c
rapyd是 scrapy 的部署, 是官方提供的一个爬虫管理工具,
通过他可以非常方便的上传控制爬虫的运行,
安装 : pip install scapyd
他提供了一个json ,web, server
在命令行中输入scrapyd 回车,
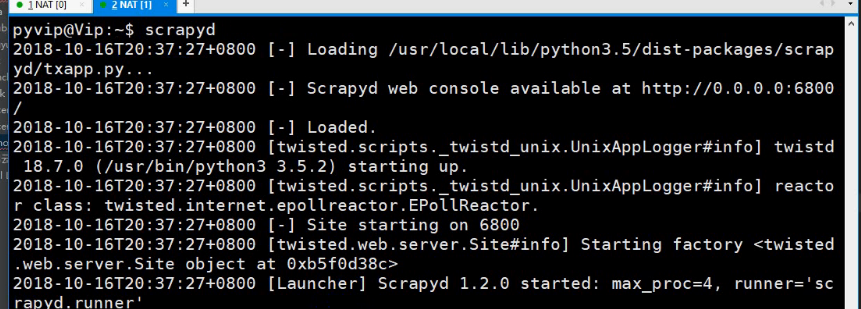
给个本地请求: curl http://localhost:6800
如果 是无界面的 linux ,可以通过端口转发
python安装库的路径


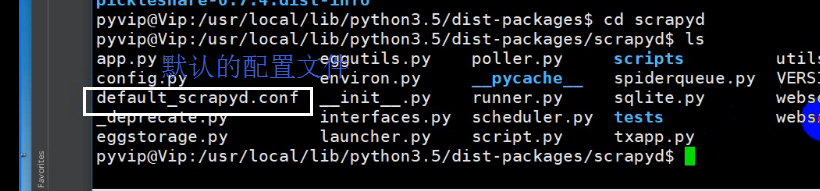
vim进到该文件中 默认为127.0.0.1

这样就可以访问了,


还要安装个客户端, pin install scrapy client
在这个文件中配置服务信息

需要配置的就这两个,一个是服务器 ip, 一个是项目名,

列出可用的服务器


部署项目: scrapyd-deploy <target0> -p <project>--version<version>

用最装箱单的方法写推送:scrapyd-deploy -p 项目名

调用爬虫: curl http://localhost:6800/schedule.json -d project xxx -d spider=xx
xxx 是项目名,
xx 是爬虫的名字,在项目里的 spider 目录下的 xx.py 文件的名字

取消爬虫: curl http://localhost:6800/cancer.json -d project xxx -d job=0000000
其中0000000表示这个爬虫的 jobid

列出所有的 job: curl http://localhost:6800/listjobs.json?project=xxx
其中 xxx 项目名
列出爬虫: curl http://localhost:6800/listjobs.json?spider=xxx
删除项目: curl http://localhost:6800/delproject.json -d projec=xxxx -d version=
查scrapy 进程id

