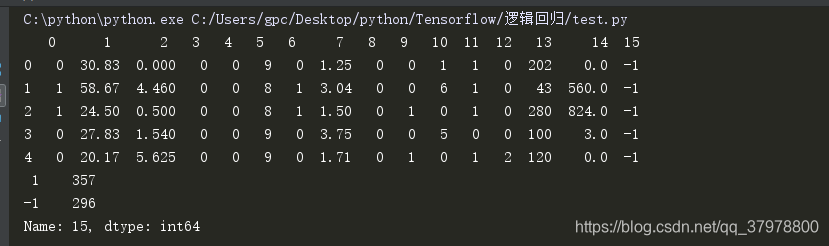
print(data.head())
print(data.iloc[:,-1].value_counts())# 查看最后一列使用value_counts()方法查看该目标是一个二分类数据
# -*- coding: utf-8 -*-
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # 修改警告级别,不显示警告
import tensorflow as tf
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
data = pd.read_csv("credit-a.csv",header=None)
print(data.head())
print(data.iloc[:,-1].value_counts())# 查看最后一列使用value_counts()方法查看该目标是一个二分类数据
x = data.iloc[:,:-1] # 特征值
y = data.iloc[:,-1].replace(-1,0) #目标值 (我们把-1替换成0 )
print(x,y)
# -*- coding: utf-8 -*-
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # 修改警告级别,不显示警告
import tensorflow as tf
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
data = pd.read_csv("credit-a.csv",header=None)
#print(data.head())
print(data.iloc[:,-1].value_counts())# 查看最后一列使用value_counts()方法查看该目标是一个二分类数据
x = data.iloc[:,:-1] # 特征值
y = data.iloc[:,-1].replace(-1,0) #目标值 (我们把-1替换成0 )
# print(x,y)
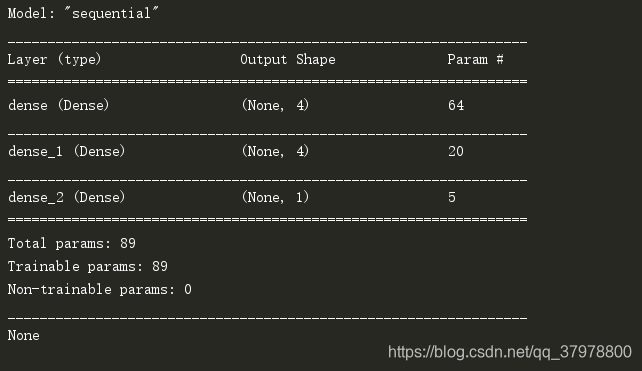
# 简历模型(顺序模型)
module = tf.keras.Sequential()
# 添加输入层 (二层)(4个隐藏单元,形状15列,使用relu激活)
module.add(tf.keras.layers.Dense(4,input_shape=(15,),activation="relu")) #一层
module.add(tf.keras.layers.Dense(4,activation="relu")) # 二层
# 添加输出层
module.add(tf.keras.layers.Dense(1,activation="sigmoid"))
print(module.summary())
# -*- coding: utf-8 -*-
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # 修改警告级别,不显示警告
import tensorflow as tf
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
data = pd.read_csv("credit-a.csv",header=None)
#print(data.head())
print(data.iloc[:,-1].value_counts())# 查看最后一列使用value_counts()方法查看该目标是一个二分类数据
x = data.iloc[:,:-1] # 特征值
y = data.iloc[:,-1].replace(-1,0) #目标值 (我们把-1替换成0 )
# print(x,y)
# 简历模型(顺序模型)
module = tf.keras.Sequential()
# 添加输入层 (二层)(4个隐藏单元,形状15列,使用relu激活)
module.add(tf.keras.layers.Dense(4,input_shape=(15,),activation="relu")) #一层
module.add(tf.keras.layers.Dense(4,activation="relu")) # 二层
# 添加输出层
module.add(tf.keras.layers.Dense(1,activation="sigmoid"))
#print(module.summary())
module.compile(optimizer="adam",loss="binary_crossentropy",metrics=["acc"])
# 训练模型
history = module.fit(x,y,epochs=100)
#History对象已经记录了运行输出,回调函数记录损失和准确率等
print(history.history.keys())
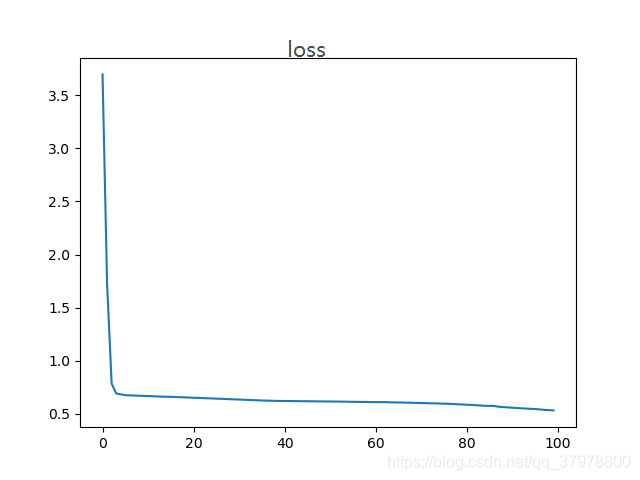
plt.plot(history.epoch,history.history.get("loss"))# 对损失值进行绘图
plt.show()
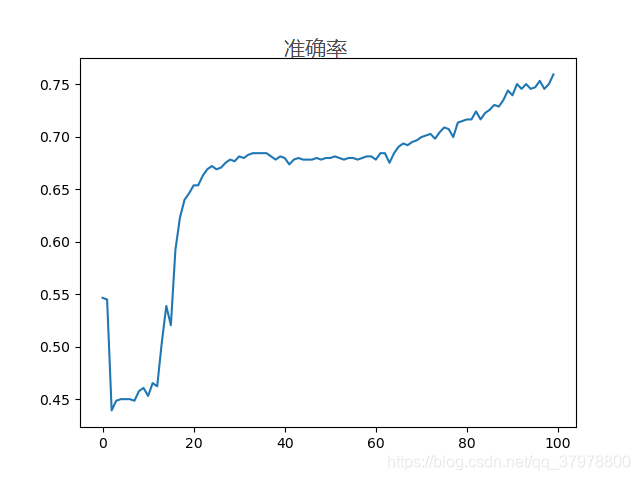
plt.plot(history.epoch,history.history.get("acc"))# 对准确率进行绘图
plt.show()