动态爬取豆瓣电影中“更多”电影详情数据
作业需求: 1.使用任意代理IP进行如下操作 2.使用requests模块进行豆瓣电影的个人用户登录操作 3.使用requests模块访问个人用户的电影排行榜->分类排行榜->任意分类对应的子页面 4.爬取需求3对应页面的电影详情数据 5.爬取3对应页面中滚动条向下拉动2000像素后加载出所有电影详情数据,存储到本地json文件中或者相应数据库中 【备注】电影详情数据包括:海报url、电影名称、导演、编剧、主演,类型,语言,上映日期,片长,豆瓣评分 建议:用Pycharm开发
开发中经验总结:
1、设置多个代理ip每次随机选取
2、在测试阶段建议先把数据下载到本地,在本地取保存的数据,避免被反爬处理,,导致因访问频繁无法进行数据处理
3、本次数据解析采用:
soup = BeautifulSoup(content_page, 'lxml')
4、加深了对Beautiful Soup对象类型---Tag对象的理解
https://www.cnblogs.com/wuwenyan/p/4773427.html
4.1 Tag Tag对象 Tag就是html文件中的标签以及标签之间的内容,例如以下就是一个Tag。 1 <title>The Dormouse's story</title>
movie_detail = soup.select('.subject > #info > span')[2].select('span > a')
注意:如果得到的是'bs4.element.Tag'类型的对象可以继续进行后续的.操作,即能进行soup对象所能进行的操作,
所以需要确保一个对象是'bs4.element.Tag'类型后再进行后续对其的操作,例如后面将介绍的.find方法是Tag对象才拥有的。
5、python BeautifulSoup怎么获取无标签文本?
-------------------------------------------------------

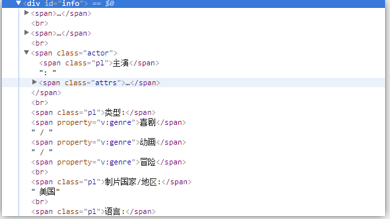
--------------------
# 下面的方法可以获取全部内容 info所在标签下的所有文本信息 span_class = soup.select('#info') for index in span_class: print(index.text)

自己测试用的代码:


import os,sys #添加环境变量 BASE_DIR = os.path.abspath(__file__) sys.path.append(BASE_DIR) from bs4 import BeautifulSoup import json #电影详情数据包括:海报url、电影名称、导演、编剧、主演,类型,语言,上映日期,片长,豆瓣评分 fp2 = open('douban_detail.html', 'r', encoding='utf-8') #content_page = requests.get(url=movie_url, headers=settings.headers,proxies=settings.proxy).text soup = BeautifulSoup(fp2,'lxml') # https://www.cnblogs.com/wuwenyan/p/4773427.html img_url = soup.select('#mainpic > a > img')[0]['src'] print('img:::',img_url) movie_name = soup.select('#content > h1 > span')[0].text # 只取中文--文件好命名 print('电影名字:',movie_name.split(' ')[0]) print('电影名字:',movie_name) movie_detail = soup.select('.subject > #info > span') movie_director = movie_detail[0].select('span > a') # print(movie_director) name_list = '' for director in movie_director: name_list += '/'+director.text print('导演::',name_list) screenwriter = movie_detail[1].select('span > a') name_list2 = '' for writer in screenwriter: name_list2 += '/' + writer.text print('编剧::', name_list2) name_list3 = '' movie_crew = movie_detail[2].select('span > a') for actor in movie_crew: name_list3 += '/' + actor.text print('演员::', name_list3) #----------------------------------------------- movie_type = soup.find_all('span',property="v:genre") name_list4 = '' for actor in movie_type: name_list4 += '/' + actor.text print('类型',name_list4) print('-----------------') # 下面的方法可以获取全部内容 content_list = '' content_list += '电影名字:'+movie_name+' '+ '海报url:'+img_url span_class = soup.select('#info') for index in span_class: content = index.text content_list+=content print(content_list) with open('detail.json','w',encoding='utf-8')as f: json.dump(content_list,f)
github地址 点击