本人使用Beautifulsoup需要理解的概念,所以在此记录。
详细方法请参考 官方网址
1 Beautifulsoup类中的基本元素 soup = Beautifulsoup(...)
1.1 Tag: 标签,最基本单位,分别用<>和</>来表示开头和结。soup.Tag
1.2 Name: 标签的名字,soup.Tag.name
1.3 NavigableString: 标签内非属性的字符串,soup.Tag.string
1.4 Attributes: 标签的属性,字典dict形式, soup.Tag.attrs; 也可以直接访问属性的value, soup.Tag[key]
2 Beautifulsoup的遍历功能
遍历分为上行遍历、下行遍历和平行遍历
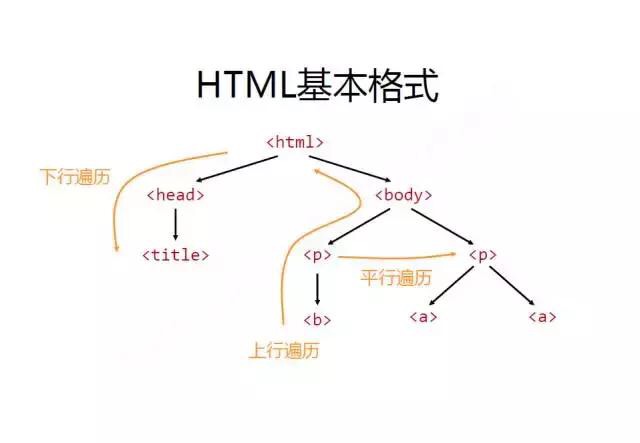
2.1 下行遍历
.contents: 子节点的列表,将Tag的所有儿子节点存入列表。
.children: 子节点的迭代类型,循环遍历儿子节点。
.desendants: 子孙节点的迭代类型,包含所有子孙节点。对Tag进行递归循环
2.2 上行遍历
.parent: 节点的父节点标签
.parents: 节点先辈的迭代类型, 用于循环遍历先辈节点
3.3 平行遍历
.next_sibling: 返回下一个平行节点的标签
.previous_sibling: 返回上一个平行节点的标签
.next_siblings: 生成器类型,返回后续的节点标签
.previous_sibling: 生成器类型,返回前序的节点标签
3 find_all(或者叫find)方法
根据文档可知
find_all( name , attrs , recursive , text , **kwargs ) 参数解析
name: 查找名字的Tag
**kwargs: 如果一个指定名字的参数不是搜索内置的参数名,搜索时会把该参数当作指定名字tag的属性来搜索,
例如包含一个名字为 id 的参数,Beautiful Soup会搜索每个tag的”id”属性