学习视频课程(20')
- 学习福州大学网络课程 网络空间安全概论,形成学习笔记,发布专门博客,至少完成第五章的视频学习。
- 或学习密歇根大学的网络课程Internet history,形成学习笔记,另外发布专门的博客。至少完成第二周的视频学习。
- 以上两门课程二选一即可。
博客地址:https://www.cnblogs.com/fzulinxin/p/10366726.html
实验题(30'+120')
背景
黑客风波过后,一切又恢复了正常。但你总觉得有些不安,按照之前的方法:把所有请求都记录下来,的确能很准确地显示所有用户的请求情况。
但是请求实在太多,把它们都记下来,需要花费巨大的空间来存储,导致许多预算用在了购买记录请求的空间上,而且服务器的速度也下降不少。
有没有更好的办法?你觉得自己遇到了瓶颈,但别人肯定也遇到过同样的问题,何不借鉴别人的方法?
查阅文献过程中,果然,发现一种叫做 sketch 的技术十分火热,可以解决这个问题,它可以显著地降低空间的使用。
你很兴奋,你想尽快地把这个技术部署到服务器上。
热身题(30')
服务器正在运转着,也不知道这个技术可不可用,万一服务器被弄崩了,那损失可不小。
所以, 决定在虚拟机上试验一下,不小心弄坏了也没关系。需要在的电脑上装上虚拟机和linux系统
安装虚拟机(可参考Vmware、Virtual Box等)
安装ubuntu系统(推荐安装16.04版本)
写一个helloworld程序,在ubuntu系统上编译运行
(你可能需要了解linux系统的终端和一些基本命令、文本编辑工具nano、如何编译代码、运行程序)
1、安装Virtual Box软件。
2、新建一个虚拟机,按提示均默认即可。
3、下载ubuntu16.04系统镜像,放入对应文件夹。
4、启动虚拟机,根据提示安装系统。(选择中文安装程序时会遇到错误,语言选择为English)
5、安装所需软件
- 安装nano编辑器
apt-get install -y nano
- 安装gcc
sudo apt-get install build-essential
6、编写helloworld.c
nano helloworld.c
#include<stdio.h>
int main(){
printf("helloworld!
");
return 0;
}
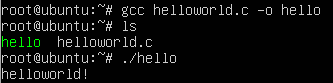
7、编译并运行helloworld
gcc helloworld.c -o hello
./hello
基本题 (120')
了解新技术(20')
众多sketch的技术中,Count-min sketch 常用也并不复杂,但你可能需要稍微了解一点点散列的知识。从它入手不失为一个好选择,把它记录在你的技术博客上:
简单描述什么是sketch
描述Count-min sketch的算法过程
- sketch:
sketch是基于散列的数据结构,通过设置散列函数,将具有相同散列值的键值数据存入相同的桶内,以减少空间开销。
桶内的数据值作为测量结果,是真实值的近似。
利用开辟二维地址空间,多重散列等技术减少散列冲突,提高测量结果的准确度。
--引用《基于sketch的网络测量方法介绍》
- Count-min sketch:
数据添加:对每个新的数据,用某个哈希函数映射后添加到一个数组内,再用另一个哈希函数映射后添加到另一个数组内,以此类推。
数据查询:对查询的数据,返回所有数组记录值的最小值。
实现新技术(30')
大致了解了Count-min sketch,接下来就需要实现它了。本着不需要重复造轮子的思想,你上github一查,果然发现了相关代码。
并不需要深刻理解代码,你只需要会用,你的目标是在虚拟机上跑通Count-min sketch:
克隆一种版本(python或者c语言)的代码,大致了解如何使用这个代码,在ubuntu系统上编译。自己任意编写一个小测试,成功运行这个代码。
你也可以自己实现Count-min sketch。
1、从github上克隆count-min sketch算法代码
参考github库链接:https://github.com/alabid/countminsketch
2、修改test文件进行测试
然后。。。。就出错了。。。
似乎该代码在linux下有bug:其在新建指针时没有用new开空间,导致有时正常运行,绝大情况为Segmentation fault。
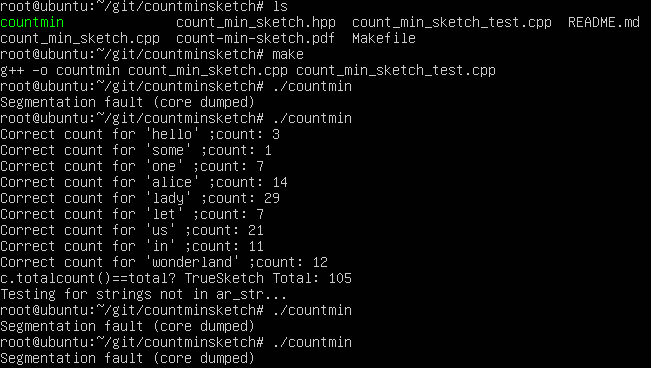
由于在服务器版的ubuntu内修正代码工作量巨大,没能调试完成。
获取用户请求(15')
现在需要获取用户的请求信息,其实请求就是网络传输的数据包,可以使用自己的网络环境来模拟服务器的请求,使用工具来捕获这个数据包:
安装并使用抓包工具tcpdump
输入tcpdump -n 获取数据包的信息
使用linux 重定向的方法把该信息用文本文件存起来,文件命名为 pakcet_capture.txt。
请求的用户用源ip地址端口号和目的ip地址端口号来标识,请求的大小用包的长度来标识,例如:
11:07:30.240275 IP 203.107.41.32.9018 > 192.168.0.101.55730: Flags [P.], seq 1:36, ack 39, win 17688, length 35
请求的用户
203.107.41.32.9018 > 192.168.0.101.55730
请求的大小
length 35
请求格式处理(25')
处理为这样的格式(请求的实际形式)
203.107.41.32.9018>192.168.0.101.55730 35
使用程序把第一条请求处理成第二条请求的格式
使用linux 重定向的方法把该信息用文本文件存起来,命名为Request.txt。
测试新技术(30')
完事具备,只欠东风:
用跑通的Count-min sketch程序读文件,获得最后的处理结果,请求大小超过阈值T认定为黑客,此处T自己定义。
对于你所完成题目,把实现思路和实现结果记录在博客中,把代码提交到github的仓库上。
开放题(50')
理论部分(25')
解释为什么 sketch 可以省空间
用流程图描述Count-min sketch的算法过程
拿它和你改进后方法进行对比,分析优劣
为什么 sketch 可以省空间:
sketch牺牲了准确度,在一定的数组范围中记录哈希后的索引,没有记录原键值。因哈希的特性不同键值的索引碰撞,节省碰撞的这部分空间。
从整体数据结构上分析,哈希让数据相对更加均匀地分布,对数组的利用率更高。
流程图:

吐槽Count-min sketch:
很巧妙的方法啊,虽然在准确度上还有不足,但其解决sketch准确度的思路十分简洁有效,实现也比较容易。
在数据量很小时会比直接记录耗费更多的内存。
实验部分(25')
按基本题中的处理方法,要存请求、处理请求、读请求,速度太慢了,要是能把获取的请求直接用count-min sketch 处理就好了:
尽可能减少中间的文件读写环节
实时处理请求
咕咕咕
参考文献
Linux超简单文本编辑器:nano https://blog.csdn.net/u012561176/article/details/45829223
Ubuntu下gcc安装及使用 https://blog.csdn.net/lucifa_li/article/details/79483686
在Linux(Ubuntu)中使用终端编译并运行.c和.cpp文件 https://blog.csdn.net/liuzubing/article/details/78303167
基于sketch的网络测量方法介绍 https://www.sdnlab.com/22685.html