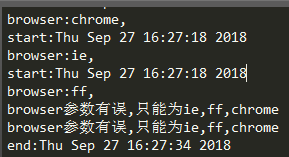
利用参数化连续打开网页:
#encoding=utf-8
import unittest
import paramunittest
import time
from selenium import webdriver
@paramunittest.parametrized(
{"url":"http://www.baidu.com","result": "百度"},
{"url":"http://www.sina.com","result": "新浪"},
{"url":"http://www.taobao.com","result": "淘宝"},
)
class TestDemo(unittest.TestCase):
def setParameters(self, url, result):
self.url = url
self.result = result
def test_login(self):
self.driver=webdriver.Firefox()
self.driver.get(self.url)
print("开始执行用例:--------------")
time.sleep(0.5)
print("期望结果:%s " % self.result)
if __name__ == "__main__":
unittest.main(verbosity=2)
为了看结果特意没关浏览器:
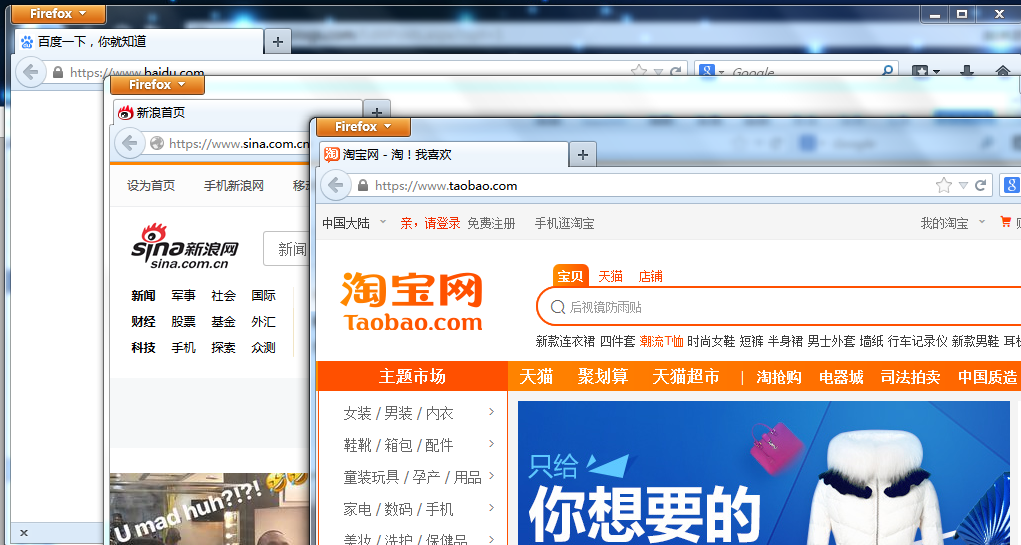

一些新的想法,由于每次都需要等一个参数运行完之后才能运行下一个,导致如果一个网站比如新浪,访问时间很长,则下面的淘宝就需要等待,很浪费时间,于是做了个多线程:
#encoding=utf-8
import unittest
import paramunittest
import time
from selenium import webdriver
@paramunittest.parametrized(
{"url":"http://www.baidu.com","result": "百度"},
{"url":"http://www.sina.com","result": "新浪"},
{"url":"http://www.taobao.com","result": "淘宝"},
)
class TestDemo(unittest.TestCase):
def setParameters(self, url, result):
self.url = url
self.result = result
def test_login(self):
self.driver=webdriver.Firefox()
t = threading.Thread(target=self.driver.get, args=(self.url,))
t.start()
self.driver.get(self.url)
print("开始执行用例:--------------")
time.sleep(0.5)
print("期望结果:%s " % self.result)
if __name__ == "__main__":
unittest.main(verbosity=2)
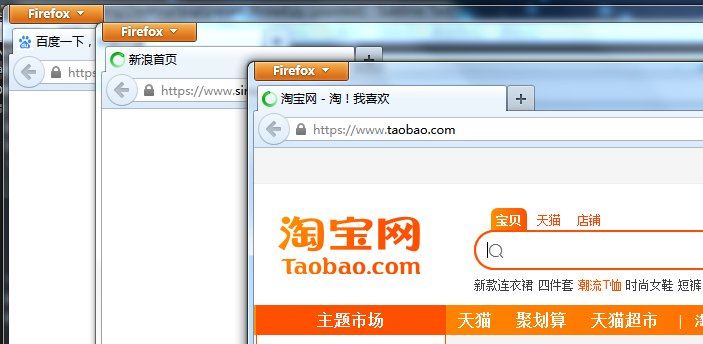
运行结果变成了6.729,比之前的92.458真的是。。。快了不少啊
补充内容:
上面写的内容确实能提高脚本运行速度,但是因为脚本比较简单,只有登录这步操作,如果是比较复杂的步骤单单一步多线程反而会使得之后的动作fail,下面是学习到的是可以完整执行多个操作的用例,并使得多个这种用例进行并发操作,但是这种方式还无法融合unittest和paramunittest,回报类的错误,当然可以利用HTMLTestRunner来将用例放在多个,py文件然后多线程批量运行
#encoding=utf-8
from threading import Thread
from selenium import webdriver
from time import ctime, sleep
def test_baidu(browser, search):
print('start:%s' % ctime())
print('browser:%s,' % browser)
if browser == "ie":
driver = webdriver.Firefox()#Ie()
elif browser == "chrome":
driver = webdriver.Firefox()#Chrome()
elif browser == "ff":
driver = webdriver.Firefox()
else:
print("browser参数有误,只能为ie,ff,chrome")
driver.get('http://www.baidu.com')
driver.find_element_by_id("kw").send_keys(search)
driver.find_element_by_id("su").click()
sleep(2)
#driver.quit()
if __name__ == '__main__':
lists = {'ie': 'threading', 'chrome': 'driver', 'ff': 'python'}
threads = []
files = range(len(lists))
for brow, sea in lists.items():
t = Thread(target=test_baidu, args=(brow, sea))
threads.append(t)
for t in files:
threads[t].start()
for t in files:
threads[t].join()
print('end:%s' % ctime())
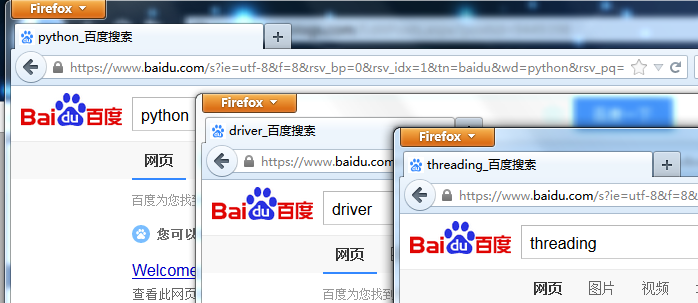
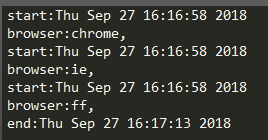
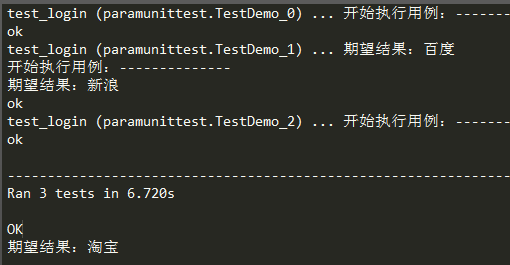
有一点需要注意,就是判断时一定要用elif,否则由于多线程过快,导致会直接跳到else将其内容print出来如下: