Pod是kubernetes中你可以创建和部署的最⼩也是最简的单位。⼀个Pod代表着集群中运⾏的⼀个进程
Pod中封装着应⽤的容器(有的情况下是好⼏个容器),存储、独⽴的⽹络IP,管理容器如何运⾏的策略选项。Pod代
表着部署的⼀个单位:kubernetes中应⽤的⼀个实例,可能由⼀个或者多个容器组合在⼀起共享资源。
在Kubrenetes集群中Pod有如下两种使⽤⽅式:
- ⼀个Pod中运⾏⼀个容器。“每个Pod中⼀个容器”的模式是最常⻅的⽤法;在这种使⽤⽅式中,你可以把Pod想象成
是单个容器的封装,kuberentes管理的是Pod⽽不是直接管理容器。 - 在⼀个Pod中同时运⾏多个容器。⼀个Pod中也可以同时封装⼏个需要紧密耦合互相协作的容器,它们之间共享资
源。这些在同⼀个Pod中的容器可以互相协作成为⼀个service单位——⼀个容器共享⽂件,另⼀个“sidecar”容器来
更新这些⽂件。Pod将这些容器的存储资源作为⼀个实体来管理
每个Pod都是应⽤的⼀个实例。如果你想平⾏扩展应⽤的话(运⾏多个实例),你应该运⾏多个Pod,每个Pod都是⼀
个应⽤实例。在Kubernetes中,这通常被称为replication(副本)
Pod中如何管理多个容器
Pod中可以同时运⾏多个进程(作为容器运⾏)协同⼯作。同⼀个Pod中的容器会⾃动的分配到同⼀个 node 上。同⼀
个Pod中的容器共享资源、⽹络环境和依赖,它们总是被同时调度
Pod中可以共享两种资源:⽹络和存储
⽹络
每个Pod都会被分配⼀个唯⼀的IP地址。Pod中的所有容器共享⽹络空间,包括IP地址和端⼝。Pod内部的容器可以使
⽤ localhost 互相通信。Pod中的容器与外界通信时,必须分配共享⽹络资源(例如使⽤宿主机的端⼝映射)
存储
可以Pod指定多个共享的Volume。Pod中的所有容器都可以访问共享的volume。Volume也可以⽤来持久化Pod中的存储资源,以防容器重启后⽂件丢失。
为Pod的⽣命周期是短暂的,⽤后即焚的实体。当Pod被创建后(不论是由你直接创建还是被其他Controller),都会被Kuberentes调度到集群的Node上。直到Pod的进程终⽌、被删掉、因为缺少资源⽽被驱逐、或者Node故障之前这个Pod都会⼀直保持在那个Node上
注意:重启Pod中的容器跟重启Pod不是⼀回事。Pod只提供容器的运⾏环境并保持容器的运⾏状态,重启容器不
会造成Pod重启
Pod不会⾃愈。如果Pod运⾏的Node故障,或者是调度器本身故障,这个Pod就会被删除。同样的,如果Pod所在Node缺少资源或者Pod处于维护状态,Pod也会被驱逐。Kubernetes使⽤更⾼级的称为Controller的抽象层,来管理Pod实例。虽然可以直接使⽤Pod,但是在Kubernetes中通常是使⽤Controller来管理Pod的
Pod和Controller
Controller可以创建和管理多个Pod,提供副本管理、滚动升级和集群级别的⾃愈能⼒。例如,如果⼀个Node故障,
Controller就能⾃动将该节点上的Pod调度到其他健康的Node上
Pod的终⽌
Pod作为在集群的节点上运⾏的进程,所以在不再需要的时候能够优雅的终⽌掉是⼗分必要的(⽐起使⽤发送KILL
信号这种暴⼒的⽅式)。⽤户需要能够放松删除请求,并且知道它们何时会被终⽌,是否被正确的删除。⽤户想终⽌程序时发送删除pod的请求,在pod可以被强制删除前会有⼀个宽限期,会发送⼀个TERM请求到每个容器的主进程。⼀旦超时,将向主进程发送KILL信号并从API server中删除。如果kubelet或者container manager在等待进程终⽌的过程中重启,在重启后仍然会重试完整的宽限期
示例流程如下:
- ⽤户发送删除pod的命令,默认宽限期是30秒;
- 在Pod超过该宽限期后API server就会更新Pod的状态为“dead”;
- 在客户端命令⾏上显示的Pod状态为“terminating”;
- 跟第三步同时,当kubelet发现pod被标记为“terminating”状态时,开始停⽌pod进程:
i. 如果在pod中定义了preStop hook,在停⽌pod前会被调⽤。如果在宽限期过后,preStop hook依然在运⾏,第
⼆步会再增加2秒的宽限期;
ii. 向Pod中的进程发送TERM信号; - 跟第三步同时,该Pod将从该service的端点列表中删除,不再是replication controller的⼀部分。关闭的慢的pod将继续处理load balancer转发的流量;
- 过了宽限期后,将向Pod中依然运⾏的进程发送SIGKILL信号⽽杀掉进程。
- Kublete会在API server中完成Pod的的删除,通过将优雅周期设置为0(⽴即删除)。Pod在API中消失,并且在客
户端也不可⻅。删除宽限期默认是30秒。 kubectl delete 命令⽀持 —grace-period=选项,允许⽤户设置⾃⼰的宽限期。如果设置为0将强制删除pod。在kubectl>=1.5版本的命令中,你必须同时使⽤ --force 和 --grace-period=0 来强制删除pod
强制删除Pod
Pod的强制删除是通过在集群和etcd中将其定义为删除状态。当执⾏强制删除命令时,API server不会等待该pod所运⾏在节点上的kubelet确认,就会⽴即将该pod从API server中移除,这时就可以创建跟原pod同名的pod了。这时,在节点上的pod会被⽴即设置为terminating状态,不过在被强制删除之前依然有⼀⼩段优雅删除周期
Pause容器
Pause容器,⼜叫Infra容器
kubernetes中默认的配置参数是:
KUBELET_POD_INFRA_CONTAINER=--pod-infra-container-image=gcr.io/google_containers/pause-amd64:3.0
Pause容器,是可以⾃⼰来定义,官⽅使⽤的 gcr.io/google_containers/pause-amd64:3.0 容器的代码⻅Github,使⽤C语⾔编写
kubernetes中的pause容器主要为每个业务容器提供以下功能:
- 在pod中担任Linux命名空间共享的基础;
- 启⽤pid命名空间,开启init进程
主机⽹络
Pod 的⽣命周期
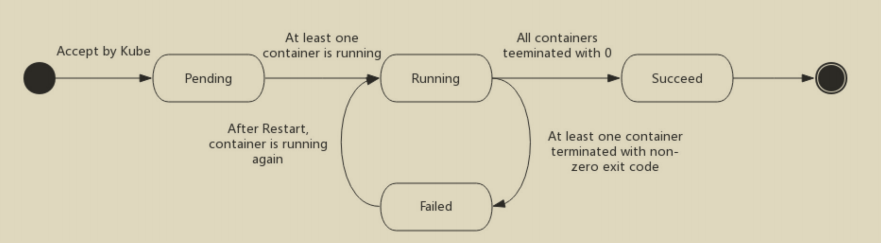
Pod phase
Pod 的 status 在信息保存在 PodStatus 中定义,其中有⼀个 phase 字段
phase 可能的值
- 挂起(Pending):Pod 已被 Kubernetes 系统接受,但有⼀个或者多个容器镜像尚未创建。等待时间包括调度
Pod 的时间和通过⽹络下载镜像的时间,这可能需要花点时间。 - 运⾏中(Running):该 Pod 已经绑定到了⼀个节点上,Pod 中所有的容器都已被创建。⾄少有⼀个容器正在运
⾏,或者正处于启动或重启状态。 - 成功(Succeeded):Pod 中的所有容器都被成功终⽌,并且不会再重启。
- 失败(Failed):Pod 中的所有容器都已终⽌了,并且⾄少有⼀个容器是因为失败终⽌。也就是说,容器以⾮0状
态退出或者被系统终⽌。 - 未知(Unknown):因为某些原因⽆法取得 Pod 的状态,通常是因为与 Pod 所在主机通信失败。
Pod 状态
Pod 有⼀个 PodStatus 对象,其中包含⼀个 PodCondition 数组。 PodCondition 数组的每个元素都有⼀个 type 字段
和⼀个 status 字段。 type 字段是字符串,可能的值有 PodScheduled、Ready、Initialized 和
Unschedulable。 status 字段是⼀个字符串,可能的值有 True、False 和 Unknown
容器探针
每次探测都将获得以下三种结果之⼀:
成功:容器通过了诊断。
失败:容器未通过诊断。
未知:诊断失败,因此不会采取任何⾏动。
有三种可⽤的控制器:
-
使⽤ Job 运⾏预期会终⽌的 Pod,例如批量计算。Job 仅适⽤于重启策略为 OnFailure 或 Never 的 Pod。
-
对预期不会终⽌的 Pod 使⽤ ReplicationController、ReplicaSet 和 Deployment ,例如 Web 服务器。
ReplicationController 仅适⽤于具有 restartPolicy 为 Always 的 Pod。 -
提供特定于机器的系统服务,使⽤ DaemonSet 为每台机器运⾏⼀个 Pod 。
所有这三种类型的控制器都包含⼀个 PodTemplate。建议创建适当的控制器,让它们来创建 Pod,⽽不是直接⾃⼰创建 Pod。这是因为单独的 Pod 在机器故障的情况下没有办法⾃动复原,⽽控制器却可以。
如果节点死亡或与集群的其余部分断开连接,则 Kubernetes 将应⽤⼀个策略将丢失节点上的所有 Pod 的 phase 设置为 Failed
状态示例
Pod 中只有⼀个容器并且正在运⾏。容器成功退出。
记录完成事件。
如果 restartPolicy 为:
Always:重启容器;Pod phase 仍为 Running。
OnFailure:Pod phase 变成 Succeeded。
Never:Pod phase 变成 Succeeded
Pod 中只有⼀个容器并且正在运⾏。容器退出失败。
记录失败事件。
如果 restartPolicy 为:
Always:重启容器;Pod phase 仍为 Running。
OnFailure:重启容器;Pod phase 仍为 Running。
Never:Pod phase 变成 Failed
Pod 中有两个容器并且正在运⾏。容器1退出失败。
记录失败事件。
如果 restartPolicy 为:
Always:重启容器;Pod phase 仍为 Running。
OnFailure:重启容器;Pod phase 仍为 Running。
Never:不重启容器;Pod phase 仍为 Running
如果有容器1没有处于运⾏状态,并且容器2退出
记录失败事件。
如果 restartPolicy 为:
Always:重启容器;Pod phase 仍为 Running。
OnFailure:重启容器;Pod phase 仍为 Running。
Never:Pod phase 变成 Failed
Pod 中只有⼀个容器并处于运⾏状态。容器运⾏时内存超出限制:
容器以失败状态终⽌。
记录 OOM 事件。
如果 restartPolicy 为:
Always:重启容器;Pod phase 仍为 Running。
OnFailure:重启容器;Pod phase 仍为 Running。
Never: 记录失败事件;Pod phase 仍为 Failed
Pod 正在运⾏,磁盘故障:
杀掉所有容器。
记录适当事件。
Pod phase 变成 Failed。
如果使⽤控制器来运⾏,Pod 将在别处重建。
Pod 正在运⾏,其节点被分段。
节点控制器等待直到超时。
节点控制器将 Pod phase 设置为 Failed。
如果是⽤控制器来运⾏,Pod 将在别处重建。