Hadoop的HDFS主要分为3个部分:
NameNode:元数据操作
DataNode:文件分割存储
SecondNameNode:元数据转移
客户端如何存放文件到Hadoop集群里
在hadoop的客户端里上传文件,我们只需要跟输入虚拟路径hdfs://hadoop001:9000/fold1/fold2/fold3/tmp.log就可以,那hdfs是如何存放fold1/fold2/fold3/tmp.log到集群里的呢?
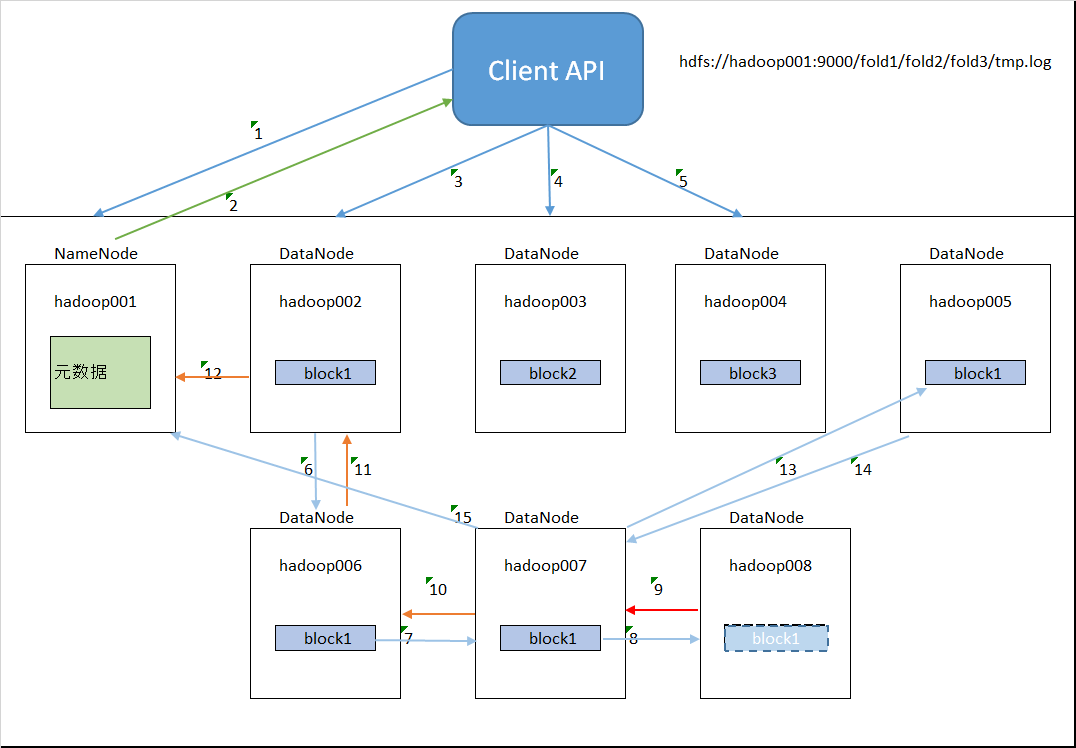
1.客户端发送保存文件请求给NameNode,告诉NameNode我需要把tmp.log保存到虚拟目录/fold1/fold2/fold3/下;
2.NameNode会在维护的元数据里查询/fold1/fold2/fold3/tmp.log是否已经存在。如果存在就返回一个信息告诉客户端不用保存请求的文件,如果不存在就告诉客户端可以进行文件存放操作,
并告诉客户端你可以把tmp.log保存在那几个DataNode上(元数据大约是:/fold1/fold2/fold3/tmp.log,{blk_1,blk_2,blk_3},[{blk_1:[hadoop002,hadoop006,hadoop007,hadoop008]},{blk_2:[hadoop003,....]}......]);
3.客户端把tmp.log被分为3块(看文件大小决定分为多少块),第一块放到DataNode hadoop002上;
4.第二块放到DataNode Hadoop003上(优先放到另一个机架上);
5.第三块放到DataNode Hadoop004上(优先放到再一个机架上);
6.大家都知道,为了防止服务器断电和损坏,我们还配置了数据备份容灾。假如我们配置备份4份bolk,我们把block1备份到DataNode hadoop006上;
注意:当客户端写完3个block到DataNode上后,它不参与block的备份,备份只是DataNode与DataNode之间的操作。并且客户端的写入block1与DataNode之间的
备份是异步执行的。
7.我们把block1备份到DataNode hadoop007上;
8.我们把block1备份到DataNode hadoop008上。当然block1也可以备份到除了hadoop002的其它DataNode上,
这里只是为了方便讲解才人为的分配了DataNode。block2,3也会有备份,我们不再赘述;
9.假如当我们备份第四份block1失败的时候我们怎么办?当备份失败时,DataNode hadoop008会告诉007说008备份失败;
10.007是block1的第三次备份。它没有备份失败但是它会把008的备份失败和007的成功传给006;
11.006把007,008的信息传递给002;
12.002会告诉NameNode说002,006,007备份成功,但是008备份block1失败。NameNode会在002,006,007中找一个DataNode,让它为拷贝源,
在集群中找一个合适的DataNode再次备份block1的第四份;
13.007会再次拷贝一份block1到005里;
14.005备份成功返回成功信息给007;
15.007告诉NameNode hadoop001 block1备份成功。
NameNode 元数据管理机制
在一个Hadoop集群里一般只有一个NameNode,它管理着文件的取出,存入,计算等。当有几万个客户端访问时,一个NameNode是如何做到多任务,快速的回复的呢?
关键字是内存,因为内存相对硬盘来说读写速度快。当然,硬盘上也会保存元数据。元数据时什么?每一个block的链接就是一条元数据。在元数据里,既有新插入的文件链接,
也有以前已经保存过的文件链接,当客户端需要保存新的文件和查找旧的文件时,都是在和元数据交互。
现在大家知道了我们插入和取出文件数据的时候是从内存中得到的,但是如果NameNode突然断电了,内存中的数据就会丢失,DataNode中的文件链接在NameNode里不存在了。
也就是说DataNode中的数据根本取不到了。怎么办?所以还必须在NameNode的磁盘文件中保存一份和内存一样的数据,我们叫磁盘中保存的元数据文件为fsimage。
大家再想一下,我应该什么时点去同步内存和fsimage文件的内容?如果每时每刻同步的话,对内存和磁盘都会造成很大的影响,毕竟NameNode的工作和访问量太大。如果定时的
的话,万一NameNode在没达到定时的时间断电了,NameNode就有可能丢数据。hadoop为了解决这个问题又在磁盘上引入了一个磁盘文件edits log文件。这个文件就相当于一个日志文件,
大小大约64M左右,它只存储最新的元数据。
所以,NameNode应该是这样管理元数据的:
1.客户端请求上传文件时,NameNode会计算这个文件分为几个块,写入到哪个DataNode,这个时候NameNode就会记录元数据了。它会先在edits log文件中记录元数据操作日志。
2.NameNode返回给客户端,告诉客户端你应该把文件的各个块存入到哪个DataNode上。
3.客户端开始往DataNode上写第一份block文件。
4.文件写完后NameNode会收到完毕通知。
5.把这个文件的各个块信息更新到NameNode内存中。更新完后,如果NameNode断电了,我们可以在edit log文件中找到新的数据,不会丢失新数据。
6.如果edits log文件被写满(fs.checkpoint.size指定edits log文件的最大值,默认64M),它需要把它里面的内容更新到fsimage文件中。也就是edits log和fsimage做合并。这样,fsimage就会跟内存中的数据同步。在这种情况下,内存和fsimage没有交互,但是它们的数据是同步的,
这样既能保证资源的不浪费,又能保证数据的安全。
7.这时候如果我们在NameNode做edits log和fsimage文件的合并,会造成资源过度使用,会影响访问速度。就需要secondNameNode了。
8.当NameNode发现edits log写满了,或者,fs.checkpoint.period指定的两次checkpoint的最大时间到了,默认3600秒,它会通知secondNameNode进行checkpoint操作。
9.SecondNameNode会通知NameNode不要再往edits log里写东西了,我要拷贝你的文件进行合并了。
10.NN(NameNode)收到SN(SecondNameNode)的通知后并没有停止新数据的写入,它会创建一个edits.new的临时文件来接受新写入的数据。
11.SN通过Http把edits log文件和fsimage文件下载下来。
12.SN利用自己的资源把这两个文件合并生成一个新的镜像文件fsimage.chkpoint。
13.把新生成的文件上传给NN。
14.NN把edit log文件删除并把edits.new重命名为edit log。
15.NN把fsimage文件删除,并把fsimage.chkpoint重命名为fsimage.
经过以上过程,不管新插入的数据还是旧有的数据都不会丢,即使断电也能保证数据的完整性。