11 数据科学家80%时间都花费在了这些清洗任务上?
没有高质量的数据,就没有高质量的数据挖掘,而数据清洗是高质量数据的一道保障。

数据质量的准则——完全合一
完整性:单条数据是否存在空值,统计的字段是否完善。
全面性:观察某一列的全部数值,比如在 Excel 表中,我们选中一列,可以看到该列的平均值、最大值、最小值。我们可以通过常识来判断该列是否有问题,比如:数据定义、单位标识、数值本身。
合法性:数据的类型、内容、大小的合法性。比如数据中存在非 ASCII 字符,性别存在了未知,年龄超过了 150 岁等。
唯一性:数据是否存在重复记录,因为数据通常来自不同渠道的汇总,重复的情况是常见的。行数据、列数据都需要是唯一的,比如一个人不能重复记录多次,且一个人的体重也不能在列指标中重复记录多次。
1. 完整性问题
1)缺失值:在数据中有些年龄、体重数值是缺失的,这往往是因为数据量较大,在过程中,有些数值没有采集到。
通常我们可以采用以下三种方法:
删除:删除数据缺失的记录;
均值:使用当前列的均值: df['Age'].fillna(df['Age'].mean(), inplace=True)
高频:使用当前列出现频率最高的数据。
2)空行:我们发现数据中有一个空行,除了 index 之外,全部的值都是 NaN。
Pandas 的 read_csv() 并没有可选参数来忽略空行,删除全空的行: df.dropna(how='all',inplace=True)
2. 全面性问题
1)列数据的单位不统一
# 将磅(lbs)转化为千克(kgs) # 获取 weight 数据列中单位为 lbs 的数据 rows_with_lbs = df['weight'].str.contains('lbs').fillna(False) print df[rows_with_lbs] # 将 lbs转换为 kgs, 2.2lbs=1kgs for i,lbs_row in df[rows_with_lbs].iterrows(): # 截取从头开始到倒数第三个字符之前,即去掉lbs。 weight = int(float(lbs_row['weight'][:-3])/2.2) df.at[i,'weight'] = '{}kgs'.format(weight)
3. 合理性问题
1)非 ASCII 字符
# 删除非 ASCII 字符 df['first_name'].replace({r'[^x00-x7F]+':''}, regex=True, inplace=True) df['last_name'].replace({r'[^x00-x7F]+':''}, regex=True, inplace=True)
4. 唯一性问题
1)一列有多个参数:在数据中不难发现,姓名列(Name)包含了两个参数 Firstname 和 Lastname。
为了达到数据整洁目的,我们将 Name 列拆分成 Firstname 和 Lastname 两个字段。我们使用 Python 的 split 方法,str.split(expand=True),将列表拆成新的列,再将原来的 Name 列删除。
# 切分名字,删除源数据列 df[['first_name','last_name']] = df['name'].str.split(expand=True) df.drop('name', axis=1, inplace=True) #这里的axis=1可以看成是删除列;类比如果是删除的某index行参数要写axis=0
2)重复数据:我们校验一下数据中是否存在重复记录。如果存在重复记录,就使用 Pandas 提供的 drop_duplicates() 来删除重复数据
# 删除重复数据行 df.drop_duplicates(['first_name','last_name'],inplace=True)
作业:清洗这个表格
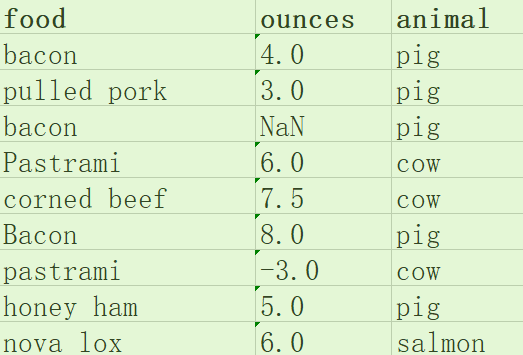
步骤一:python导入Excel
# 步骤一:python导入Excel import pandas as pd from pandas import Series, DataFrame df = pd.read_excel('data.xlsx',engine='openpyxl') df.to_excel('food.xlsx') print(df)
food ounces animal 0 bacon 4.0 pig 1 pulled pork 3.0 pig 2 bacon NaN pig 3 Pastrami 6.0 cow 4 corned beef 7.5 cow 5 Bacon 8.0 pig 6 pastrami -3.0 cow 7 honey ham 5.0 pig 8 nova lox 6.0 salmon
#步骤二 df['food'] = df['food'].str.lower() # 统一为小写字母 df.dropna(inplace=True) # 删除数据缺失的记录 df['ounces'] = df['ounces'].apply(lambda a: abs(a)) # 负值不合法,取绝对值 print(df)
food ounces animal 0 bacon 4.0 pig 1 pulled pork 3.0 pig 3 pastrami 6.0 cow 4 corned beef 7.5 cow 5 bacon 8.0 pig 6 pastrami 3.0 cow 7 honey ham 5.0 pig 8 nova lox 6.0 salmon
#步骤三 # 查找food重复的记录,分组求其平均值 d_rows = df[df['food'].duplicated(keep=False)] print(d_rows) g_items = d_rows.groupby('food').mean() print(g_items) g_items['food'] = g_items.index print(g_items)
food ounces animal 0 bacon 4.0 pig 3 pastrami 6.0 cow 5 bacon 8.0 pig 6 pastrami 3.0 cow ounces food bacon 6.0 pastrami 4.5 ounces food food bacon 6.0 bacon pastrami 4.5 pastrami
#步骤四 # 遍历将重复food的平均值赋值给df for i, row in g_items.iterrows(): df.loc[df.food == row.food, 'ounces'] = row.ounces print(df) df.drop_duplicates(inplace=True) # 删除重复记录 print(df) df.index = range(len(df)) # 重设索引值 print(df)
food ounces animal 0 bacon 6.0 pig 1 pulled pork 3.0 pig 3 pastrami 4.5 cow 4 corned beef 7.5 cow 5 bacon 6.0 pig 6 pastrami 4.5 cow 7 honey ham 5.0 pig 8 nova lox 6.0 salmon food ounces animal 0 bacon 6.0 pig 1 pulled pork 3.0 pig 3 pastrami 4.5 cow 4 corned beef 7.5 cow 7 honey ham 5.0 pig 8 nova lox 6.0 salmon food ounces animal 0 bacon 6.0 pig 1 pulled pork 3.0 pig 2 pastrami 4.5 cow 3 corned beef 7.5 cow 4 honey ham 5.0 pig 5 nova lox 6.0 salmon