我们都知道python网络编程的两大必学模块socket和socketserver,其中的socketserver是一个支持IO多路复用和多线程、多进程的模块。
一般我们在socketserver服务端代码中都会写这么一句:
server = socketserver.ThreadingTCPServer(settings.IP_PORT, MyServer)
ThreadingTCPServer这个类是一个支持多线程和TCP协议的socketserver,它的继承关系是这样的:
class ThreadingTCPServer(ThreadingMixIn, TCPServer): pass
右边的TCPServer实际上是它主要的功能父类,而左边的ThreadingMixIn则是实现了多线程的类,它自己本身则没有任何代码。
http://python.jobbole.com/86406/
1、进程、线程、协程、IO阻塞各自的区别应用:
线程和进程的操作是由程序触发系统接口,最后的执行者是系统,它本质上是操作系统提供的功能。而协程的操作则是程序员指定的,在python中通过yield,人为的实现并发处理。
协程存在的意义:对于多线程应用,CPU通过切片的方式来切换线程间的执行,线程切换时需要耗时。协程,则只使用一个线程,分解一个线程成为多个“微线程”,在一个线程中规定某个代码块的执行顺序。
协程的适用场景:当程序中存在大量不需要CPU的操作时(IO)。
在不需要自己“造轮子”的年代,同样有第三方模块为我们提供了高效的协程,这里介绍一下greenlet和gevent。本质上,gevent是对greenlet的高级封装,因此一般用它就行,这是一个相当高效的模块。
在使用它们之前,需要先安装,可以通过源码,也可以通过pip
2、并发、并行
并发:在一个时间段,处理多个任务,单核也可以并发(CPU分时间片);
伪并行,单个cpu+多道技术,所用的方法是多路复用:时间上+空间上
时间上:当一个程序遇到io,可以去执行另外一个程序
空间上:程序之间的内存必须分割,这种分割需要硬件层面实现,由操作系统控制。
并行:在同一个时刻,处理多个任务,必须多核才能并行;
3、同步、异步
同步与异步针对的是函数/任务的调用方式:同步就是当一个进程发起一个函数(任务)调用时,一直等待函数完成,而进程继续处于激活状态。
异步:是当一个进程发起一个函数(任务)调用的时候,不会等函数返回,而是继续往下执行,函数返回的时候通过状态、通知、事件等方式
通知进程任务完成。
4、阻塞、非阻塞
是进程或线程,阻塞是当请求不能满足的时候就将进程挂起,而非阻塞则不会阻塞当前进程。
异步通常和回调函数联系在一起
主要研究网络传输的io模型
再说一下IO发生时涉及的对象和步骤。对于一个network IO (这里我们以read举例),它会涉及到两个系统对象,一个是调用这个IO的process (or thread),另一个就是系统内核(kernel)。
当一个read操作发生时,该操作会经历两个阶段:
1)等待数据准备 (Waiting for the data to be ready)
2)将数据从内核拷贝到进程中(Copying the data from the kernel to the process)
记住这两点很重要,因为这些IO模型的区别就是在两个阶段上各有不同的情况。
服务端会发生三个io:accept,recv,send
感觉明显的等:accept,recv
recv阻塞()分两步:1、等数据 等客户端消息传到操作系统。
2、由操作系统内存copy到应用程序的内存
不会感到明显等send ,直接把应用程序把自己的数据copy给操作系统,本地拷贝

几种IO模型不同在对这两个阶段的处理上
1)等待数据准备 (Waiting for the data to be ready)
2)将数据从内核拷贝到进程中(Copying the data from the kernel to the process)
(1)阻塞io就是
(2)非阻塞io模型:
在非阻塞式IO中,用户进程其实是需要不断的主动询问kernel数据准备好了没有。
GIL全局解释器锁:
它在解释器的层面限制了程序在同一时间只有一个线程被CPU实际执行,而不管你的程序里实际开了多少条线程
同步调用 vs 异步调用 异步调用与同步调用指的是提交任务的两种方式 同步调用:提交完任务后,就在原地等待任务执行完毕,拿到运行结果/返回值后再执行下一行代码 同步调用下任务的执行是串行执行 异步调用:提交完任务后,不会原地等待任务执行完毕,结果 futrue = p.submit(task,i),结果记录在内存中, 直接执行下一行代码 同步调用下任务的执行是并发执行
IO密集型:多线程(Socket)、爬虫、wed
计算密集型:多进程(金融分析)
进程之间的通信:
线程之间的通信:
(多核指一个cpu有多个运算器)
进程下:1、并发(伪并行)。一个cpu同一时刻只能执行一个任务(单个cpu+多道技术实现并发,)
多道技术是为解决多个程序竞争或者说共享同一个资源的有序调度问题,解决方式即多路复用,多路复用分为时间上和空间上的复用
CPU是负责运算和处理的,内存是交换数据的。
空间上的复用:将内存分为几部分,每个部分放入一个程序,这样,同一时间内存中就有了多道程序。
时间上的复用:当一个程序在等待I/O时,另一个程序可以使用cpu,如果内存中可以同时存放足够多的作业,则cpu的利用率可以接近100%,类似于我们小学数学所学的统筹方法。(操作系统采用了多道技术后,可以控制进程的切换,或者说进程之间去争抢cpu的执行权限。这种切换不仅会在一个进程遇到io时进行,一个进程占用cpu时间过长也会切换,或者说被操作系统夺走cpu的执行权限)
2、并行:同时运行,只要具备多个cpu才能实现并行
并发方式:1、线程(Thread)

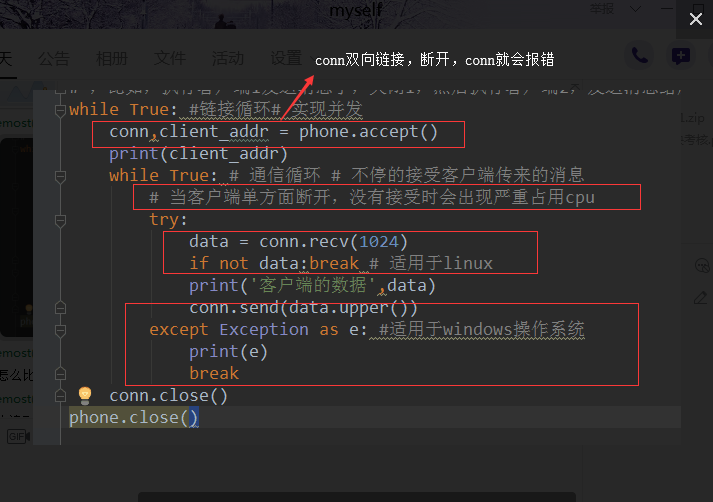
SOCKET的链接循环和通信循环、以及客户端异常断开的服务端的处理机制
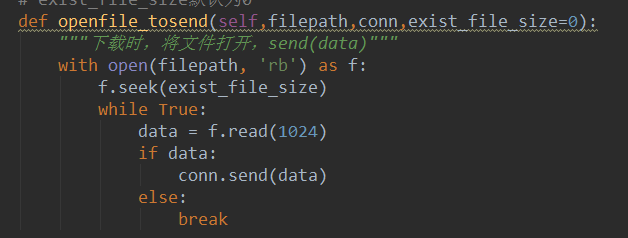
断点续传和文件比较md5值
已下载的文件getsize(filepath)和原文件对比
服务端:
客户端:
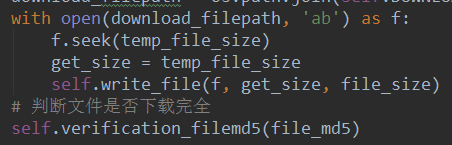

判断文件的一致性Md5值
先读取文件再进行md5操作

多线程与多进程的区别
1、开启速度 在主进程下开启线程比 开启子进程快 (线程:线程先执行,在执行进程程序) 2、pid 对比:在主进程下开启多个线程(进程和线程pid相同);在主进程下开启子进程(pid不相同) 3、同一进程内的线程共享该进程的数据(进程之间的地址是隔离的;同一进程内的线程共享该进程的地址空间)
进程池与线程池的区别


from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor # 为什么建池 :我们必须对服务器开启的进程数或者线程数加以控制,让机器在一个自己可以承受的范围内运行 # 这就是进程池或线程池的作用 import os,time,random from threading import currentThread def task(name): print(f"{name} 线程:{currentThread().getName()} pid:{os.getpid()} run") time.sleep(random.randint(1,3)) if __name__ == '__main__': pool = ThreadPoolExecutor(4) # 4个线程池的容量设定, for i in range(10): pool.submit(task,'alex %s'%i) pool.shutdown(wait=True)#等待池内所有任务执行完毕回收完资源后才继续 print('主') alex 0 线程:ThreadPoolExecutor-0_0 pid:11164 run alex 1 线程:ThreadPoolExecutor-0_1 pid:11164 run alex 2 线程:ThreadPoolExecutor-0_2 pid:11164 run alex 3 线程:ThreadPoolExecutor-0_3 pid:11164 run alex 4 线程:ThreadPoolExecutor-0_2 pid:11164 run alex 5 线程:ThreadPoolExecutor-0_3 pid:11164 run alex 6 线程:ThreadPoolExecutor-0_0 pid:11164 run alex 7 线程:ThreadPoolExecutor-0_0 pid:11164 run alex 8 线程:ThreadPoolExecutor-0_1 pid:11164 run alex 9 线程:ThreadPoolExecutor-0_3 pid:11164 run 主