你们的服务注册中心进行过选型调研吗?对比一下各种服务注册中心?
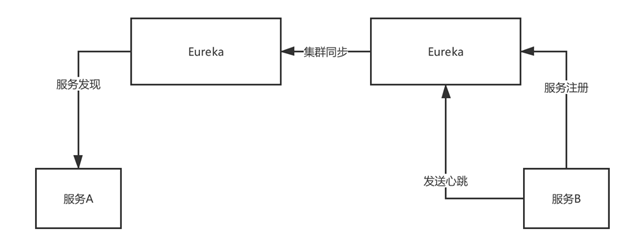
Eureka服务注册发现集群原理:
Eureka,peer-to-peer,部署一个集群,但是集群里每个机器的地位是对等的,各个服务可以向任何一个Eureka实例服务注册和服务发现,集群里任何一个Eureka实例接收到写请求之后,会自动同步给其他所有的Eureka实例。
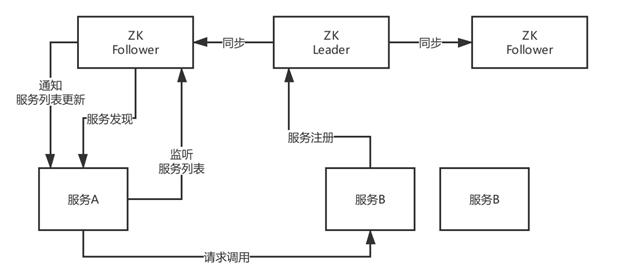
Zookeeper服务注册发现原理:
Leader + Follower两种角色,只有Leader可以负责写也就是服务注册,他可以把数据同步给Follower,读的时候leader/follower都可以读。
一致性保障:CP or AP
CAP,C是一致性,A是可用性,P是分区容错性。
ZooKeeper是有一个leader节点会接收数据, 然后同步写其他节点,一旦leader挂了,要重新选举leader,这个过程里为了保证C,就牺牲了A,不可用一段时间,但是一个leader选举好了,那么就可以继续写数据了,保证一致性。
Eureka是peer模式,可能还没同步数据过去,结果自己就死了,此时还是可以继续从别的机器上拉取注册表,但是看到的就不是最新的数据了,但是保证了可用性,强一致,最终一致性。
阐述一下你们的服务注册中心部署架构,生产环境下怎么保证高可用?
Eureka高可用,至少2台做集群。
两个分支内相互配置另一台的ip和端口号。
你们系统遇到过服务发现过慢的问题吗?怎么优化和解决的?
eureka,必须进行优化参数:
// 客户端的有效负载缓存应该更新的时间间隔,默认为30 * 1000毫秒
eureka.server.responseCacheUpdateIntervalMs = 30000(30s) -> 3000(3s)
// 从eureka服务器注册表中获取注册信息的时间间隔(s),默认为30秒
eureka.client.registryFetchIntervalSeconds = 30000 -> 3000
// 客户端多长时间发送心跳给eureka服务器,表明它仍然活着,默认为30 秒
eureka.client.leaseRenewalIntervalInSeconds = 30 -> 3
// 过期实例应该剔除的时间间隔,单位为毫秒,默认为60 * 1000
eureka.server.evictionIntervalTimerInMs = 60000 -> 6000(6s)
// Eureka服务器在接收到实例的最后一次发出的心跳后,需要等待多久才可以将此实例删除,默认为90秒
eureka.instance.leaseExpirationDurationInSeconds = 90 -> 9(s)
服务发现的时效性变成秒级,几秒钟可以感知服务的上线和下线
说一下自己公司的服务注册中心怎么技术选型的?生产环境中应该怎么优化?
服务注册、故障 和发现的时效性是多长时间?
注册中心最大能支撑多少服务实例?
如何部署的,几台机器,每台机器的配置如何,会用比较高配置的机器来做,8核16G,16核32G的高配置机器来搞,基本上可以做到每台机器每秒钟的请求支撑几千绝对没问题。
可用性如何来保证?
有没有做过一些优化,服务注册、故障以及发现的时效性,是否可以优化一下,用eureka的话,可以尝试一下,配合我们讲解的那些参数,优化一下时效性,服务上线、故障到发现是几秒钟的时效性。
zk,一旦服务挂掉,zk感知到以及通知其他服务的时效性,服务注册到zk之后通知到其他服务的时效性,leader挂掉之后可用性是否会出现短暂的问题,为了去换取一致性。
如果需要部署上万服务实例,现有的服务注册中心能否抗住?如何优化?
核心思想:注册中心主从架构,分片存储服务注册表,服务按需主动拉取注册表,不用全量拉取/推送,避免反向通知瞬时高并发。
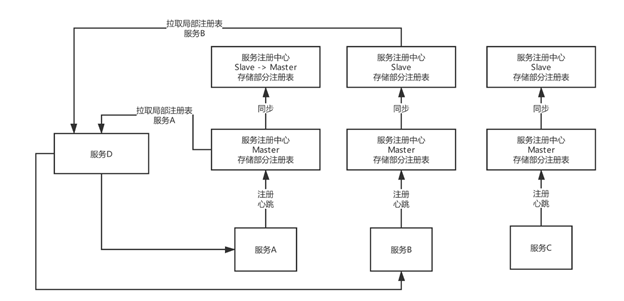
自研注意点:
客户端:
1. 服务拉取:不用全量拉取,按需拉取(有疑问,怎么设计按需拉取?)。还需要一个用于校验拉取增量数据之后数据是否完整的过程。
2. 心跳发送。
3. 服务下线。
服务端:
1.服务注册: 服务注册表注意读写高并发控制,保证线程安全,也要降低锁的争用。
2. 健康检查:单位时间内,如果所注册服务没有续约,则要将其下线。
3. 集群同步:根据具体业务需求,制定合适的集群架构方案,保证吞吐量。
参考资料:
21天互联网Java进阶面试训练营(分布式篇)-- 中华石杉