Attention-over-Attention Neural Networks for Reading Comprehension
论文地址:https://arxiv.org/pdf/1607.04423.pdf
0 摘要
任务:完形填空是阅读理解是挖掘文档和问题关系的一个代表性问题。
模型:提出一个简单但是新颖的模型A-O-A模型,在文档级的注意力机制上增加一层注意力来确定最后答案
(什么是文档级注意力?就是每阅读问题中的一个词,该词对文档中的所有单词都会形成一个分布,从而形成文档级别的分布)
模型优点:(1)更简单,性能更好 (2)提出N-best重新排序策略去二次检验候选词的有效性(3)相比之前模型,实验结果性能更好
数据集:CNN&Daily Mail以及儿童故事(Children’s Book Test,CBT)数据集介绍
1 引言
(1)引出任务:
阅读和理解人类语言是机器的挑战性任务,他需要理解自然语言和推理线索的能力。其中,填充式阅读理解问题已成为社区的热门任务,填充式查询( cloze-style query)是一个问题,即在考虑上下文信息的同时,在给定的句子中填写适当的单词。这个单词答案是文档中的一个单词,它需利用文档和问题中的上下文信息推理得来。
形式上,一般的Cloze-style式阅读理解问题可以被解释为一个三元组:D,Q,A三元组:
- 文档D :Mary sits beside him … he loves Mary
- 查询Q:he loves __
- 查询答案A:Mary
(2)对机器进行填充式任务的阅读理解,需要大规模数据集,现有两个数据集:
1)CNN /每日邮报新闻数据集(2015年),文档D由新闻报道组成,查询Q由文章摘要构成,将文章摘要中的一个实体词被特殊的占位符替换以指示缺失的词。被替换的实体词将是查询的答案。
2)儿童图书测试数据集(2016),文档D由书籍的连续20个句子生成的,并且查询由第21句形成。
(3)基于上述数据集的相关工作:
在这个数据集上,提出了很多神经网络的方法,而且大多数都是基于注意力机制的神经网络,由于注意力机制在学习对于输入上的重要分布的能力,已经成为了大多数NLP任务的固定模式。
(4)本文思路:
本文提出一种新的神经网络,称为attention-over-attention注意模型。我们可以从字面上理解含义:我们的模型旨在将另一种注意机制置于现有文档级别的注意力机制之上。
与以前的作品不同,之前的模型通常使用启发式归并的思想或者设置许多预定义的不可训练的项,我们的模型可以自动在多个文档级别的“注意力”上生成一个集中注意力,所以,模型不仅可以从查询Q到文档D;还可以文档D到查询Q进行交互查看,这将受益于交互式信息。
(5)本文创新点:
综上所述,我们的工作主要贡献如下:
-
据我们所知,这是第一次提出将注意力覆盖在现有关注点上的机制之上,即attention-over-attention mechanism。
-
与以往有关向模型引入复杂体系结构或许多不可训练的超参数的工作不同,我们的模型要简单得多,但要大幅优于各种最先进的系统。
-
我们还提出了N-best排名策略,以重新评估候选词的各个方面并进一步提高表现。
接下来的文章结构:第2节简明介绍完形填空式阅读理解任务以及相关的数据集;第3节详细介绍所提出的attention-over-attention的阅读器;第4节将介绍N-BEST排名策略;第5节和第6节介绍实验结果和实验分析;最后在第7节中给出总结与展望。
2 完形填空式阅读理解
2.1 任务描述
<D, Q, A>,其中D代表文档(document),Q代表问题(query),A则代表问题的答案(Answer),答案是文档中某个词,答案词的类型为固定搭配中的介词或命名实体。作者:损失函数
链接:https://www.imooc.com/article/29985
来源:慕课网
本文原创发布于慕课网 ,转载请注明出处,谢谢合作
<D, Q, A>,其中D代表文档(document),Q代表问题(query),A则代表问题的答案(Answer),答案是文档中某个词,答案词的类型为固定搭配中的介词或命名实体。作者:损失函数
链接:https://www.imooc.com/article/29985
来源:慕课网
本文原创发布于慕课网 ,转载请注明出处,谢谢合作
一个完形填空式阅读理解样本可描述为一个三元组:<D, Q, A>,其中D代表文档(document),Q代表问题(query),A则代表问题的答案(Answer),答案是文档中某个词,答案词的类型为固定搭配中的介词或命名实体。
2.2 现有公共数据集
- CNN/DailyMail
<D, Q, A>,其中D代表文档(document),Q代表问题(query),A则代表问题的答案(Answer),答案是文档中某个词,答案词的类型为固定搭配中的介词或命名实体。作者:损失函数
链接:https://www.imooc.com/article/29985
来源:慕课网
本文原创发布于慕课网 ,转载请注明出处,谢谢合作
<D, Q, A>,其中D代表文档(document),Q代表问题(query),A则代表问题的答案(Answer),答案是文档中某个词,答案词的类型为固定搭配中的介词或命名实体。作者:损失函数
链接:https://www.imooc.com/article/29985
来源:慕课网
本文原创发布于慕课网 ,转载请注明出处,谢谢合作
<D, Q, A>,其中D代表文档(document),Q代表问题(query),A则代表问题的答案(Answer),答案是文档中某个词,答案词的类型为固定搭配中的介词或命名实体。作者:损失函数
链接:https://www.imooc.com/article/29985
来源:慕课网
本文原创发布于慕课网 ,转载请注明出处,谢谢合作
这是一个完形填空式的机器阅读理解数据集,从美国有线新闻网(CNN)和每日邮报网抽取近一百万篇文章,每篇文章作为一个文档(document),在文档的summary中剔除一个实体类单词,并作为问题(question),剔除的实体类单词即作为答案(answer),该文档中所有的实体类单词均可为候选答案(candidate answers)。其中每个样本使用命名实体识别方法将文本中所有的命名实体用类似“@entity1”替代,并随机打乱表示。
- Children‘s Book Test
一个完形填空式阅读理解样本可描述为一个三元组:<D, Q, A>,其中D代表文档(document),Q代表问题(query),A则代表问题的答案(Answer),答案是文档中某个词,答案词的类型为固定搭配中的介词或命名实体。
作者:损失函数
链接:https://www.imooc.com/article/29985
来源:慕课网
本文原创发布于慕课网 ,转载请注明出处,谢谢合作
由于没有摘要,所以从每一个儿童故事中提取20个连续的句子作为文档(document),第21个句子作为问题(question),并从中剔除一个实体类单词作为答案(answer)。在CBTest数据集中,有四种类型的子数据集可用,它们通过应答词的词性和命名实体标签分类,包含命名实体(NE),常用名词(CN),动词和介词。 在研究中,他们发现动词和介词的回答相对较少地依赖于文档的内容,并且人类甚至可以在没有文档存在的情况下进行介词填空。 回答动词和介词较少依赖于文档的存在。 因此,大多数相关工作都集中在解决NE问题上和CN类型。
3 本文模型Attention-over-Attention Reader
我们的模型基于“Text understanding with the attention sum reader network.”论文提出的模型,但是他主要计算文档级别的关注,而不是计算文档的混合程度。而我们这篇文章中提出了一个新的方法,在原来的注意力上新增加一层注意力,来描述每一个注意力的重要性。
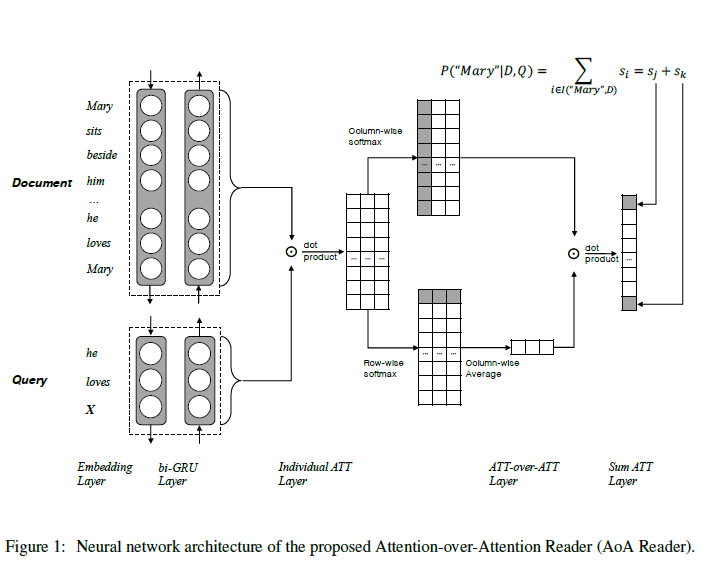
- Contextual Embedding
首先将文档D和问题Q转化为one-hot向量,然后将one-hot向量输入embedding层,然后用共享嵌入矩阵We将它们转换为连续表示。通过共享词嵌入,文档和问题都可以参与嵌入的学习,它们都将从这种机制中获益。然后,我们使用两个双向RNNS来获取文档的上下文表示形式并分别进行查询,其中每个单词的表示形式是通过连接向前和向后输出状态形成的。在权衡模型性能和训练复杂度之后,我们选择门控递归单元(GRU) 作为递归单元实现。也就是说,用 Bi-GRU 将 query 和 document 分别 encode,将两个方向的hidden state 拼接起来作为该词的 state,此时 document 和 query 可以分别用一个 Dxd 和 Qxd 的矩阵来表示,这里 D 是 document 的词数,Q 是 query 的词数,d 是embedding 的维度。
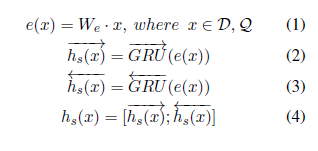
1 embedding = tf.get_variable('embedding', 2 [FLAGS.vocab_size, FLAGS.embedding_size], 3 initializer=tf.random_uniform_initializer(minval=-0.05, maxval=0.05)) 4 5 regularizer = tf.nn.l2_loss(embedding) 6 7 doc_emb = tf.nn.dropout(tf.nn.embedding_lookup(embedding, documents), FLAGS.dropout_keep_prob) 8 doc_emb.set_shape([None, None, FLAGS.embedding_size]) 9 10 query_emb = tf.nn.dropout(tf.nn.embedding_lookup(embedding, query), FLAGS.dropout_keep_prob) 11 query_emb.set_shape([None, None, FLAGS.embedding_size]) 12 13 with tf.variable_scope('document', initializer=orthogonal_initializer()): 14 fwd_cell = tf.contrib.rnn.GRUCell(FLAGS.hidden_size) 15 back_cell = tf.contrib.rnn.GRUCell(FLAGS.hidden_size) 16 17 doc_len = tf.reduce_sum(doc_mask, reduction_indices=1) 18 h, _ = tf.nn.bidirectional_dynamic_rnn( 19 fwd_cell, back_cell, doc_emb, sequence_length=tf.to_int64(doc_len), dtype=tf.float32) 20 #h_doc = tf.nn.dropout(tf.concat(2, h), FLAGS.dropout_keep_prob) 21 h_doc = tf.concat(h, 2) 22 23 with tf.variable_scope('query', initializer=orthogonal_initializer()): 24 fwd_cell = tf.contrib.rnn.GRUCell(FLAGS.hidden_size) 25 back_cell = tf.contrib.rnn.GRUCell(FLAGS.hidden_size) 26 27 query_len = tf.reduce_sum(query_mask, reduction_indices=1) 28 h, _ = tf.nn.bidirectional_dynamic_rnn( 29 fwd_cell, back_cell, query_emb, sequence_length=tf.to_int64(query_len), dtype=tf.float32) 30 #h_query = tf.nn.dropout(tf.concat(2, h), FLAGS.dropout_keep_prob) 31 h_query = tf.concat(h, 2)
文档的Contextual Embedding表示为h_doc,维度为|D| * 2d,问题的Contextual Embedding表示为h_query,维度为|Q| * 2d,d为GRU的节点数。
D和问题Q转化为one-hot向量,然后将one-hot向量输入embedding层,作者:损失函数
链接:https://www.imooc.com/article/29985
来源:慕课网
本文原创发布于慕课网 ,转载请注明出处,谢谢合作
- Pair-wise Matching Score
在获得文档h_doc和查询h_query 的contextual embeddings之后,我们计算成对匹配矩阵,其表示一个文档词和一个查询词的成对匹配程度。 也就是,当给出第i个单词和第j个单词时,我们可以通过它们的点积来计算匹配分数

1 M = tf.matmul(h_doc, h_query, adjoint_b=True) 2 M_mask = tf.to_float(tf.matmul(tf.expand_dims(doc_mask, -1), tf.expand_dims(query_mask, 1)))
通过这种方式,我们可以计算每个文档和查询词之间的每一对匹配分数,形成一个矩阵M∈R| D | * | Q | ,其中第i行第j列的值由M(i,j)填充。行数为文档D的长度,宽度为查询Q的长度。
这一步本质上就是对两个矩阵做矩阵乘法,得到所谓的Matching Score矩阵M,这里的M矩阵的维度是DxQ,矩阵中的每个元素表示对应 document 和 query 中的词之间的matching score。
- Individual Attentions
对 M 矩阵中的每一列做 softmax 归一化,其中当考虑单个查询词时,每列是单独的文档级关注,得到所谓的 query-to-document attention的关注,即给定一个query词,对 document 中每个词的 attention,本文用下式进行表示:

每一列都是一个文档级别的注意力,我们表示α(t)∈R |D| 作为在第t个查询词的文档级关注
- Attention-over-Attention
前三个步骤都是很多模型采用的通用做法,这一步是本文的亮点。首先,上一步是对 M 矩阵的每一列做了 softmax 归一化,这里对 M 矩阵的每一行做 softmax 归一化,即得到所谓的document-to-query attention。
我们引入另一种注意机制来自动确定每个individual的注意力的重要性,而不是使用简单的启发式方法(如求和或平均)来将这些个体注意力集中到最后的注意力上。
首先,我们计算反向注意力,即对于时间t的每个文档词,我们计算查询中的“重要性”分布,即给定单个文档词时哪些查询词更重要。 我们将逐行方式的softmax函数应用于成对匹配矩阵M,以获得查询级别的关注。 我们表示β(t)∈R | Q | 作为关于时间t处的文档词的查询级关注,这可以被视为文档到查询的关注。(对M横向求softmax)

到目前为止,我们已经获得了查询到文档的关注度α(把M竖着soft)和文档到查询的关注度β(把M横着soft)。 我们的动机是利用文档和查询之间的交互信息。
1 # Softmax over axis 2 def softmax(target, axis, mask, epsilon=1e-12, name=None): 3 with tf.op_scope([target], name, 'softmax'): 4 max_axis = tf.reduce_max(target, axis, keep_dims=True) 5 target_exp = tf.exp(target-max_axis) * mask 6 normalize = tf.reduce_sum(target_exp, axis, keep_dims=True) 7 softmax = target_exp / (normalize + epsilon) 8 return softmax 9 10 alpha = softmax(M, 1, M_mask)##mask矩阵,非零位置为1,axis=0为batch 11 beta = softmax(M, 2, M_mask)
然后我们对所有β(t)进行平均以得到平均的查询级别关注β。 请注意,我们不会将另一个softmax应用于β,因为平均个别关注不会破坏正常化条件。

这里的α的维度为|D| * |Q|,β的维度为|Q| * 1,我们在看问题的时候,并不是问题的每个单词我们都需要用到解题中,即问题中的单词的重要性是不一样的,这一步我们主要分析问题中每个单词的贡献,先定位贡献最大的单词,然后再在文档中定位和这个贡献最大的单词相关性最高的词作为问题的答案。
最后,我们计算α和β的点积得到“attended document-level attention”s∈R| D | 即attention-over-attention机制。 直观地说,该操作是在时间t查看查询词时(此时根据上步所得的每个问题词的贡献程度)计算每个单独文档级关注度α(t)的加权总和。通过每个查询词的重要性通过投票结果来做出最终决定(文档级关注)。

直观上看,就像把每个query 的word的权重去衡量每个document−level 的权重,由此学习出document 中哪个词更有可能为answer。
1 query_importance = tf.expand_dims(tf.reduce_mean(beta, 1) / tf.to_float(tf.expand_dims(doc_len, -1)), -1) 2 s = tf.squeeze(tf.matmul(alpha, query_importance), [2])
- Final Predictions
上面我们可以得到一个s 向量,这个s 向量和document长度相等,因此若某个词在document 出现多次,则该词也应该在s 中出现多次,该词的概率应该等于其在s 出现的概率之和。计算单词w是答案的条件概率,文档D的单词组成单词空间V,单词w可能在单词空间V中出现了多次,其出现的位置i组成一个集合I(w, D),对每个单词w,我们通过计算它在s中的得分并求和得到单词w是答案的条件概率,计算公式如下所示:

1 unpacked_s = zip(tf.unstack(s, FLAGS.batch_size), tf.unstack(documents, FLAGS.batch_size)) 2 y_hat = tf.stack([tf.unsorted_segment_sum(attentions, sentence_ids, FLAGS.vocab_size) for (attentions, sentence_ids) in unpacked_s])
##unsorted_segment_sum函数是用来分割求和的,第二个参数就是分割的index,index相同的作为一个整体求和
##注意这里面y_hat也就是上面所讲的s向量,但是其经过unsorted_segment_sum操作后,其长度变为vocab_size.
那在train 时,object_function 具体是怎样呢?
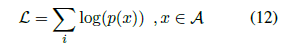
实现代码:
下面代码中的一波操作不太好理解,其在nlpnlp 代码中很常见,值得好好琢磨。
1 index = tf.range(0, FLAGS.batch_size) * FLAGS.vocab_size + tf.to_int32(answer)##这里面为啥乘以vocab_size,看下面解释,求答案在全文中的索引,也就是I(W,D) 2 3 flat = tf.reshape(y_hat, [-1])## 注意每个样本的y_hat长度为vocab_size,直接将batch_size个flat reshape成一维。 4 relevant = tf.gather(flat, index)##以index为准,找到flat中对应的值,也就是answer中的词在s向量中的概率值。 5 6 loss = -tf.reduce_mean(tf.log(relevant)) 7 8 accuracy = tf.reduce_mean(tf.to_float(tf.equal(tf.argmax(y_hat, 1), answer)))
4 N最佳重新排名策略 N-best Re-ranking Strategy
- N-best解码
我们在解码过程中提取后续候选项,而形成N个最佳列表。而不是仅挑选出具有最高可能性的候选项作为回答。
- 将候选词填入查询
作为填充式问题的一个特征,每个候选词都可以填充到查询的空白处以形成一个完整的句子。 这使我们能够根据其上下文来检查候选词。
- 特征打分
能够从很多方面为候选句子打分,本文中我们选取三种特征来进行打分形成N-best表。
(1)Global N-gram LM:这是评分句子的基本指标,旨在评估其流利程度。 基于训练集中所有的document训练8-gram模型,判断候选答案所在句子的合理性;
(2)Local N-gram LM:与全局LM不同,局部LM旨在通过给定文档来探索信息,因此统计信息是从测试时间文档中获得的。 应该注意的是,局部LM是逐个样本进行训练的, 它并未在整个测试集上进行训练,这在真实测试案例中是不合法的。 当测试样本中有许多未知单词时,此模型非常有用。基于问题所对应的的document训练8-gram模型;
(3)Word-class LM:与全局LM类似,词类LM也在训练数据的文档部分进行训练,但是这些词被转换为它的词类ID。可以通过使用聚类方法获得该词类。 在本文中,我们简单地使用mkcls工具来生成1000个词类。
- 微调权重和 重新打分和重新排名
采用K-best MIRA算法对上述三种特征进行权值训练,最后累加权值,选择损失函数最小的值作为最终的正确答案。
mkcls是一种通过使用最大似然准则来训练单词类的工具。生成的词类特别适合于语言模型或统计翻译模型。
MIRA算法是一种超保守算法,在分类,排序,回归等应用领域都取得不错的成绩。
5 实验
5.1实验设置
- 嵌入层(使用未预训练词向量)权值初始化:[−0.05, 0.05];
- l2正则化:0.0001;
- dropout:0.1;
- 隐含层:GRU由随机正交矩阵初始化
- 优化函数:Adam;
- 学习率初始化:0.001;
- gradient clip:5;
- batch size:32;
- 5-Bestlist(影响不大)
对于不同语料,嵌入层维度和隐含层单元数:

5.2 实验结果
我们的实验是在公共数据集上CNN news和CBTest NE/CN开展:
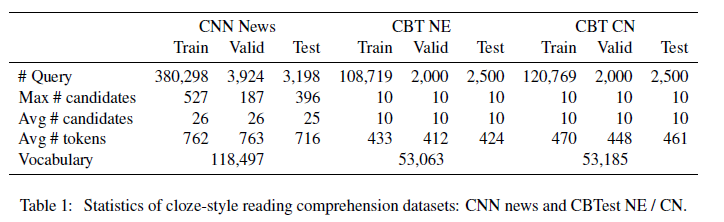
CNN News大概包括90k文档和380k问题;DailyMail包含197k 文档 和 879k 问题;CBT Test将文本根据单词属性分为NE,CN,P,V,这四种的验证集和测试集都是2000和2500的问题。
实验结果:
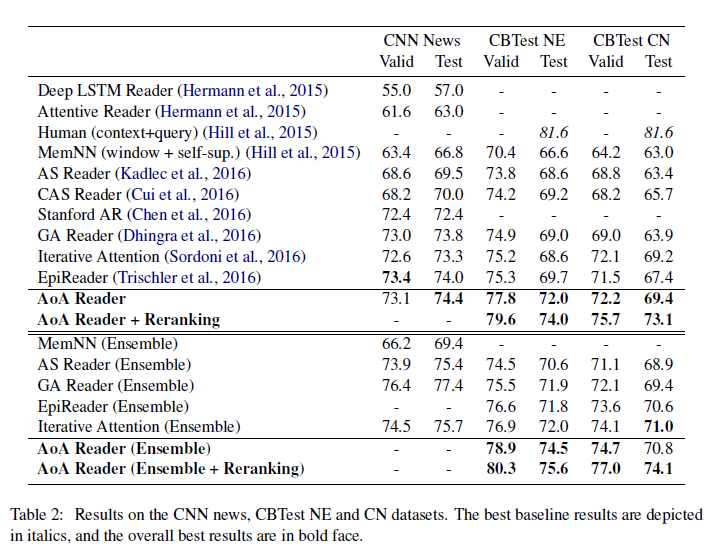
我们的AoA阅读器在当前先进的系统上有很大的优势,在CBTest NE和CN测试集中,相比EpiReader有2.3%和2.0%的绝对改进,证明了我们的模型的有效性。此外,通过在重新排序步骤中添加额外的特性,在CBTest NE/CN测试中,相对于AoA阅读器还有2.0%到3.7%的显著提升集。我们还发现,我们的单一模型可以保持与以前最好的集成系统的性能,甚至我们有0.9%的绝对改善超过最佳集成模型(迭代注意)在CBTest NE验证集。当涉及到集成模型时,我们的AoA读者还显示了显著改善了以前最好的集成模型,并建立了一个新的先进的系统。
为了调查采用attention-over-attention机制的有效性,我们也比较模型CAS模型(使用预定义的合并启发式,比如sum或avg等)。本文不使用预定义的合并启发式,而是让模型显式地学习个体之间的权重关注,使性能比CAS显著提高4.1%和3.7%可以在CNN的验证和测试集上 。
6 感悟
- 我看过一些QA、QG等方面的论文,感觉大部分都做了类似论文所说的document−level attention 操作,也就是结合query去attention documentt, 这篇创新的也做了query−level attention 操作。
- 感觉这篇论文实际上做了两层attention,在第一层中不仅做了document−level attention ,也做了query−level attention,第二层中,把结合query−level attention的信息对document−level attention 又做了attention 操作。
- 考虑在阅读理解其他方面的应用; 考虑模型是否有别的改进;研究语料库的应用;
- 单个模型和ensembel模型