
在python的标准库中,专门提供了json库与pickle库来处理这部分
import json
dict1={'name':'wuya','age':22,'address':'xian'}
print u'未序列化前的数据类型为:',type(dict1)
print u'未序列化前的数据:',dict1
#对dict1进行序列化的处理
str1=json.dumps(dict1)
print u'序列化后的数据类型为:',type(str1)
print u'序列化后的数据为:',str1
------------------------------------------------------
未序列化前的数据类型为: <type 'dict'>未序列化前的数据: {'age': 22, 'name': 'wuya', 'address': 'xian'}序列化后的数据类型为: <type 'str'>序列化后的数据为: {"age": 22, "name": "wuya", "address": "xian"}通过如上的代码以及结果可以看到,这就是一个序列化的过程,简单的说就是把python的数据类型转换为json格式的
字符串。下来我们再反序列化,把json格式的字符串解码为python的数据对象,见实现的代码和输出:
import json
dict1={'name':'wuya','age':22,'address':'xian'}
print u'未序列化前的数据类型为:',type(dict1)
print u'未序列化前的数据:',dict1
#对dict1进行序列化的处理
str1=json.dumps(dict1)
print u'序列化后的数据类型为:',type(str1)
print u'序列化后的数据为:',str1
#对str1进行反序列化
dict2=json.loads(str1)
print u'反序列化后的数据类型:',type(dict2)
print u'反序列化后的数据:',dict2
------------------------------------------------------------
未序列化前的数据类型为: <type 'dict'>
未序列化前的数据: {'age': 22, 'name': 'wuya', 'address': 'xian'}
序列化后的数据类型为: <type 'str'>
序列化后的数据为: {"age": 22, "name": "wuya", "address": "xian"}
反序列化后的数据类型: <type 'dict'>
反序列化后的数据: {u'age': 22, u'name': u'wuya', u'address': u'xian'}
-----------------------------------------------------------------------------------
比较特殊的一个
元组的序列化和反序列化
import json
aa=(1,2,3)
tty=json.dumps(aa)
print(tty,type(tty))
pp=json.loads(tty)
print(pp,type(pp))
[1, 2, 3] <class 'str'>
[1, 2, 3] <class 'list'>
元组反序列化之后是一个list
------------------------------------------------------------------------------
下面我们结合requests库,来看返回的json数据,具体代码为:
import json
import requests
r=requests.get('http://wthrcdn.etouch.cn/weather_mini?city=西安')
print r.text,u'数据类型:',type(r.text)
#对数据进行反序列化的操作
dic=json.loads(r.text)
print dic,u'数据类型:',type(dic)
---------------
{"desc":"OK","status":1000,"data":{"wendu":"3","ganmao":"昼夜温差较大,较易发生感冒,请适当增减衣服。体质较弱的朋友请注意防护。","forecast":[{"fengxiang":"东北风","fengli":"微风级","high":"高温 10℃","type":"晴","low":"低温 -2℃","date":"22日星期四"},{"fengxiang":"东北风","fengli":"微风级","high":"高温 8℃","type":"多云","low":"低温 0℃","date":"23日星期五"},{"fengxiang":"东北风","fengli":"微风级","high":"高温 7℃","type":"阴","low":"低温 0℃","date":"24日星期六"},{"fengxiang":"东北风","fengli":"微风级","high":"高温 1℃","type":"雨夹雪","low":"低温 -1℃","date":"25日星期天"},{"fengxiang":"东北风","fengli":"微风级","high":"高温 5℃","type":"多云","low":"低温 1℃","date":"26日星期一"}],"yesterday":{"fl":"微风","fx":"北风","high":"高温 7℃","type":"阴","low":"低温 -1℃","date":"21日星期三"},"aqi":"87","city":"西安"}} 数据类型: <type 'unicode'> {u'status': 1000, u'data': {u'city': u'u897fu5b89', u'yesterday': {u'fx': u'u5317u98ce', u'type': u'u9634', u'high': u'u9ad8u6e29 7u2103', u'low': u'u4f4eu6e29 -1u2103', u'date': u'21u65e5u661fu671fu4e09', u'fl': u'u5faeu98ce'}, u'forecast': [{u'fengxiang': u'u4e1cu5317u98ce', u'high': u'u9ad8u6e29 10u2103', u'fengli': u'u5faeu98ceu7ea7', u'date': u'22u65e5u661fu671fu56db', u'type': u'u6674', u'low': u'u4f4eu6e29 -2u2103'}, {u'fengxiang': u'u4e1cu5317u98ce', u'high': u'u9ad8u6e29 8u2103', u'fengli': u'u5faeu98ceu7ea7', u'date': u'23u65e5u661fu671fu4e94', u'type': u'u591au4e91', u'low': u'u4f4eu6e29 0u2103'}, {u'fengxiang': u'u4e1cu5317u98ce', u'high': u'u9ad8u6e29 7u2103', u'fengli': u'u5faeu98ceu7ea7', u'date': u'24u65e5u661fu671fu516d', u'type': u'u9634', u'low': u'u4f4eu6e29 0u2103'}, {u'fengxiang': u'u4e1cu5317u98ce', u'high': u'u9ad8u6e29 1u2103', u'fengli': u'u5faeu98ceu7ea7', u'date': u'25u65e5u661fu671fu5929', u'type': u'u96e8u5939u96ea', u'low': u'u4f4eu6e29 -1u2103'}, {u'fengxiang': u'u4e1cu5317u98ce', u'high': u'u9ad8u6e29 5u2103', u'fengli': u'u5faeu98ceu7ea7', u'date': u'26u65e5u661fu671fu4e00', u'type': u'u591au4e91', u'low': u'u4f4eu6e29 1u2103'}], u'ganmao': u'u663cu591cu6e29u5deeu8f83u5927uff0cu8f83u6613u53d1u751fu611fu5192uff0cu8bf7u9002u5f53u589eu51cfu8863u670du3002u4f53u8d28u8f83u5f31u7684u670bu53cbu8bf7u6ce8u610fu9632u62a4u3002', u'wendu': u'3', u'aqi': u'87'}, u'desc': u'OK'}
数据类型: <type 'dict'>
事实上,在如上的代码中,我们可以不通过反序列化的操作,代码可以简化为:
import json
import requests
r=requests.get('http://wthrcdn.etouch.cn/weather_mini?city=西安')
print r.json(),u'数据类型为:',type(r.json())
{u'status': 1000, u'data': {u'city': u'u897fu5b89', u'yesterday': {u'fx': u'u5317u98ce', u'type': u'u9634', u'high': u'u9ad8u6e29 7u2103', u'low': u'u4f4eu6e29 -1u2103', u'date': u'21u65e5u661fu671fu4e09', u'fl': u'u5faeu98ce'}, u'forecast': [{u'fengxiang': u'u4e1cu5317u98ce', u'high': u'u9ad8u6e29 10u2103', u'fengli': u'u5faeu98ceu7ea7', u'date': u'22u65e5u661fu671fu56db', u'type': u'u6674', u'low': u'u4f4eu6e29 -2u2103'}, {u'fengxiang': u'u4e1cu5317u98ce', u'high': u'u9ad8u6e29 8u2103', u'fengli': u'u5faeu98ceu7ea7', u'date': u'23u65e5u661fu671fu4e94', u'type': u'u591au4e91', u'low': u'u4f4eu6e29 0u2103'}, {u'fengxiang': u'u4e1cu5317u98ce', u'high': u'u9ad8u6e29 7u2103', u'fengli': u'u5faeu98ceu7ea7', u'date': u'24u65e5u661fu671fu516d', u'type': u'u9634', u'low': u'u4f4eu6e29 0u2103'}, {u'fengxiang': u'u4e1cu5317u98ce', u'high': u'u9ad8u6e29 1u2103', u'fengli': u'u5faeu98ceu7ea7', u'date': u'25u65e5u661fu671fu5929', u'type': u'u96e8u5939u96ea', u'low': u'u4f4eu6e29 -1u2103'}, {u'fengxiang': u'u4e1cu5317u98ce', u'high': u'u9ad8u6e29 5u2103', u'fengli': u'u5faeu98ceu7ea7', u'date': u'26u65e5u661fu671fu4e00', u'type': u'u591au4e91', u'low': u'u4f4eu6e29 1u2103'}], u'ganmao': u'u663cu591cu6e29u5deeu8f83u5927uff0cu8f83u6613u53d1u751fu611fu5192uff0cu8bf7u9002u5f53u589eu51cfu8863u670du3002u4f53u8d28u8f83u5f31u7684u670bu53cbu8bf7u6ce8u610fu9632u62a4u3002', u'wendu': u'3', u'aqi': u'87'}, u'desc': u'OK'} 数据类型为: <type 'dict'>
在实际的工作中,序列化或者反序列化的可能是一个文件的形式,不可能像如上写的那样简单的,下来就来实现这部分,把文件内容
进行序列化和反序列化,先来看序列化的代码:
import json
list1=['selenium','appium','android','ios','uiautomator']
#把list1先序列化,再写入到一个文件中
print json.dump(list1,open('c:/log.log','w'))
print u'文件内容为:'
r=open('c:/log.log','r+')
print r.read()
文件内容为:
["selenium", "appium", "android", "ios", "uiautomator"]
下面我们来反序列化,也就是先读取文件里面的内容,再进行反序列化,见实现的代码:
import json
list1=['selenium','appium','android','ios','uiautomator']
#把list1先序列化,再写入到一个文件中
print json.dump(list1,open('c:/log.log','w'))
print u'文件内容为:'
r=open('c:/log.log','r+')
print r.read()
#先读取文件内容,再进行反序列化
res=json.load(open('c:/log.log','r+'))
print res,u'数据类型:',type(res)
----------------------------------------------------------------------
["selenium", "appium", "android", "ios", "uiautomator"]
[u'selenium', u'appium', u'android', u'ios', u'uiautomator'] 数据类型: <type 'list'>
在实际项目中
1、接口在发请求时,参数是字符串类型,所以一般需要字典类型或者其他类型-先序列化未字符串类型
2、接口返回的数据可能是Unicode 编码,需要转化为字符串类型, 在使用反序列化-变成字典类型或者其他类型---然后在取值
文件序列化反序列化
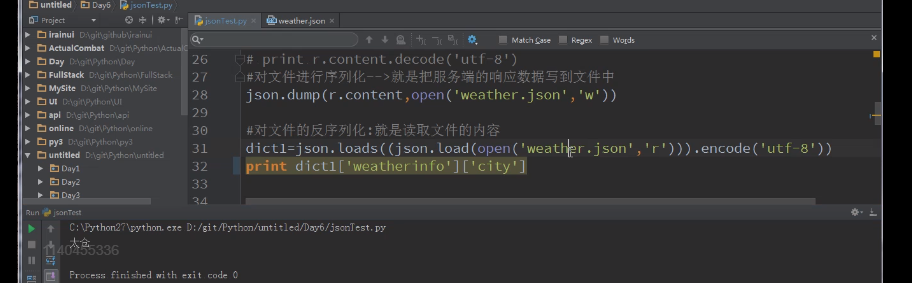
在这个案例中,并不是所有的项目
1、文件反序列化后,是Unicode
2、进行编码,把Unicode类型转为str类型
3、然后使用反序列化,把str类型转化为字典类型