背景:最近在测试有关占比,有些算法使用笨办法感觉很浪费时间,所以网上试着找了一个类似的函数来计算,提高效率。
前提描述:存在一张表:label_for_drug_insu_admdvs,其中drug_type为药品分类:1,2,3,4分别代表西药中成药、中药、自制药、民族药。drug_type为性别。
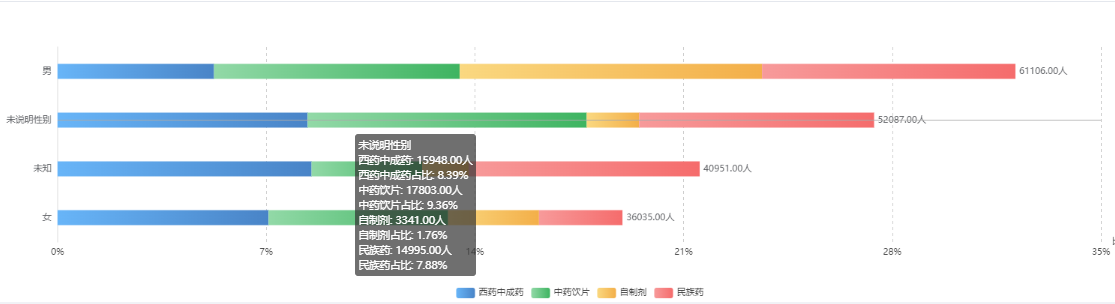
需要的结果:现在需要展示出各种性别类型的药品分类金额及占比、总人数。其中每个性别的药品占比=每个性别的药品人数/所有性别总人数。具体实现效果见截图
sql实现方法:
SELECT
gend,
drug_type,
drug_psn_cnt,
SUM (drug_psn_cnt) OVER ( partition by gend order by drug_type) as "按性别的药品分类连续求和" ,--"按性别的药品分类连续求和",
sum(drug_psn_cnt) over (partition by gend) as "性别统计总和",-- 性别统计总和,同一性别总和不变。
--各药品占所在性别占比
round(drug_psn_cnt/round( sum(drug_psn_cnt) over (partition by gend),4)*100,4)||'%' "各个药品分类占比",
SUM (drug_psn_cnt) OVER () as "所有性别人数总和", --"所有性别人数总和" ,
round(drug_psn_cnt/round(SUM(drug_psn_cnt)OVER(),4)*100,4)||'%' "总份额" --总份额
FROM
drug_gend
WHERE
drug_type IN ('1', '2', '3', '4')
and admdvs LIKE '44%'

总结:sum() over()函数 ,over()不能单独使用,要和sum()一起使用。
over(partition by columnname1 order by columnname2)
含义,按columname1指定的字段进行分组排序,或者说按字段columnname1的值进行分组排序。
SUM (drug_psn_cnt) OVER ( partition by gend order by drug_type) as "按性别的药品分类连续求和" ,--"按性别的药品分类连续求和",
sum(drug_psn_cnt) over (partition by gend) as "性别统计总和",-- 性别统计总和,同一性别总和不变。
SUM (drug_psn_cnt) OVER () as "所有性别人数总和", --"所有性别人数总和" ,
round(drug_psn_cnt/round( sum(drug_psn_cnt) over (partition by gend),4)*100,4)||'%' "各个药品分类占比",
SUM (drug_psn_cnt) OVER () as "所有性别人数总和", --"所有性别人数总和" ,