


![]()

鸢尾花数据集的分类操作

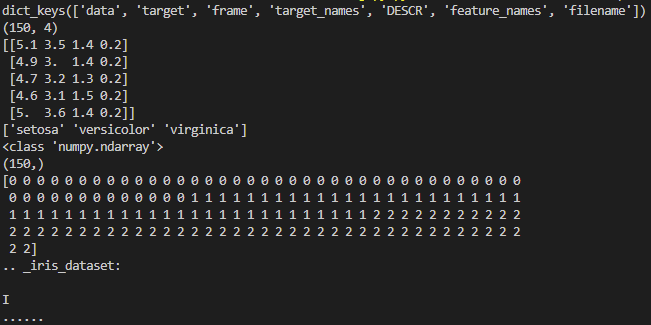
from sklearn.datasets import load_iris iris_dataset=load_iris() print(iris_dataset.keys()) print(iris_dataset['data'].shape)#查看数据的结构 print(iris_dataset['data'][:5])#查看前五条数据 #查看分类信息 print(iris_dataset['target_names'])#标记名 print(type(iris_dataset['target']))#标记类型 print(iris_dataset['target'].shape)#标记维度 print(iris_dataset['target'])#标记值 print(iris_dataset['DESCR'][:20]+" ......")#查看数据集的简介的前20个字符

训练集可以认为是测试题 带答案
测试集可以认为是考试卷

train_data 是要划分的样本特征数据
train_target 要划分的样本结果
test_size 测试集占总的百分比
random_state 随机种子编号 若缺省则每次不同
鸢尾花数据集拆分
from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split iris_dataset=load_iris() X_train,X_test,y_train,y_test=train_test_split(iris_dataset['data'],iris_dataset['target'],random_state=2) print("X_train",X_train) print("y_train",y_train) print("X_test",X_test) print("y_test",y_test) print("X_train shape: {}".format(X_train.shape)) print("X_test shape: {}".format(X_test.shape))
部分结果
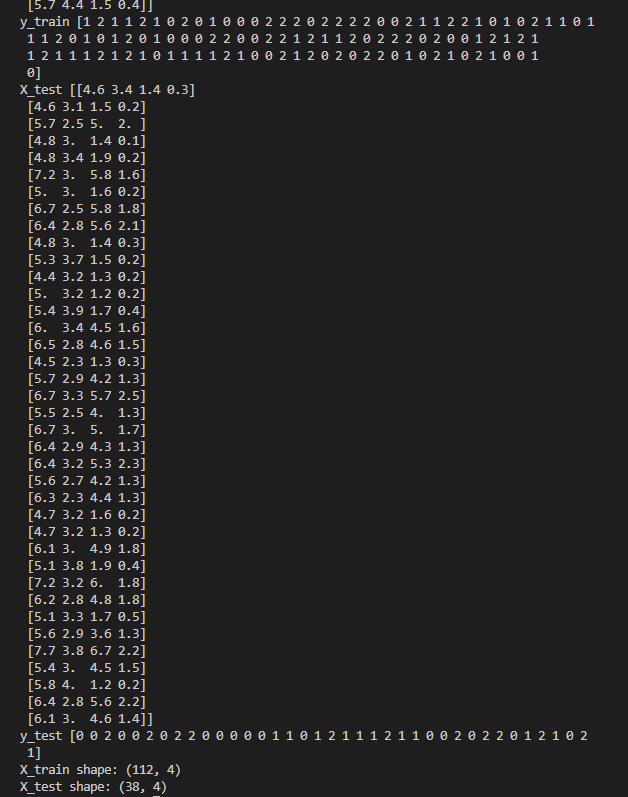
可以看到数据集被拆分成训练集和测试集两部分