xgboost算法最近真是越来越火,趁着这个浪头,我们在最近一次的精准营销活动中,也使用了xgboost算法对某产品签约行为进行预测和营销,取得了不错的效果。说到xgboost,不得不说它的两大优势,一是准确率高,这次营销模型的AUC达到了94%;二是训练速度快,在几十万样本集,几十个特征的情况下,1分钟就可以训练完毕。到底是什么原因使得这门武功又快又准?下面就来简单分析一下。
Xgboost的全称是Extreme Gradient Boosting,它是由华盛顿大学的陈天奇于2014年所创,由于它的高精度和高效率,在近几年的算法比赛中被广泛应用并取得了很好的成绩,大放异彩。xgboost可以看作在决策树和GBDT的基础上进化而来的,这个过程简略表示如下:

1、决策树(Decision Tree)
决策树的优点是解释性强、简单、速度快,缺点是模型不稳定、对特征纯度依赖高,是最简单的模型。
2、GBDT(Gradient Boosting Decision Tree)
因为单个决策树的表达能力、范化能力和精度有限,所以GBDT引入了复合树和增量学习的概念。与随机森林相似,GBDT也是由多个CART树组合形成一个最终分类器。在GBDT生成树的时候,每棵树沿着前一棵树误差减小的梯度方向进行训练。举例来说,一个手机的价格100元,用GBDT进行建模,第一棵树拟合结果是90元,第二棵树是8元,第三棵树是2元,每一棵新生成的树都使得模型的偏差越来越小,三棵树级联起来形成最终的模型。xgboost的g也体现在这个地方。
举个原论文中的栗子,判断一个人是否使用电脑?
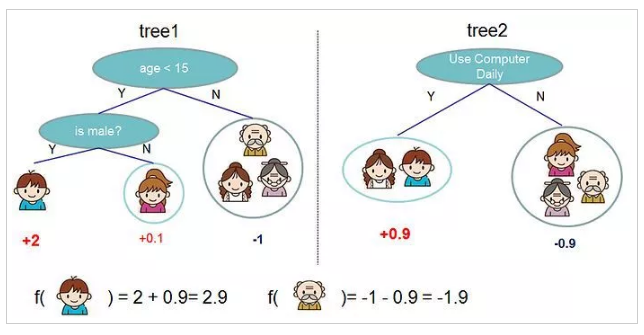
如图很好地解释了复合树和增量学习的概念,通过这两点,GBDT的范化能力和精度比决策树有了大幅提高。
3、Xgboost
Xgboost在GBDT的基础上又进行了大幅改进,算法的综合性能有飞跃式的提高,与GBDT相比,Xgboost的优点主要体现精度高、速度快、可扩展性高、防止过拟合这几点,下面逐条分析。
(1)精度高
Xgboost的损失函数用到了二阶导数信息,而GBDT只用到一阶;
在大多数情况,数据集都无法避免出现null值的情况,从而导致梯度稀疏,在这种情况下,xgboost为损失函数指定了默认的梯度方向,间接提升了模型精度和速度。
(2)速度快
Xgboost在生成树的最佳分割点时,放弃了贪心算法,而是采用了一种从若干备选点中选择出最优分割点的近似算法,而且可以多线程搜索最佳分割点。Xgboost还以块为单位优化了特征在内存中的存取,解决了Cache-miss问题,间接提高了训练效率。根据论文所说,通过这些方法优化之后,xgboost的训练速度比scikit-learn快40倍。
(3)可扩展性高
GBDT的基分类器是CART,而xgboost的基分类器支持CART,Linear,LR;
Xgboost的目标函数支持linear、logistic、softmax等,可以处理回归、二分类,多分类问题。另外,Xgboost还可以自定义损失函数。
(4)防止过拟合
xgboost在损失函数里加入了正则项,降低模型的方差,使模型更简单,防止过拟合,还能自动处理one-hot特征,但是one-hot会增加内存消耗,增加训练时间,陈天奇建议one-hot类别数量在[0, 100]范围内使用;
xgboost在每一轮迭代时为每棵树增加一个权重,以此来缩减个别树的影响力;
xgboost还支持特征的下采样,类似于随机森林,也可以防止过拟合,并且提高速度,不过这个功能在当前版本没有实现。
Xgboost的优缺点:
每门武功都有自己的优缺点,xgboost也不例外,这里我用随机森林作为对比,从正反两个角度来解释一下这两种算法的区别。xgboost适用于高偏差,低方差的训练集。而随机森林适用于高方差,低偏差的训练集,二者是决策树进化的两个方向。

Xgboost的思想是增量学习,通过树的级联不断修正偏差,方差较大的数据和异常值会对模型造成一定的影响。而随机森林的思想是bagging,树与树之间互相独立,通过多次有放回的采样,然后所有树共同投票,以此降低模型的方差,二者有所区别。从正面来说,对于偏差大的训练集,随机森林必须训练到20层树的深度才能达到的准确率,xgboost只需几层树就能达到,因为随机森林依赖的树的深度降低偏差,xgboost通过几个树的级联就把偏差轻松修正了。从反面来说,对于方差大的训练集,随机森林可以轻松拟合,xgboost就不容易拟合好,同理不再赘述。