前引:
01、什么是数据?
x=10,10是我们要存储的数据
02、为何数据要分不同的类型
数据是用来表示状态的,不同的状态就应该用不同的类型的数据去表示
03、数据类型:
数字 int 布尔bool 字符串str 列表list 元组tuple 字典dict 集合set
一:数字(int):
分类:整型,长整型,浮点,复数
数字主要是用于计算用的,使用方法并不是很多,就记住一种就可以:
#bit_length() ---> 当十进制用二进制表示时,最少要使用的位数
#是数字的一种内置方法
i = 4 data = i.bit_length() print(data)
结果为:3
##以下为手动转换为了上面解释方便于理解:
十进制 二进制
1 0000 0001
2 0000 0010
3 0000 0011
4 0000 0100
所以结果为3
1.1 整型:
Python的整型相当于C中的long型,Python中的整数可以用十进制,八进制,十六进制表示。
>>> 10 10 --------->默认十进制 >>> oct(10) '012' --------->八进制表示整数时,数值前面要加上一个前缀“0” >>> hex(10) '0xa' --------->十六进制表示整数时,数字前面要加上前缀0X或0x
python2.*与python3.*关于整型的区别
python2.*
在32位机器上,整数的位数为32位,取值范围为-2**31~2**31-1,即-2147483648~2147483647
在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807
python3.*整形长度无限制
整型工厂函数int()
1.2 长整型long:
python2.*:
跟C语言不同,Python的长整型没有指定位宽,也就是说Python没有限制长整型数值的大小,
但是实际上由于机器内存有限,所以我们使用的长整型数值不可能无限大。
在使用过程中,我们如何区分长整型和整型数值呢?
通常的做法是在数字尾部加上一个大写字母L或小写字母l以表示该整数是长整型的,例如:
a = 9223372036854775808L
注意,自从Python2起,如果发生溢出,Python会自动将整型数据转换为长整型,
所以如今在长整型数据后面不加字母L也不会导致严重后果了。
python3.*
长整型,整型统一归为整型
.1.3 浮点数float:
Python的浮点数就是数学中的小数,
在运算中,整数与浮点数运算的结果是浮点数
浮点数也就是小数,之所以称为浮点数,是因为按照科学记数法表示时,
一个浮点数的小数点位置是可变的,比如,1.23*109和12.3*108是相等的。
浮点数可以用数学写法,如1.23,3.14,-9.01,等等。但是对于很大或很小的浮点数,
就必须用科学计数法表示,把10用e替代,1.23*109就是1.23e9,或者12.3e8,0.000012
可以写成1.2e-5,等等。
整数和浮点数在计算机内部存储的方式是不同的,整数运算永远是精确的而浮点数运算则可能会有
四舍五入的误差。
.1.4 复数complex:
复数由实数部分和虚数部分组成,一般形式为x+yj,其中的x是复数的实数部分,y是复数的虚数部分,这里的x和y都是实数。
注意,虚数部分的字母j大小写都可以,
>>> 1.3 + 2.5j == 1.3 + 2.5J True
.1.5 数字相关内建函数
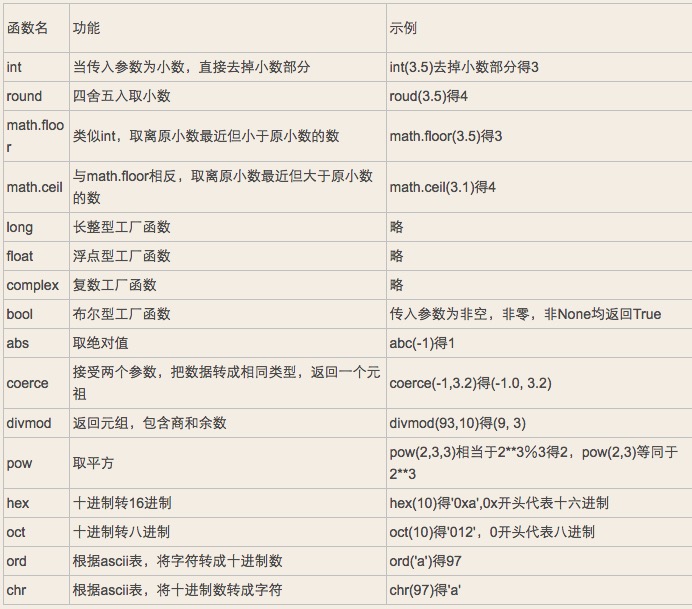
二:布尔值bool:
布尔值就只有两种:True,False。返回条件的正确与否。
真 → True → 1 
假 → False → 0 
2.1其他类型转换为bool
int → bool
i = 1 print (bool(i)) j = 0 print (bool(j)) s = -1 print (bool(s))
##ps:非0的数字转换为bool即为True
同理数字0转换为bool即为False
str →bool
#实例一:
s = ''
print (bool(s))
#结果为:False
#实例二:
s1 = ' '
print (bool(s1))
结果为:True
#实例三
s2 = 'abcdf'
print (bool(s2))
#结果为:True
ps:非空字符串(包括引号里有空格)结果为True,空则为False。
#使用场景:
s = ''
if not s:
print('666')
#结果为666
#为什么走666呢?下面我来解释一下。
字符串为空那么转为bool则为False
那么not既是相反。所以结果为True,就走666的条件。
三:字符串(str)
定义:它是一个有序的字符的集合,用于存储和表示基本的文本信息,‘ ’或“ ”或''' '''或“““ ”””中间包含的内容称之为字符串
特性:
1.只能存放一个值
2.不可变
3.按照从左到右的顺序定义字符集合,下标从0开始顺序访问,有序
4.字符串可相加相乘,但不可相减相除。
使用场景:用于存放少量的数据比如'旺财','文章....'
少量的数据的前后端交互,用户名,密码等等
补充:
1.字符串的单引号和双引号都无法取消特殊字符的含义,如果想让引号内所有字符均取消特殊意义,在引号前面加r,如name=r'l hf'
2.unicode字符串与r连用必需在r前面,如name=ur'l hf'
ps:普通的短的字符串也就是没有行规则的字符串用单引号或者双引号就可以,三引号的使用场景一般是比如诗词(有规则的),使用三引号引起来,打印出来的结果格式是不变的。

3.1 字符串创建
字符串相加:相加即字符串与字符串的拼接。

字符串相乘:相乘即连续打印字符串的次数。

3.2 字符串常用操作
索引
字符串是有下标的,下表默认是从0开始的依次0123....0代表第一个字符。
#取出以下字符串的第一个字符
s = '老男孩培训机构' s1 = s[0]
print (s1)
#结果为:老
#取出一下字符串的构
s = '老男孩培训机构'
s2 = s[-1]
print (s2)
#结果为:构
切片
ps:切片顾头不顾尾
#取出浪子字段
s = '浪子回头金不换' s1 = s[:2] print (s1) #结果为:浪子
#ps:冒号前面不写即为从字符串的第一个开始
#取出金不换字段
s = '浪子回头金不换'
s1 = s[4:]
print (s1)
#结果为:金不换
#ps:顾头不顾尾所以第5位开始,冒号后面没有下表号即为默认到最后。
#取出浪回金换字段
s = '浪子回头金不换'
s1 = s[0::2]
print (s1)
#结果为:浪回金换
#ps:s[起始索引:终止索引:步长]
#取出换不金,倒着取。
s = '浪子回头金不换'
s1 = s[-1:-4:-1]
print (s1)
#结果为:换不金
#ps:倒着取必须加上步长-1
#取出回子浪倒着取
s = '浪子回头金不换'
sl = s[2::-1]
print (s1)
#结果为:回子浪
#取出换金回倒着字段
s = '浪子回头金不换'
s1 = s[-1:1:-2]
print (s1)
#结果为:换回金
#ps:倒着取也要加上步长
#取出浪子金字段
s = '浪子回头金不换'
s1 = s[:2] + s [4]
print (s1)
#结果为:浪子金
移除空白
分割
长度
3.3 字符工厂函数str()
四:列表
定义:[]内以逗号分隔,按照索引,存放各种数据类型,每个位置代表一个元素
特性:
1.可存放多个值
2.可修改指定索引位置对应的值,可变
3.按照从左到右的顺序定义列表元素,下标从0开始顺序访问,有序
.4.1 列表创建
list_test=[’lhf‘,12,'ok']
或
list_test=list('abc')
或
list_test=list([’lhf‘,12,'ok'])
.4.2 列表常用操作
索引
切片
追加
删除
长度
切片
循环
包含
五:元组tuple
定义:与列表类似,只不过[]改成()
特性:
1.可存放多个值
2.只读列表且不可改变
3.按照从左到右的顺序定义元组元素,下标从0开始顺序访问,有序
.5.1 元组创建
ages = (11, 22, 33, 44, 55)
或
ages = tuple((11, 22, 33, 44, 55))
5.2 元组常用操作
索引
切片
循环
长度
包含
六:字典
定义:{key1:value1,key2:value2},key-value结构,key必须可hash
特性:
1.可存放多个值,关联性较强的数据
2.可修改指定key对应的值,可变
3.无序但查询速度快
.6.1 字典创建
person = {"name": "sb", 'age': 18}
或
person = dict(name='sb', age=18)
person = dict({"name": "sb", 'age': 18})
person = dict((['name','sb'],['age',18]))
{}.fromkeys(seq,100) #不指定100默认为None
注意:
>>> dic={}.fromkeys(['k1','k2'],[])
>>> dic
{'k1': [], 'k2': []}
>>> dic['k1'].append(1)
>>> dic
{'k1': [1], 'k2': [1]}
.6.2 字典常用操作
索引
新增
删除
键、值、键值对
循环
长度
七:集合
定义:由不同元素组成的集合,集合中是一组无序排列的可hash值,可以作为字典的key
特性:
1.集合的目的是将不同的值存放到一起,不同的集合间用来做关系运算,无需纠结于集合中单个值
.7.1 集合创建
{1,2,3,1}
或
定义可变集合set
>>> set_test=set('hello')
>>> set_test
{'l', 'o', 'e', 'h'}
改为不可变集合frozenset
>>> f_set_test=frozenset(set_test)
>>> f_set_test
frozenset({'l', 'e', 'h', 'o'})
.7.2 集合常用操作:关系运算
in
not in
==
!=
<,<=
>,>=
|,|=:合集
&.&=:交集
-,-=:差集
^,^=:对称差分
八: bytes类型
定义:存8bit整数,数据基于网络传输或内存变量存储到硬盘时需要转成bytes类型,字符串前置b代表为bytes类型
>>> x
'hello sb'
>>> x.encode('gb2312')
b'hello sb'
.8 数据类型转换内置函数汇总

注:真对acsii表unichr在python2.7中比chr的范围更大,python3.*中chr内置了unichar